Faster Spotfire BI via CoSort
Introduction: As with multiple BI platforms discussed throughout this section of the IRI blog site, this article analyzes the relative data preparation performance (and benefit) of IRI CoSort with Tibco Spotfire when ‘big data’ sources are involved.
Business intelligence (BI) is a technology-driven process for analyzing data and boosting business performance by helping executives and end users make the decisions that will optimize internal business processes. BI and analytic systems can help organizations identify market trends and spot problems that need to be addressed.
These platforms encompass a variety of tools, applications, and methodologies that enable organizations to collect data from internal systems and external sources; then prepare it for analysis. Some of the large BI vendors are IBM, Microsoft, Oracle, and SAP, while newer mid-size analytic vendors are QlikView, R, Splunk, Spotfire, and Tableau.
Spotfire can extract data from multiple sources1 and render it in user-friendly charts and graphs. It is particularly useful for data intensive life science researchers and financial organizations who require simple-to-build dashboards. Spotfire features in-memory visualization processing, and sophisticated predictive analytics.
Spotfire can also obtain query results, but cannot chart data until it has been located, acquired, and otherwise prepared for visualization. Data acquisition and preparation is where IRI CoSort provides value to Spotfire users. CoSort is a multi-purpose, big data manipulation and management package that speeds, performs, and combines:
- Data integration (ETL) of structured, semi-, and unstructured sources
- Legacy data-type, file-format, and database migrations
- Data masking, including encryption, pseudonymization, and redaction
- Reporting, with built-in 2D features, or data franchising for BI tools like Spotfire
CoSort can extract and join data from multiple sources and provide it to various targets. Without a DB engine, appliances, or Hadoop, CoSort — and its SortCL program in particular — franchises (a/k/a munges, subsets, wrangles) or otherwise prepares massive amounts of raw data for downstream applications.
By way of example, and to demonstrate the relative performance in preparing data for Spotfire visualizations, I processed the raw data for Spotfire visualization in both Spotfire and CoSort/SortCL, and timed them:
Data Preparation in Spotfire
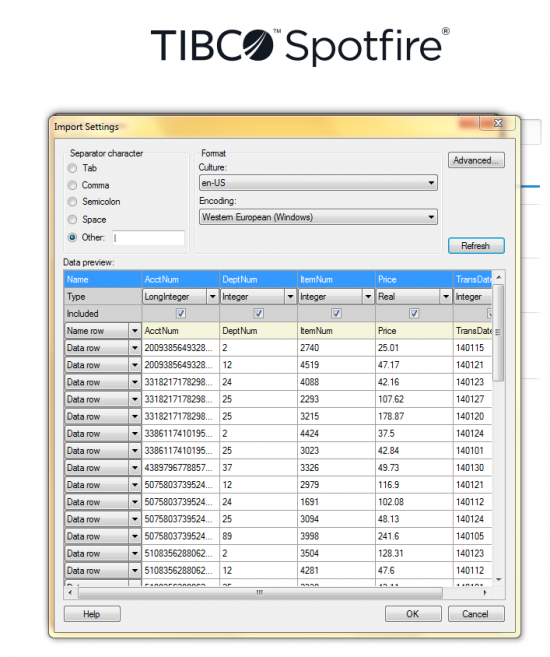
The first step in Spotfire was to import data by selecting the option to Add Data Tables or Open File. In this case, a flat-file called Transactions.csv:
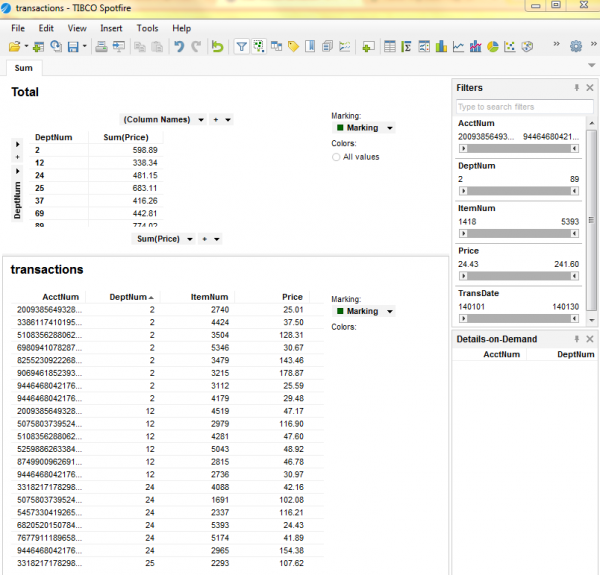
 Once I imported the file, I sorted it by DeptNum, and then performed an aggregation using a “cross table” in a separate step. A cross table consists of columns and rows. Also known as a pivot table or a multi-dimensional table, it can structure, summarize, and display aggregate data.
