Feeding Datadog with Voracity Part 1: Datadog’s Fast Friend
This article is first in a 4-part series on feeding the Datadog cloud analytic platform with different kinds of data from IRI Voracity operations. It focuses on the value of Datadog and Voracity together. Subsequent articles cover: preparing data in Voracity and feeding it to Datadog; using Voracity-wrangled data in Datadog visualizations; and, using IRI DarkShield search results in Datadog to improve data security.
In previous articles linked here, we explained how to index Splunk with target data for BI, and log data for SIEM analytics, directly from IRI Voracity ETL/wrangling and PII discovery jobs. Splunk users can leverage several purpose-built IRI connection options to accelerate their information production and improve data security. But what if you use Datadog?
What is Datadog?
Datadog is also a web-facing application for monitoring data feeds, analyzing trends, building analytic dashboard displays, and sending alerts. It was easy to configure Datadog to collect and work with data from the Voracity ecosystem.

What Datadog Eats
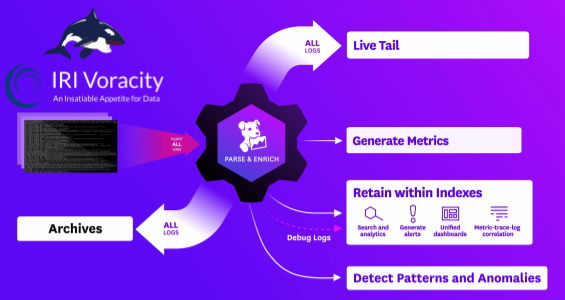
Datadog can work with log data from data and database profiling and discovery jobs in the IRI Workbench graphical IDE for Voracity, built on Eclipse™, and with data targets from Voracity’s back-end CoSort SortCL engine in ETL, migration, data cleansing, masking, and reporting jobs.
Of course, jobs in fit-for-purpose IRI products that Voracity subsumes and SortCL drives — like CoSort, NextForm, FieldShield, DarkShield, and RowGen — are also included in this group. But no matter what the source or nature of the data you’re feeding Datadog is, Datadog refers to that data as a “log” or “logs”.
How Datadog Eats
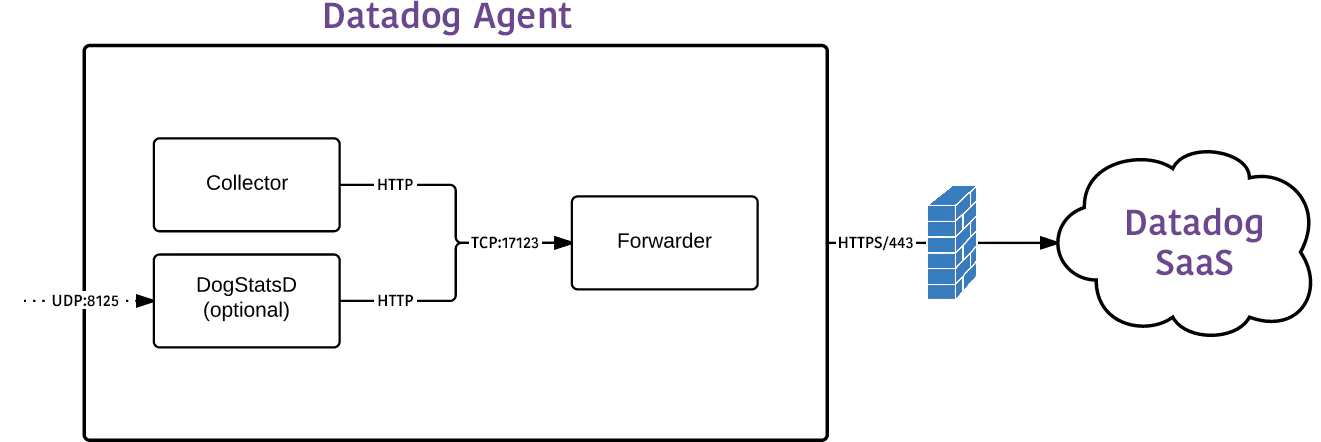
Data feeds, or “logs” from all Voracity-supported operations are not pushed to Datadog as they would be into Splunk through an app, add-on or forwarder. Instead, Datadog automatically pulls Voracity output data up, in real-time, from a collection agent on each machine getting the data.
Does Datadog Need Voracity?
In cases where there is a need for offline, big data preparation before data is emitted, and can be processed on infrastructure external to Datadog, Voracity can provide high-performance data wrangling. This may not be a typical case for Datadog, though it is for Voracity users in ETL and data lake environments who wish to hand-off blended results to Datadog for further analysis and display.
