Can You Scan, Analyze, and Secure Your Data This Easily?
To mine big data, you must smelt it first. Hadoop distributions and specialty software cannot acquire, classify, or transform all the data you need, efficiently mash it up or format it, nor properly steward it (e.g., validate, cleanse, mask, audit). The IRI Voracity platform -- powered by IRI CoSort or Hadoop big data manipulation engines -- can. Voracity combines data discovery, integration, migration, governance, and analytics all in one familiar pane of glass, built on Eclipse™.
Package, Protect & Provision
Use Voracity to integrate, enrich, and transform raw data sources in HDFS or your normal Linux, Unix or Windows file system. Mask, encrypt, pseudonymize, de-ID, hash, tokenize, etc. data as you transform and provide it. Bulk load DBs with pre-sorted data, create replicas and federated views, prepare data for BI/analytic tools, generate test data, design customized statistical reports, or feed BIRT, R, KNIME or Splunk in memory.


All the Power You Need
Choose between multi-threaded file system processing in the proven IRI CoSort engine, or run the same jobs in MR2, Spark, Spark Stream, Storm, or Tez in HDFS. Manipulate big data in those engines on premise or in the cloud using the same Eclipse™ job design and managed metadata infrastructure.
Different Kinds of Data
Voracity users are working with the whole world of data big and small. That means sources and targets which are in structured, semi-structured, and unstructured formats in files and databases that reside on-premise or in the cloud. Use Voracity to munge and mine all your data for insight, and to discover, mask, and cleanse it for reliability and compliance.
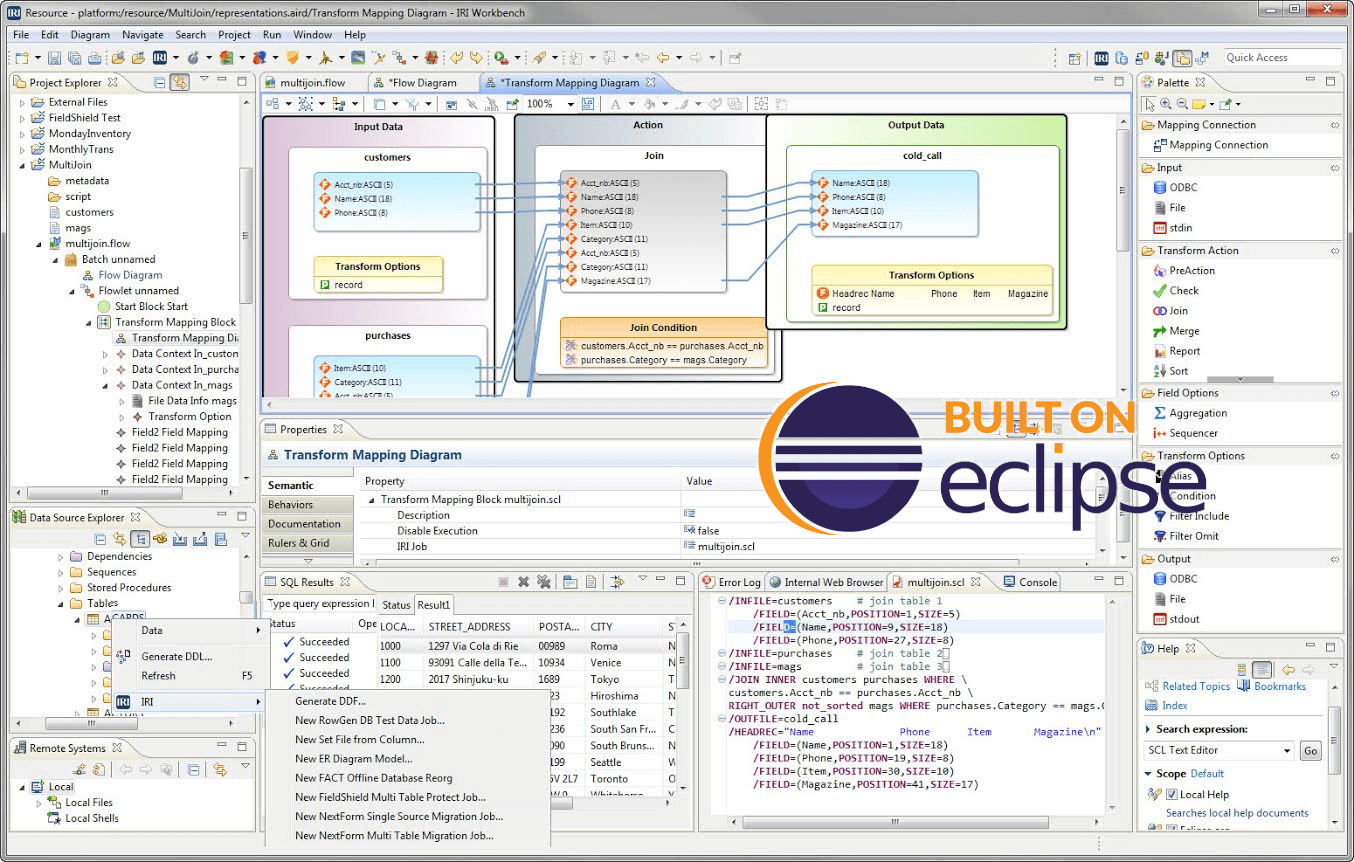
One Pane of Glass
Build, run, and manage your data discovery, integration, migration, governance, and analytics jobs in your choice of re-entrant design modes ... all in the same, free, graphical Eclipse™ IDE for Voracity, IRI Workbench. Share, version-control, secure, and run the jobs from the GUI, batch scripts, applications, cloud platforms, or Hadoop for more speed and scalability.
