Browsing the Operational Data Store (ODS)
What Is an ODS?
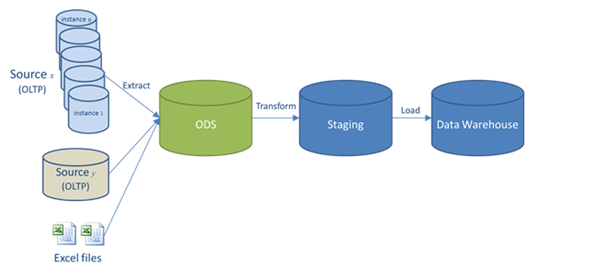
An operational data store (or “ODS”) is another paradigm for integrating enterprise data that is relatively simpler than a data warehouse (DW). The ODS is a central database (DB) where data that has been integrated from disparate sources undergoes specific functions.
Like a DW (in which an ODS is often a component), data in an ODS can come from batch inputs, and is processed by extract, transform, and load (ETL), and data quality, operations:

The ODS can be a vital but complex component of an enterprise data warehouse (EDW). It is also a multi-purpose structure that enables transactional and decision support processing. Because the data originates from multiple sources, the integration often involves cleaning, resolving redundancy, and checking data against business rules for integrity.
A key difference between a DW and an ODS is temporality. Unlike in the warehouse, new data coming into the ODS overwrites existing data. That is because the business unit always needs to work with the most current data (versus aggregate data typical of a DW used for analytics); e.g., when a bank needs to cover, notify, and charge a customer whose account is overdrawn.
More Details
The ODS typically provides a non-historical, integrated view of data in legacy applications. It enables the business unit to complete transactional functions and/or operational reporting with current snapshots of data at a specific level of granularity (atomicity).
ODS data is processed through a series of ETL operations to integrate, transform, and comply with a set of standards where data quality and uniformity are the goals. This data is usually kept in a relational DB so the business unit can access it immediately. And that DB has specific constraints, including referential integrity, to make sure the data is relatable.
The ODS DB is usually designed for low-level or atomic (indivisible) data, such as transactions and prices, with limited history that is captured “real time” or “near real time,” as opposed to the much greater volumes of data stored in the data warehouse, generally on a less-frequent basis. The pace of updates in a batch-oriented DW is usually too slow for operational requirements.
Unlike data in a master data store, ODS data is not passed back to operational systems. It may be passed into further operations and onto the DW for reporting. The ODS is an alternative to a decision support system application that accesses data directly from an online transaction processing (OLTP) system.
Unlike a DW, the ODS tends to focus on the operational requirements of a particular business process (for example, customer service). The ODS must also allow updates and propagate them back to the source system. A DW architecture, on the other hand, helps decision makers access and analyze historical and cross-functional (non-volatile) data, while supporting many different kinds of applications.
So again, the ODS is set of logically related data structures. Its data exists in an integrated, volatile state and at a non-historical granular level, so operational functions can be performed to meet specific business goals. Because the results of its operations are mission critical, and because it shares data and potential ETL workflows with a larger DW, the ODS must also run with the same data governance and management standards in place enterprise-wide.
When the ODS Makes Sense
To understand the purpose of the ODS and its appropriateness as a data integration paradigm, consider its primary attributes:
- Subject-Oriented
The ODS contains data that is unique to a set of business functions in a given subject area.
- Integrated
Legacy application source data undergoes a set of ETL operations, which includes cleansing and transformation processes based on the business’ rules for data quality and standardization.
- Current (non-historical)
The data in the ODS is up-to-date and shows the current status of data from the source applications.
- Granularity
Data in the ODS is primarily used to support operational business functions, and so it must contain the specific level of detail the business requires for those functions to be performed.
The best way to determine if an ODS is an appropriate solution is for business analysts and the data management team to jointly assess the processes involved in completing transactions and providing operational reports. These assessments are most effective if they:
- are performed in a business process management (BPM) framework
- focus on data-dependent functions
- recognize the inefficiencies and ineffective aspects of current or alternative approaches
Through this analysis, and an understanding of what an ODS can do, the team can clearly articulate their issues and requirements. If the business unit’s BPM analysis reveals transactional or operational issues, missed deadlines, data quality errors in the legacy sources, or an aged or poorly designed supporting application, chances are that an ODS is appropriate. The analysis should also help the team design and use the ODS to meet their specific business goals, while adhering to corporate data governance standards.
ODS Example
An ODS in a bank has, at any given time, one account balance for each checking account (courtesy of the checking account system), and one balance for each savings account (per what’s provided by the savings account system).1 The various systems send the account balances periodically (e.g., at the end of each day) to the ODS where functions act on that data to generate alerts, fees, statements, and so on.
In this case, the ODS user also gets a central and complete point of reference for each customer’s profile (such as his/her basic information and account balances. It’s not necessarily a 360 degree view of the customer, since it only speaks to the information and transactions joined in this particular database, but it’s still an ODS.
This example compares and contrasts the ODS and DW as well. Here, the ODS is acting as a batch-oriented DW, updating and replacing each datum that resides in it (and adding new data). But it is not keeping a running history of the measures it stores. You can implement this kind of ODS with batch-oriented middleware, reporting and OLAP tools. Or you can use one platform, like IRI Voracity, to connect to the sources, administer the DB(s), prototype and perform ETL jobs, cleanse, and report.
