Voracity Data Munging and Masking App for Splunk
In Q3’19, IRI created a new, free app for Splunk Enterprise and Enterprise Security users that seamlessly indexes data from any Voracity platform data wrangling or protection job. Read More
In Q3’19, IRI created a new, free app for Splunk Enterprise and Enterprise Security users that seamlessly indexes data from any Voracity platform data wrangling or protection job. Read More
KNIME is a leading open source analytic and visualization tool for data scientists. Wrangling raw data for KNIME projects is usually done via their intermediate file node, database connectors, or other extensions like Spark. Read More

Article 17 of the General Data Protection Regulation (GDPR) stipulates the need to minimize aging data through deletion, as well as the ad hoc Right to Erasure, often referred to as the Right to be Forgotten. Read More
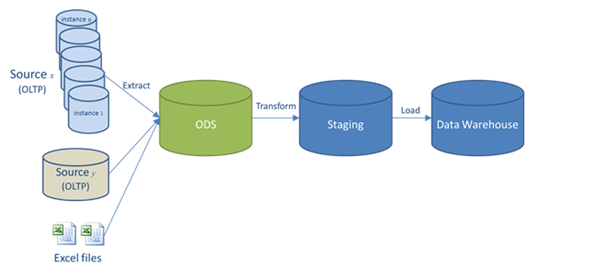
An operational data store (or “ODS”) is another paradigm for integrating enterprise data that is relatively simpler than a data warehouse (DW). Read More

“Have you stopped speeding?” You could probably object to a leading question like this in court, but what happens when an important question with only a yes or no answer is solicited on a mandatory form, and the response becomes part of an actionable database record? Read More
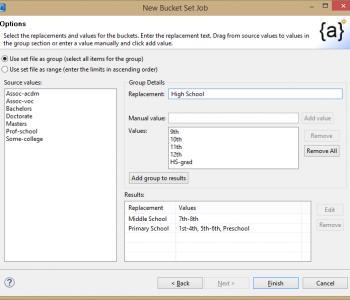
Quasi-identifiers, or indirect identifiers, are personal attributes that are true about, but not necessarily unique, to an individual. Examples are one’s age or date of birth, race, salary, educational attainment, occupation, marital status and zip code. Read More
This is part 4 of a 4-part series on Production Analytics. Processing on Par with Information [Part 1] Data Processing Drives Efficiency [Part 2] Processing Real World Data [Part 3]
In this final article of the series covering the Production Analytic Platform paradigm, we look at data virtualization—a key requirement in today’s multi-source, data-overloaded world. Read More

This is part 3 of a 4-part series on Production Analytics. Processing on Par with Information [Part 1] Data Processing Drives Efficiency [Part 2] Unifying the Worlds of Information and Processing [Part 4]
The inclusion of full function data processing in the Production Analytic Platform simplifies the task of gathering data from external sources such as the Internet of Things and clickstream data that requires both intensive exploratory modeling as well as high-speed application and maintenance of those models on real-time and streaming data. Read More
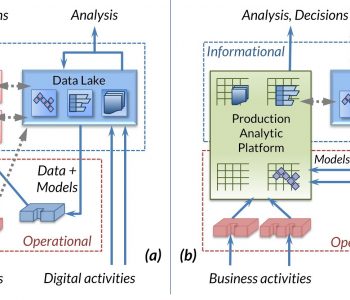
This is the first of a four-part series of blog articles examining the inherent tradeoffs between data processing and information storage and presentation within traditional ETL paradigms — from the ODS to the data lake. Read More
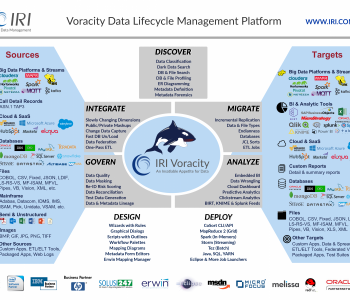
This is part 2 of a 4-part series on Production Analytics. Processing on Par with Information [Part 1] Processing Real World Data [Part 3] Unifying the Worlds of Information and Processing [Part 4]
Considering data processing as a central component of data management and on a par with databases offers new insights on how to improve overall efficiency and return on investment in traditional data warehouses. Read More
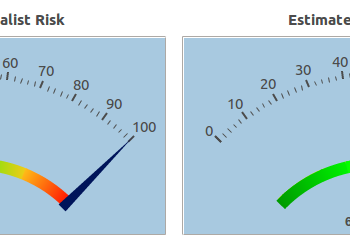
One of the biggest concerns with releasing a dataset is the risk that a potential attacker can identify the owners of particular records. Even though masking or removing unique identifiers, like names and Social Security Numbers, can reduce that risk substantially, it may still not be enough. Read More