Surprisingly Affordable
Your ability to process big data no longer requires a big budget for hardware, software, or an army of geeks. IRI's one-stop Voracity data management platform can rapidly process huge ranges and volumes of private and public data ... all at low subscription or perpetual uses prices that SMB and cost-conscious enterprise CFOs prefer.

For more than forty years, IRI has been the proven production performer for preparing and presenting massive, multiple data sources across industries, geographies, and Unix/Windows platforms. Find out why you may only need:
- one affordable product, the IRI Voracity platform to discover, integrate, migrate, govern, and analyze data, all in:
- one simple place, a free Eclipse GUI supporting a simple 4GL, and,
- one I/O pass, combining data transformation, protection, and reporting.
Here's what you can do with Voracity:
Big Data Packaging - integrate (search, acquire, join, etc.), enrich (clean, recast, remap, calc, etc.), and transform (filter, sort, aggregate, etc.) in HDFS or your file system.
Big Data Protection - mask, encrypt, pseudonymize, de-ID, hash, tokenize, etc. data as you transform and provide it.
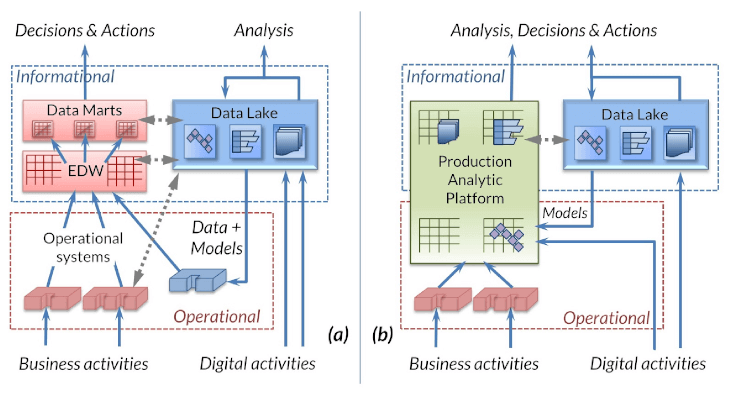
Big Data Provisioning - bulk load with pre-sorted data, create replicas and federated views, prepare (blend, munge) data for BI/analytic tools, write report, feed BIRT or index Splunk directly, or create big test data. Data Warehouse expert Barry Devlin calls Voracity a Production Analytic Platform ... learn why.
Voracity and all constituent IRI products all use the same self-documenting 4GL program from IRI CoSort called SortCL for data definition, manipulation, masking, and reporting.
Design and manage your jobs in your choice of UIs in the same pane of glass. Share, version-control, secure, and run the jobs in Eclipse, or build them into batch scripts, applications, or distributed computing environments like Hadoop for even more speed and scalability.
Browse this section and its links for more details, see who recognizes Voracity as a big data leader here, and request a live demo or free trial here.
Did You Know?
- Voracity can use CoSort or Hadoop engines interchangeably, but that CoSort long pre-dates Hadoop in big data processing? In fact, IRI has used the term "big data" since 2004, across CoSort deployments in telco CDR data warehousing projects on either multi-core or distributed hardware, and long before that with other industry (banking and government) transaction files.
- CoSort, typically used for data transformation, staging, and reporting, can also do what its spin-offs do: i.e., data migration (IRI NextForm), data masking (IRI FieldShield), and test data generation (IRI RowGen).
- IRI Voracity uses the same metadata and Eclipse™ GUI (IRI Workbench) as CoSort and its spin-offs, but also lets you design and schedule jobs with state-of-the-art ETL workflow and built-in automation tools.
- Voracity users in IRI Workbench can view their HDFS files and contents, transfer data to and from HDFS, and auto-convert their transformation and masking job scripts (and batch flows). Execution, in the file system or in HDFS, can be driven on-demand or scheduled in the same GUI where you design and manage your jobs and metadata.