
Data Class Validation in IRI Workbench
Abstract: This is the first of two articles on data class validation in the IRI Workbench graphical IDE for the IRI DarkShield, FieldShield and CellShield EE data masking tools. Read More
Abstract: This is the first of two articles on data class validation in the IRI Workbench graphical IDE for the IRI DarkShield, FieldShield and CellShield EE data masking tools. Read More
IRI Workbench users can connect to and manipulate the data in the underlying database in Salesforce using the JDBC and ODBC drivers from CData or Progress Software. Read More
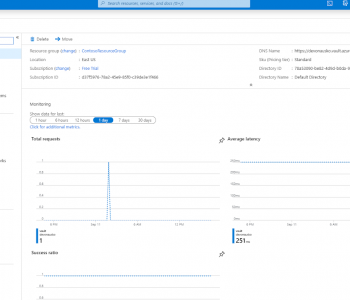
Abstract: This article covers Azure Key Vault encryption key management as part of data encryption best practices. It explains how to use Azure Key Vault and how to perform secure passphrase storage in Azure for encryption and decryption in the IRI FieldShield data masking tool. Read More
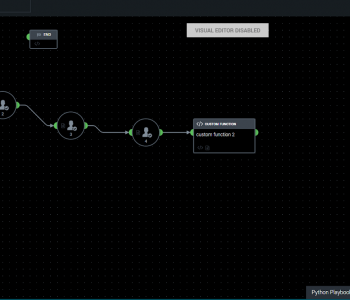
Splunk Phantom is an orchestration, automation, and response technology for running “Playbooks” to respond to various conditions. Phantom connects to Splunk Enterprise using the Phantom App for Splunk, so that actions can be taken on knowledge derived from data indexed in Splunk. Read More

Article 17 of the General Data Protection Regulation (GDPR) stipulates the need to minimize aging data through deletion, as well as the ad hoc Right to Erasure, often referred to as the Right to be Forgotten. Read More
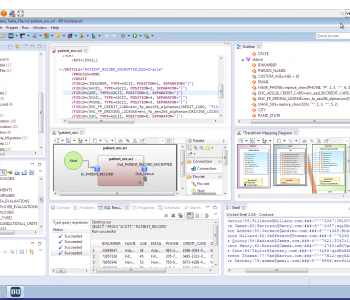
Usually static data masking is performed on production data at rest so it is stored safely, or when replicated to non-production environments for testing or development purposes. Read More
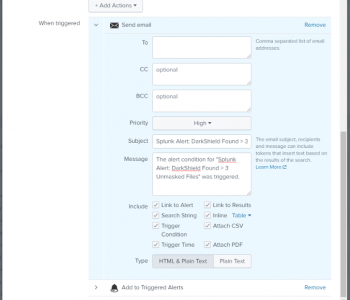
The Splunk Adaptive Response Framework (ARF) included with Splunk Enterprise Security (ES) allows actions to be taken in response to data. This is done by creating an alert that triggers when a certain search result condition is received in the Splunk ES Search and Reporting app. Read More
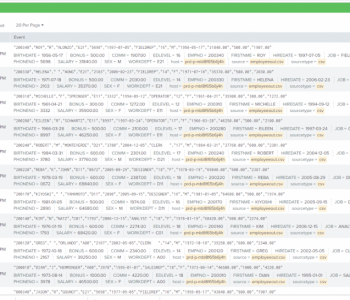
Production or test data targets, as well as the operational log data, created by SortCL-compatible data manipulation or generation jobs in the IRI Voracity data management platform and its included tools (IRI CoSort, NextForm, RowGen, FieldShield) are all machine-readable. Read More
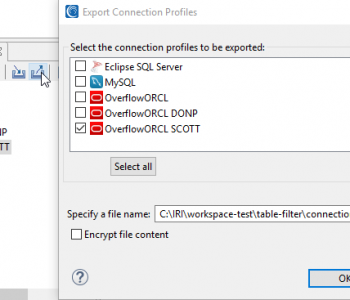
IRI Workbench provides a number of features for working across multiple tables in a database. It includes wizards to: profile databases; classify columns; subset, mask and migrate data; generate test data; etc. Read More
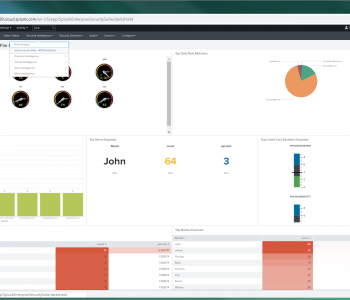
Splunk Enterprise Security (ES) is a major player in the Security Information and Event Management (SIEM) software market. The cloud-based analytic platform combines the indexing and aggregation capabilities of Splunk Enterprise with a range of fit-for-purpose features attendant to SIEM environments. Read More
Finding and masking personally identifiable information (PII) in Snowflake® data warehouses works the same way in IRI FieldShield® or Voracity® installations as it does for other relational database sources. Read More