Consistent, Cross-Table Data Pseudonymization
Applying a Pseudonym Rule in the IRI Workbench GUI for FieldShield or Voracity
To create pseudonym values that will be consistent across tables — and keep up with changing data in those tables — the IRI Workbench GUI for FieldShield and Voracity now includes a Flow Diagram Palette item for Pseudonymization. Adding this item creates a centralized pseudonym file (and optionally, a restore set) by shuffling all the chosen source column values that exist when the flow executes.
Previously, you had to use the wizard to create a new pseudo set file every time you made changes to your data. Now, the core set file will be current (since it is made seconds before being applied) and also contains no duplicates. Therefore, any field with that set file applied to it will be replaced with the same value. For instance, John Smith is always replaced by Mike Jones.
Sample Sources
Per the image below, two tables are being used (CHIEFS and CUSTOMERS_FLOW) as the sources of my pseudo set file. The CHIEFS table contains information about US Presidents, while the CUSTOMERS_FLOW table contains information on customers. Although this is not necessary, the set file will be applied back to these two tables.
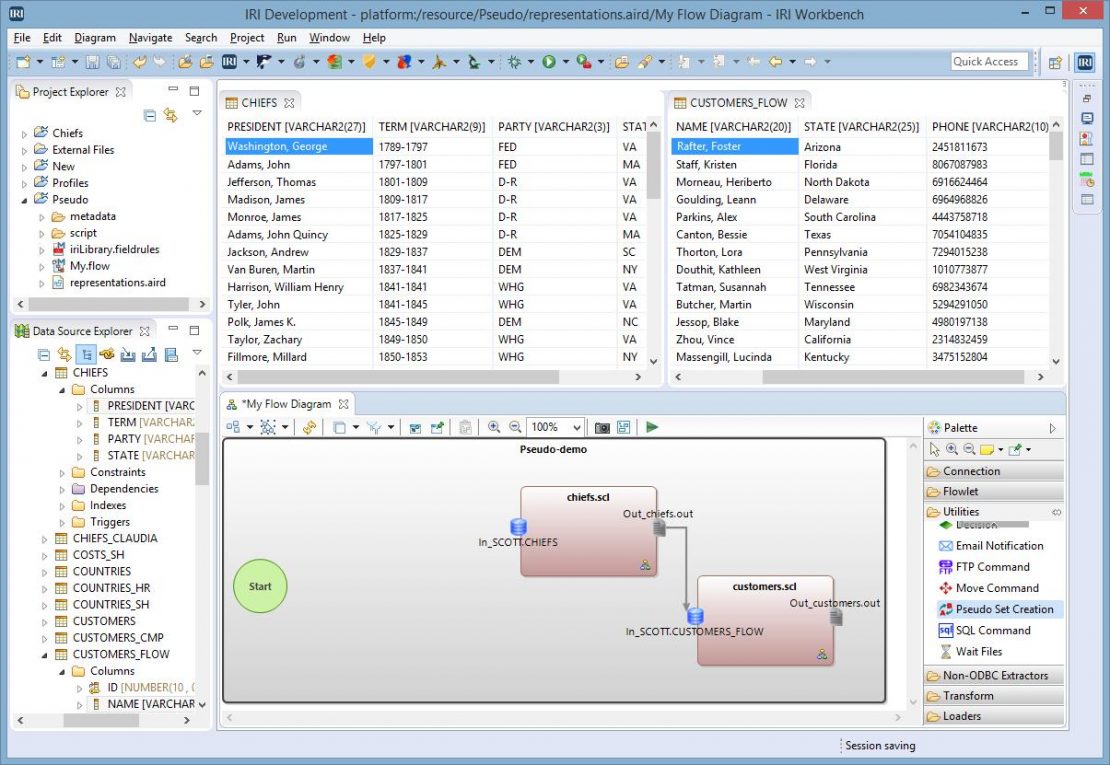
The pseudo flow block will be added to the flow diagram. The output of the two Transform Mapping Blocks (TMB) were designated as flat files to ease the display of results.
