 Data Quality (DQ)
Data Quality (DQ)
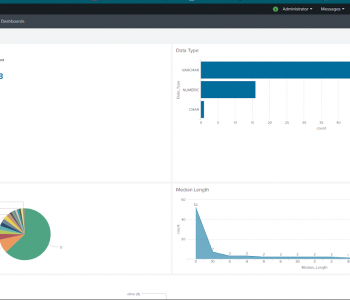
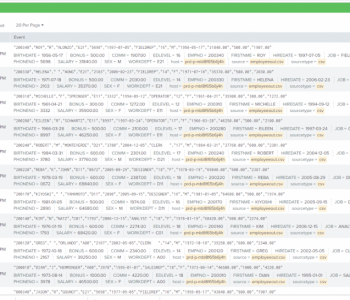
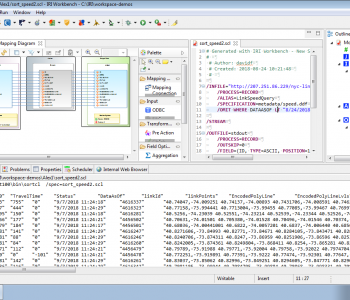
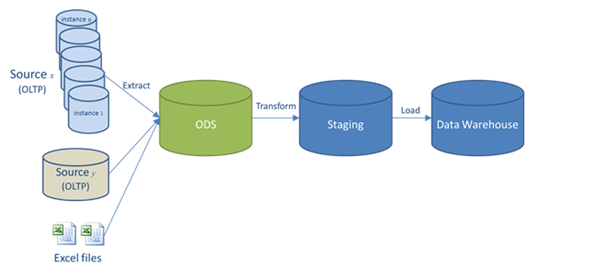
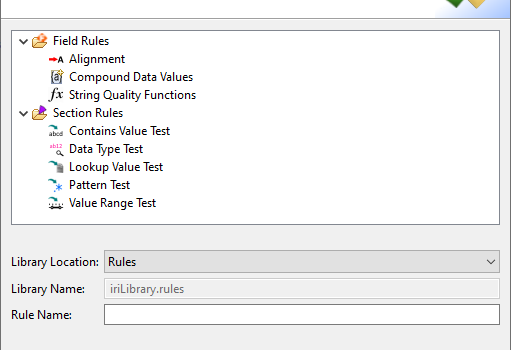
Data Quality Rules in IRI Workbench
IRI Workbench now contains a section of data cleansing, enrichment, and validation rules called Data Quality Rules for use in IRI CoSort data transformation and IRI Voracity ETL, reporting and data wrangling jobs. Read More