Modern ODS Manifestations
A more advanced version of an ODS uses the push-pull approach of DW-enabled applications. That allows an informational DB to be refreshed in real-time (or near real-time). However, as you might imagine, that architecture is harder to implement.
In the era of big data, with newer (e.g., unstructured) data sources and Hadoop processing paradigms, the ODS has also been called an Enterprise Data Hub (EDH). Here is how a Hadoop distribution provider illustrates the EDH:
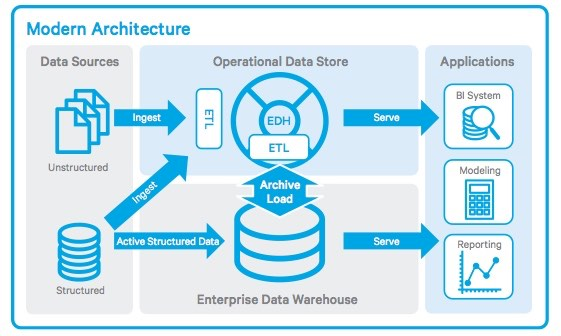 Source: Cloudera
Source: Cloudera
In this model, the EDH is a more robust form of an ODS because it uses the Hadoop File System (HDFS) as a repository for structured and unstructured data, along with an elastic, multi-node computation environment for very high volumes. Big Industries founder Matthias Vallaey explains the benefit of the EDH in terms of both operational performance and analytics:2
The implementation of an enterprise data hub (EDH), powered by Apache Hadoop, provides enterprises an ODS that unlocks value by processing and storing any data type at massive volumes—eliminating the need to archive data—while allowing for quick, familiar data access to end users and applications.
Voracity and the ODS or EDH
IRI Voracity is an end-to-end data management platform built on Eclipse and powered by IRI CoSort or Hadoop3 engines for data discovery, integration, migration, governance, and analytic operations. As an infrastructure for connecting to, integrating, and managing data sources and DBs, Voracity is thus a central, ergonomic place to build and run an ODS or EDH.
In a traditional ODS, Voracity will:
- discover and integrate both relational and flat-file sources
- optimize the ETL components as needed
- administer source and operational DBs via Eclipse DTP
- cleanse and mask the data, as well as generate test data
- create multiple targets in different formats at once, including: updates to the ODS (and DW) DB, custom reports, and hand-offs for BI and analytic tools.
In addition to fast ETL and other data management activities, Voracity’s Eclipse IDE, IRI Workbench, also supports development and execution of SQL and 3GL applications.
The table below reflects the merits of a virtual approach to data warehousing, and what the Voracity data integration platform specifically provides:
| Benefit | Description | Implementation |
| Access More Data | Business users want quick access to new information, from inside and outside the enterprise, while using existing tools and applications. An EDH allows enterprises to ingest, process, and store any volume or type of data from multiple sources. | Connect to legacy and modern data sources from the same Eclipse UI, and perform multiple types of data discovery (including profiling and classification), to help Voracity find the data and apply field rules for integration, masking, and business operations. |
| Optimized Data Processing | ETL workloads that previously ran on storage systems can migrate to the EDH and run in parallel in order to process any volume of data rapidly. Optimizing the placement of these workloads frees capacity on traditional systems, allowing them to focus processing power on business-critical OLAP, reporting, etc. | Migrate existing (or design new) ETL workflows in Voracity, and execute them in parallel with the multi-threaded CoSort engine, or seamlessly in HDFS using MapReduce 2, Spark, Storm or Tez. This allows for a choice of scalable processing of high volumes, in either existing or new Hadoop file systems with the same code. |
| Automated Secure Archive | An EDH offers a secure place to store all your data, in any format and volume, as long as it is needed. This allows you to process and store data without archiving it, and thus re-use it when needed. This puts historic data on-demand to satisfy internal and external analytic needs. | Direct Voracity to pull (push) data from (to) secure repositories, controlled by access code specified in the connection registry, or other authorization task (block in the job flow). This could mean big data secured in cloud repositories, like S3 or smaller data, or metadata assets in systems like Git. |
Enterprises who go this route should see a strong ROI, especially if commodity hardware is used. The EDH can free up existing database licenses and servers for other uses, increase the volume and variety of data collected, and retain that data in active (not archived) storage. By gaining the flexibility and scalability that is limited in a traditional ODS, EDH users can view operational data processing in a new way, one with more possibilities.
For more information about the ODS, EDH, or other data integration paradigm — as well as the myraid data management capabilities that Voracity delivers in these environments — please email voracity@iri.com.
- From Data Warehousing: Operational Data Store (ODS), by Thomas C. Hammergren, in Data Warehousing For Dummies, 2nd Edition
- Operational Data Store: First Step towards an Enterprise Data Hub, blog article by Matthias Vallaey
- Voracity and CoSort are registered trademarks of IRI, Inc.. Eclipse and Built on Eclipse are trademarks of the Eclipse Foundation. Hadoop is a registered trademark of the Apache Foundation.