Processing Live Data Feeds in Voracity
This article demonstrates processing a web-based data source in the IRI Voracity data management platform. Static and streaming data defined in URLs — including flat files in formats like CSV or through FTP/S, HTTP/S, HDFS, Kafka, MQTT, and MongoDB — are supported by the default data processing engine in Voracity, CoSort Version 10.
Voracity is a data management platform and solution stack for data discovery, integration, migration, governance and analytics use cases. It was designed as a shared data marshalling area in Eclipse for BI/DW architects and data scientists, IT and data security managers, as well as DBAs and application developers.
Data manipulations in Voracity are powered by IRI CoSort or interchangeable Hadoop engines. All Voracity jobs including ETL-diagrammed stream integration jobs are designed, modified and managed in IRI Workbench, a single pane of glass built on Eclipse. My project co-exists there with other Voracity data management and Eclipse-supported activities.
Live-Feed Processing
The main idea behind the processing of live-feed, or streaming, data is to enable data integration and analysis and actions within real-world deadlines of minutes or even milliseconds. Because of the immediacy of real-time analytics, stream data processing can provide advantages over other analytic methods, including:
- Sharing information in the transparent form of dashboards
- Monitoring custom behavior
- Effective decision-making mechanism
- Immediate changes or fixes whenever necessary
Our Initial Project
This demo began as a search for a live data source on the internet that updates in real time. What we found was data that updated every time the page refreshed. In this case, it was a traffic sensor feed from the New York City Department of Transportation (NYC DOT), which updates speeds and travel times along certain routes.
We first used IRI Workbench to open the LinkSpeedQuery.txt file. We used the new Sort Job Wizard to discover and define the metadata for that file, define a new sort key, and map the data to a new target.
A Few Live Data Feed Processing Examples
When we imported the LinkSpeedQuery.txt file from the URL: http://207.251.86.229/nyc-links-cams/LinkSpeedQuery.txt, our job arranged the data by ID, speed, travel time, status, data as of date, as well as the link id and points columns. Values in the file use a mix of ASCII and numeric data types
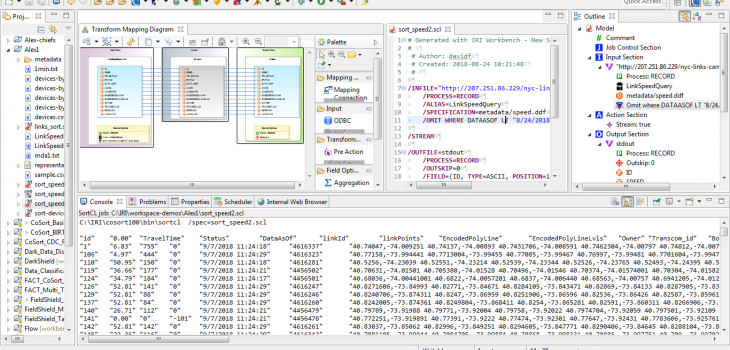
One of the ways I was able to process the live source was to send the job output directly to the console. Figure 1-1, shows our job, “sort_speed2.scl.” When the job runs, the console only displays four lines of data because we used an /INCOLLECT statement to limit the number of rows accepted from the source.
Figure 1-1: Code from sort_speed2.scl, with output sent directly to the console. The transform mapping diagram from sort_speed2.scl is also displayed.