Once I imported the file, I sorted it by DeptNum, and then performed an aggregation using a “cross table” in a separate step. A cross table consists of columns and rows. Also known as a pivot table or a multi-dimensional table, it can structure, summarize, and display aggregate data.
Cross tables can also determine if there is a relation between the row variable and the column variable. The cross table (Total) displays the GrandTotal for price by Department Number. Filters are used to cull the data, as shown in this screenshot:
Data Preparation in CoSort/SortCL
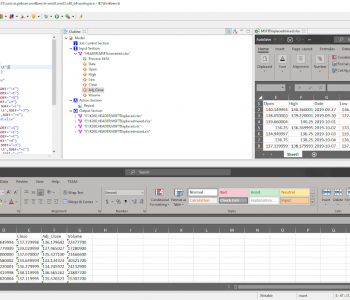
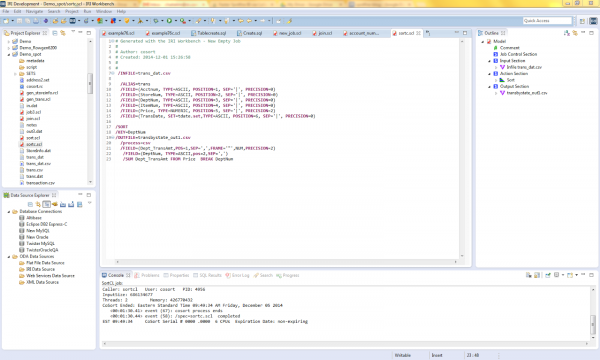
CoSort provides multiple ways for end-users to acquire and stage data. The two most common are a SortCL program script created in a text editor and run from the command line, or the same job built automatically in the free IRI Workbench GUI, built on Eclipse™. In this case, I used a wizard in the IRI Workbench to create, run, and manage my data connections, metadata, and job script.
My SortCL job opens transactions.dat, sorts it by DeptNum, and sums the Price values in each DeptNum group. The output is a CSV file that any BI tool, including Spotfire, can readily ingest. This screenshot shows my SortCL script:
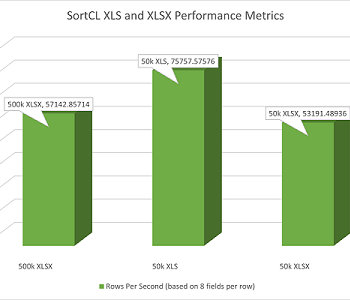
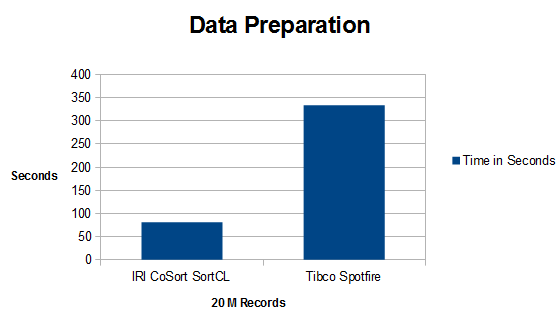
The obtained output in both processes was equal, but the time taken to achieve the results was not. Given 20 million rows of data, the IRI CoSort SortCL program took 1m 21s to prepare the data, while SpotFire required 5m 34s, more than 4 times longer:
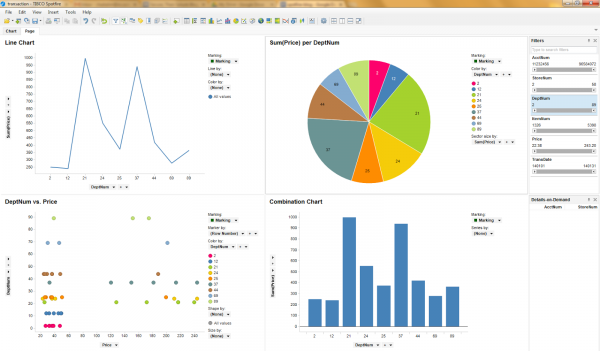
Either way, the raw data was ultimately distilled into the same subset ready for graphical representation (DeptNum vs. Price) in Spotfire:
1. Spotfire currently has native data connectors to Apache Hadoop/Hive, Cloudera Hive and Impala, Composite Information Server, Hortonworks data platform, HP Veritica, IBM Netezza, MS Analysis Services, MS SQL Server, MySQL, Oracle and Oracle Exadata, Oracle Essbase, Pivotal Greenplum, Pivotal HAWQ, PostgreSQL, SAP HANA, SAP NetWeaver Business Warehouse, Teradata, Teradata Aster.↩