Define the Pseudo Set
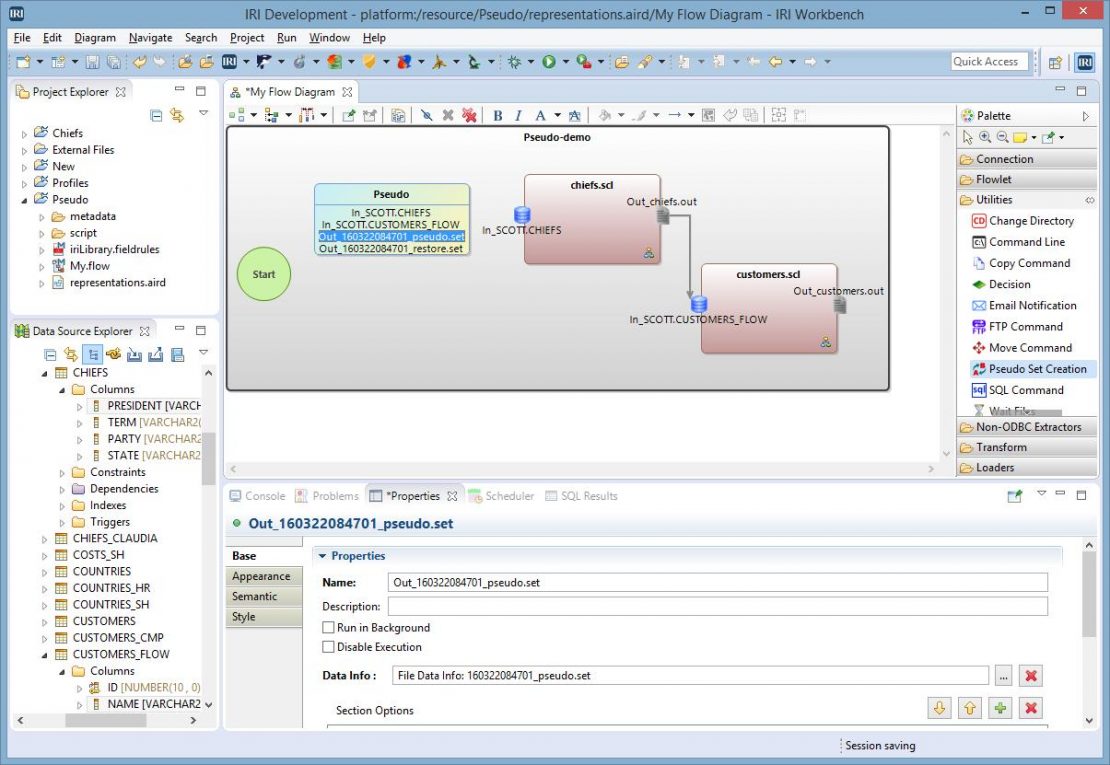
To use the Pseudo block, drag it from the Utilities section of the palette and place it before your TMBs. This allows you to use that new set file in any following blocks. Upon dropping the Pseudo block, a wizard will start by asking you if you also want to create a restore set. In this particular example, the answer is yes.
The wizard page allows you to select the tables and columns that you want to use for your set file. You can select any number of columns from any number of tables in a single database. In this case, a field called PRESIDENT from the CHIEFS table is used, along with the field NAME from CUSTOMERS_FLOW.

After clicking finish, a Pseudo block is displayed in the flow diagram showing the inputs and outputs. Select any of those items in the block to see their details in the properties screen. You can edit the block by double-clicking it, and changing the info using the same screen as above.
Apply the Pseudo Set
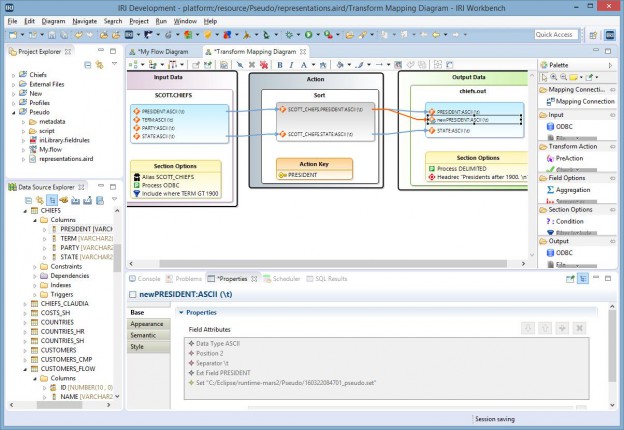
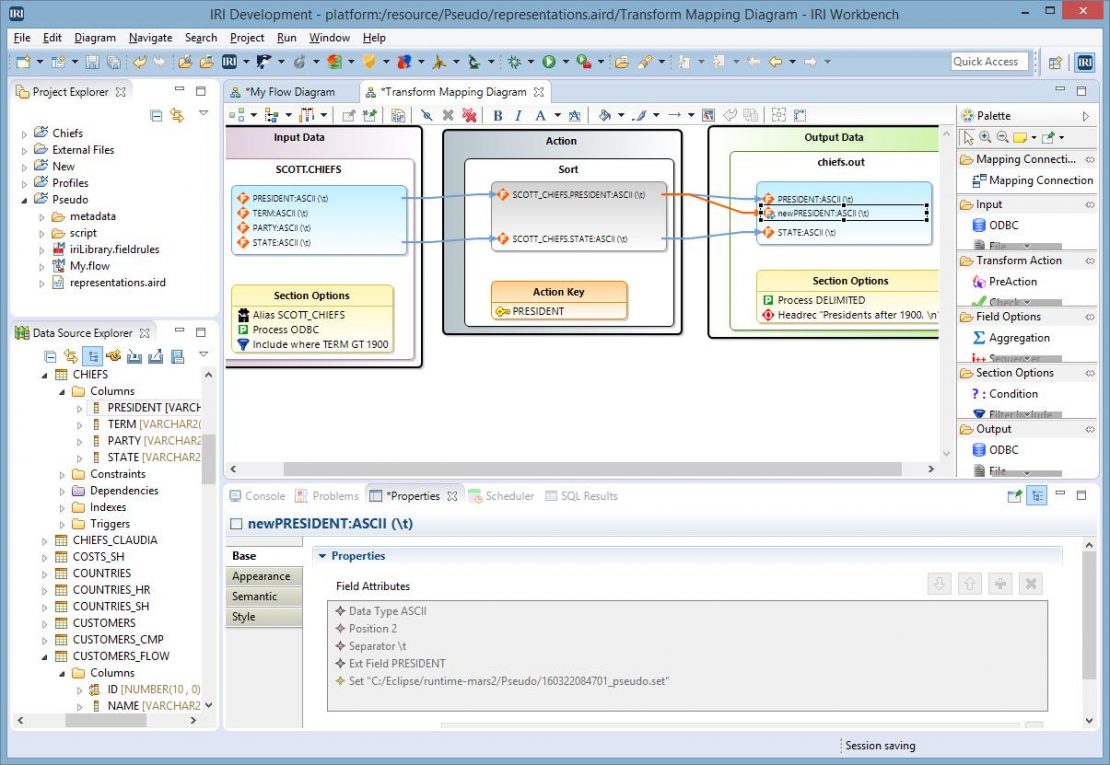
You will need to copy the file name of the set you will be using since it does not yet exist (but is merely planned at this point). Open the TMBs of the fields that will use the set file. When you double-click on the field you want to pseudonymize, then the Target Field (column) Editor dialog appears.
As you see in the screen below, the work is being done in the “Value” tab since a pseudonym will modify the output column values. This tab is used, as opposed to the Pseudonymize and Restore tab next to it, because that tab is used for static data, not dynamic.
In the Transformation Type combo box, select “Set: File” to specify that a lookup (pseudonym) value will be used. Using the “Browse” button, navigate to the project folder containing your flow. Then, paste the name of the set file into the File name box and click Finish. Using the “Look-up Value” button, add the field where you will be replacing values.