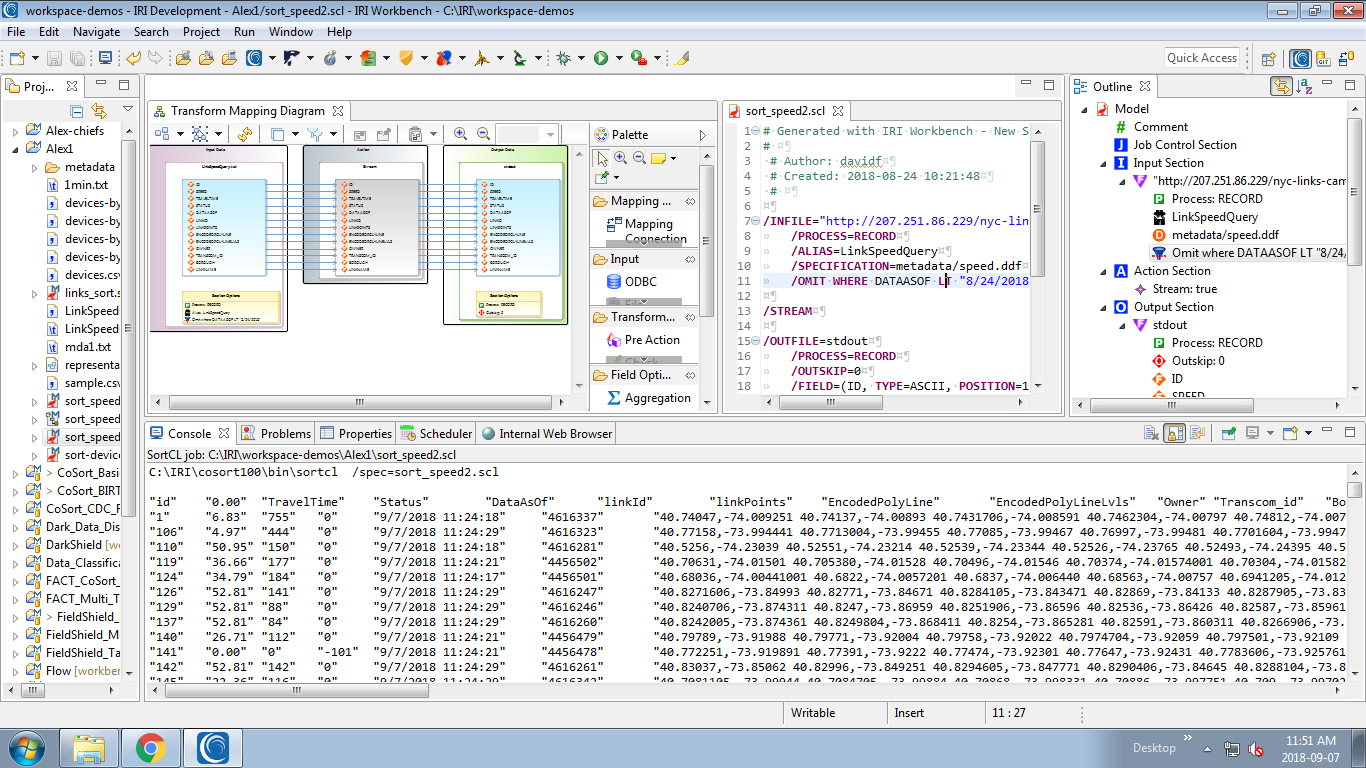
Figure 1-2: sort_speed2.scl, without the /INCOLLECT filter
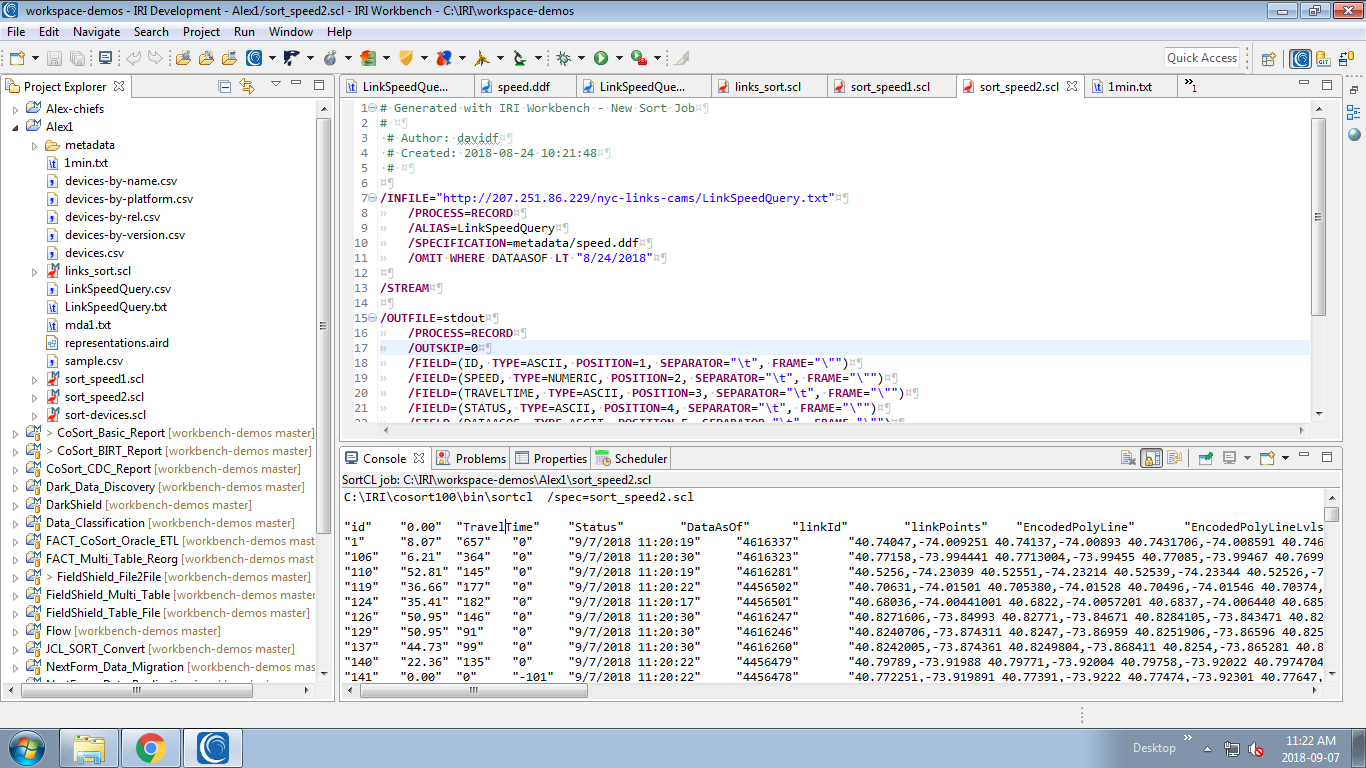
A small modification of our job sends output to a file; i.e. a persistent target.
Figure 1-3 LinkSpeedQuery.txt
