
Data Class Validation in IRI Workbench
Abstract: This is the first of two articles on data class validation in the IRI Workbench graphical IDE for the IRI DarkShield, FieldShield and CellShield EE data masking tools. It provides an overview of IRI-provided data class validation scripts and how to use them in data classification and discovery. The second article shows how to create your own validation script for a custom data class you need to discover or modify.
Beyond their ability to find data across disparate sources that match patterns, IRI Workbench users can access a large number of computational validation scripts — and/or create their own — for use as Data Matchers in data classification, discovery and masking jobs. These ‘canned’ scripts have been added to applicable preloaded data classes and a library of common Regex patterns.
Data class validation programs verify that a numeric value not only matches a Java Regular Expression (Regex) pattern, but conforms to one or more computational rules that define it. For example, you may find a 16-digit number in a pattern search, but only a computational examination of that number can validate whether it represents a valid credit card PAN.
Why does their extra validation matter? Computational verification of values ensures that the data is clean, correct, and fit for purpose (data quality assessment). First-class analytics can only happen with quality data. And, in data security governance and data privacy law compliance contexts, it is necessary to find values that contain personally identifiable information (PII) while weeding out false positive values.
For these reasons, the provided validation scripts and customization facilities for verifying data class search results are key value-adds for users of the IRI FieldShield, DarkShield, or CellShield EE tools in the IRI Data Protector Suite. Ultimately, these validators could be used in almost any data discovery, extraction, masking, transformation, cleansing, or reporting job supported in the IRI Voracity platform.
What Do These Validation Scripts Check?
Before the addition of these scripts, IRI Workbench data classes that matched on patterns did not have the flexibility to analyze the validity of the data that was matched upon, based only on patterns. Patterns have sufficed in the majority of cases since the structure of the data often had no mathematical logic behind it.
However, data classes such as credit card numbers and national identification numbers require additional validation to ensure the integrity of the data. Common validation checks include:
- Checksum – A checksum is designed to detect errors during the transmission and storage of data. It is calculated by running the data through a mathematical algorithm and is often appended to the end of a string of data.
- D.O.B. – Data might have a person’s date of birth encoded within the number itself. A simple check to verify the date is often needed.
- Regionality & Race – National Identification numbers (NID) often have birthplace or demographic codes within them. The tests performed by country-specific validation routines ensure that the NID not only matches the country’s pattern, but could be real.
Validation Script Library
IRI Workbench ships with several data class validation scripts by default. With these validation scripts, data governance teams have another way to accurately find PII in their disparate silos.
How Do You Use the Validation Scripts?
Validation scripts are used along with pattern analysis during the data classification process, and are assigned inside Data Matchers. Data Matchers examine the content of data values, unlike Location Matchers which find a data class match from the structure or metadata of the source (like a column name). Currently, the only Data Matcher that supports these validation scripts is the pattern matcher.
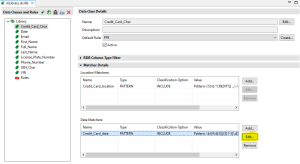
To assign a validation script to a pattern matcher we can either create a new pattern matcher or edit an existing pattern matcher in a Data Class from the Data Class & Rule Library. In the example above, there is a data class called Credit_Card_Char.
The Credit_Card_Char data class contains a data matcher that uses a pattern to match credit card numbers. Clicking Edit … will open the dialog to edit the parameters of the data matcher.
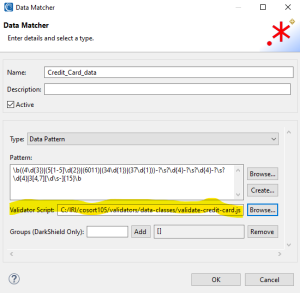
On this page, I added the file path to the IRI-supplied credit card data class validation script. Clicking OK closes the dialog.
Now the Data Matcher stored inside the Credit_Card_Char data class will find what appear to be credit card numbers based on the pattern. But it will not instantiate the match until that number is also verified through the computational analysis performed within the validate-credit-card.js script.
Example: Validation in a DarkShield Search Job
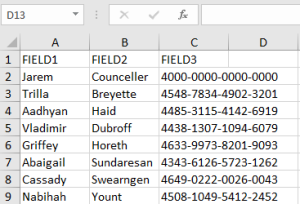
In the example below, an Excel spreadsheet containing three fields – first names, last names, and credit card numbers – is scanned during a DarkShield Search and Mask Job. Among the data classes used during the DarkShield Job is a Credit Card data class.
This data class has been assigned a RegEx pattern matcher and validation script. DarkShield will identify every 16-digit number in the sheet, but mask only those validated as credit card numbers.
Before Masking:
After masking without a validation script:
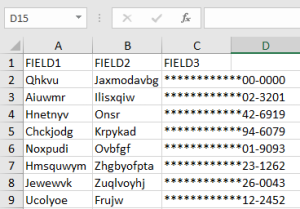
After masking with a validation script:
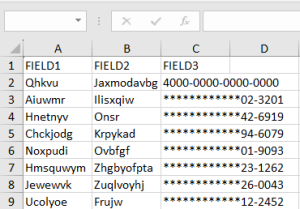
Conclusion
As you can see, validation scripts add another layer of “intelligence” to data classification by filtering out data matches based on validity checking. If you would like to use your own data class validation logic, see this article. If you have any questions, email support@iri.com.