A default value was also added in case a replacement value is not found. This doesn’t apply to the current data, since the source of the set and the source of the changed value are the same. However, it is important when using a set that was populated from another source.
It is also important to change the Field Name to distinguish it from the original field. This avoids confusion between the original and derived values, and supports data lineage efforts by exposing and labeling the changes in values. Repeat this renaming procedure for all the fields being pseudonymized.
The newPRESIDENT field now has a different colored mapping connection and a new icon to show it is a derived field. You can also see the set file in the Field Attributes section. On a side-note, the original PRESIDENT field was left there, and any unnecessary fields were removed to better show the replacement output.
Run the Job
Close the TMB and add connections between the Start block, Pseudo block, and TMBs so that all these blocks are executed. When you are ready to execute the flow, click the white background of the Flow diagram, select IRI Diagram Actions, and Export Flow Component. Enter information on location, name, and Platform on this screen.
Clicking Finish will create the scripts and batch file (when using Windows). You can then run the batch file to pseudonymize the PRESIDENT and NAME fields to produce the outputs below.

The pseudo set file is shown at the top and indicates that any field with the value of “Bush, George H.W.” will be replaced with “Wilson, Woodrow” and “Butcher, Martin” replaced with “Dobos, Cristina.” These replacement values are seen in the side-by-side screens comparing the two files.
In the future, you can simply re-export and run the batch file each time your data changes, without having to further modify the flow file.