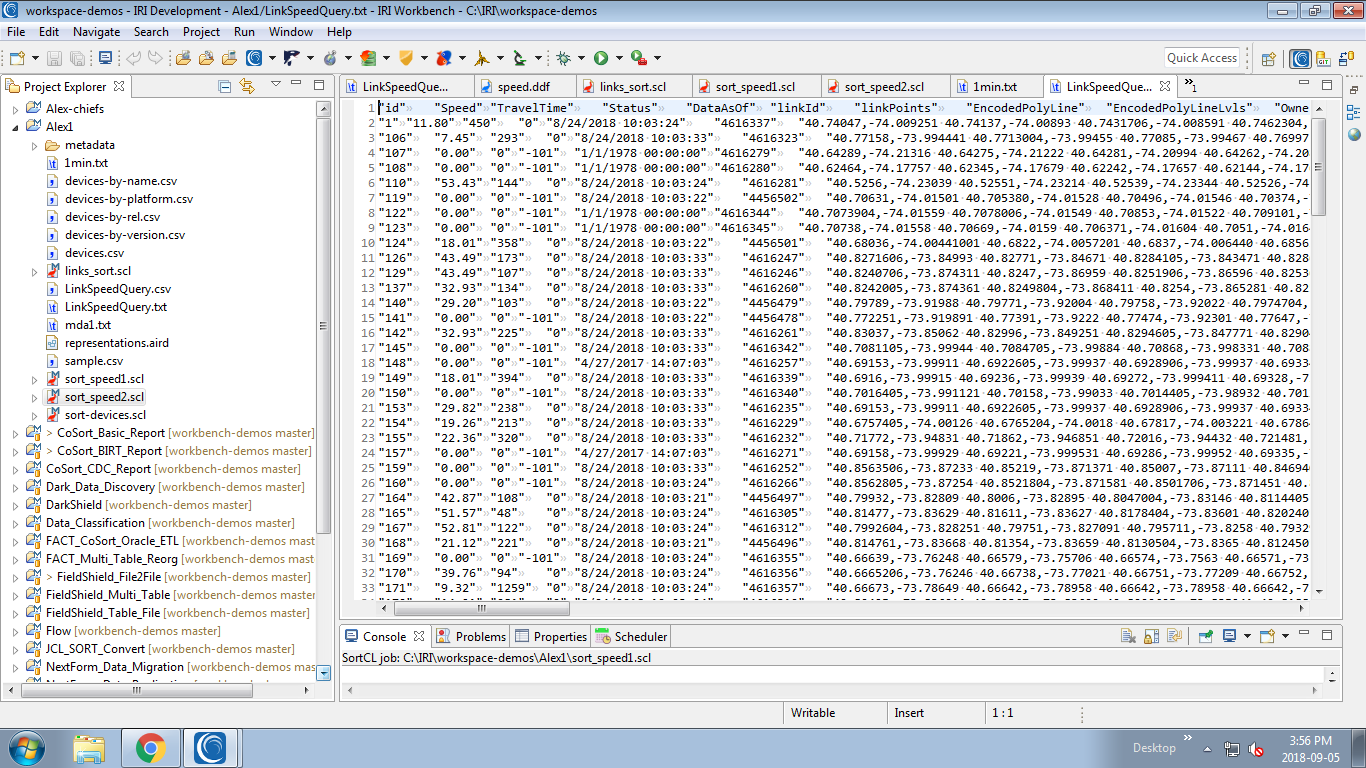
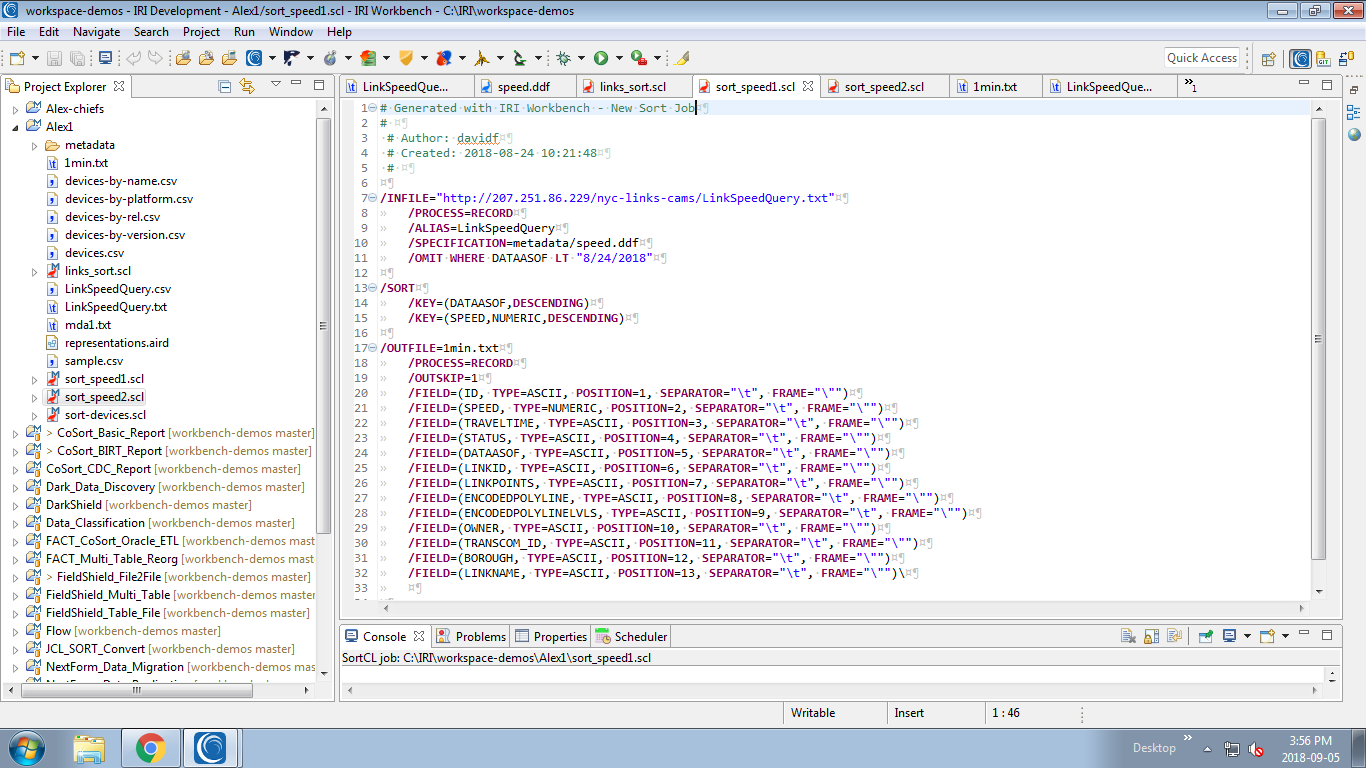
In this job, the output file is written into the same directory as the .scl (job scrip) file. The data was sorted by date and speed.
Figure 1-4: sort_speed1.scl: maps the data to the file 1min.txt
These are very basic examples of what is possible in terms of live-feed, or at least internet-fed data processing in Voracity. Other possibilities include data streaming in through pipes or procedures, or message brokers, per this video demonstration.