We note that Datadog typically ingests data that streams in real-time from applications, software tools, DB caches and other log emitters. But again in this situation, Voracity is pre-processing an entire set of data sources destined for analysis in Datadog. In a later article, we will present a use case of streaming error and audit logs, plus operational security data from Voracity and the PII searching and masking results from its component products, IRI DarkShield and CellShield EE.
Datadog is a full-featured monitoring, dashboarding, and data processing service. Datadog ingests and processes log data as it comes in. While the first logs will show up within ten seconds, processing large amounts of data as logs into Datadog will take longer for all the logs to show up. The exact time varies by both volume and connection speed.
Even with a very fast connection — like a 1GB/s fiber channel — it will take Datadog additional time to process raw data even after it has been fully uploaded. Data is not visible in the Datadog Log Explorer for viewing, filtering, visualizations, etc. until it has been uploaded and processed.
While Datadog is typically used to process smaller log files in near-real time, Voracity users can process very large files into much smaller subsets to lower the overall size of the data. For an entire 2.1 GB file, raw data preparation in Datadog (an initial stage of data indexing and optimization for logs to be visible for later filtering, sorting, and visualization in the Datadog Log Explorer) takes about 8 minutes, in addition to the 30 seconds it takes to upload into Datadog. Datadog processes the data as it comes, so the first logs from the file will be visible almost immediately. It takes about 8 minutes for all of the data from the file to be processed and visible in Datadog’s log explorer.
Datadog processes logs as they are uploaded, so slower speeds such as 500 MB/s or even 200 MB/s may make no difference in the total processing/uploading time. However, at a certain threshold, likely 100 MB/s or slower, the total processing/uploading time becomes longer.
Regardless of upload speeds however, Voracity can speed everything up by externally processing data ahead of Datadog. Voracity can sort, join, aggregate, reformat, filter, cleanse and mask data, among other functions. Voracity also excels at breaking very large files into files that contain just the data you want, in the format you need (like JSON or XML for Datadog).
Voracity has the versatility to protect your data, while maintaining realism. With this, Voracity can preserve data fields without completely removing them or fully masking them. This can help users have an idea of what the data would be like, or generate sample dashboards without actually exposing any sensitive data.
Voracity can also cleanse data, by removing or modifying data that is incorrect, incomplete, irrelevant, duplicated, or improperly formatted. IRI jobs are batchable and can be run on a schedule so that, at specified intervals of time, a check is run to determine if a new data source file is inserted into a directory or directories and a resulting IRI script is generated and run. The output file can then be specified in the batch script to be transferred to a directory that Datadog monitors. This allows IRI Voracity to fit in nicely with Datadog’s typical data streaming flow.
Preprocessing large files into smaller files with the conditional filtering ability of SortCL can considerably reduce the total amount of time to create a visualization in Datadog from raw data.
How much exactly does SortCL accelerate this process? I will use a 2.1 GB file of United Kingdom company data as a benchmark.
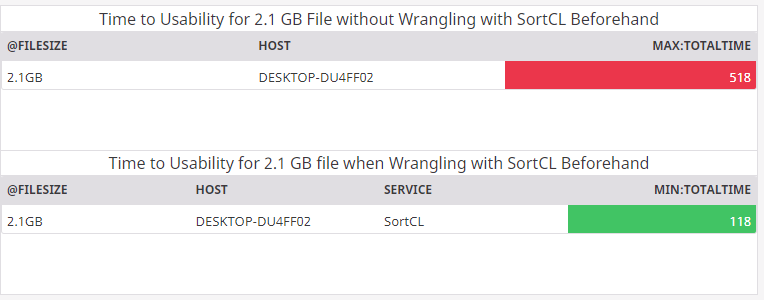
I used the SortCL program in Voracity to filter only the fields I want, with only records where the company’s country of origin is England, the number of mortgages outstanding is greater than 1, and the town is not Cambridge. This results in an 84 MB file. It takes about 100 seconds for SortCL to run this script, then several seconds for the resulting file to be logged into Datadog.
Compare this with logging the entire 2 GB file into Datadog, which takes about 38 seconds to upload and another 7 minutes for Datadog to process,then filter and sort in the same way SortCL did.
While Datadog is very fast with these operations once the file has been processed, usually taking no more than a few seconds, there is still a considerable benefit by preprocessing with SortCL. In this example, SortCL saved about 5 minutes and 45 seconds, a time savings of about 328.5 percent.
I was, ironically, able to use Datadog to visualize the savings:
The smaller the Datadog log target that SortCL can make from a very large source (or sources), the bigger the advantage there is to using SortCL. You can see how SortCL in a CoSort product or Voracity platform context outperforms and accelerates other BI tools in the many data wrangling benchmarks tabbed here.
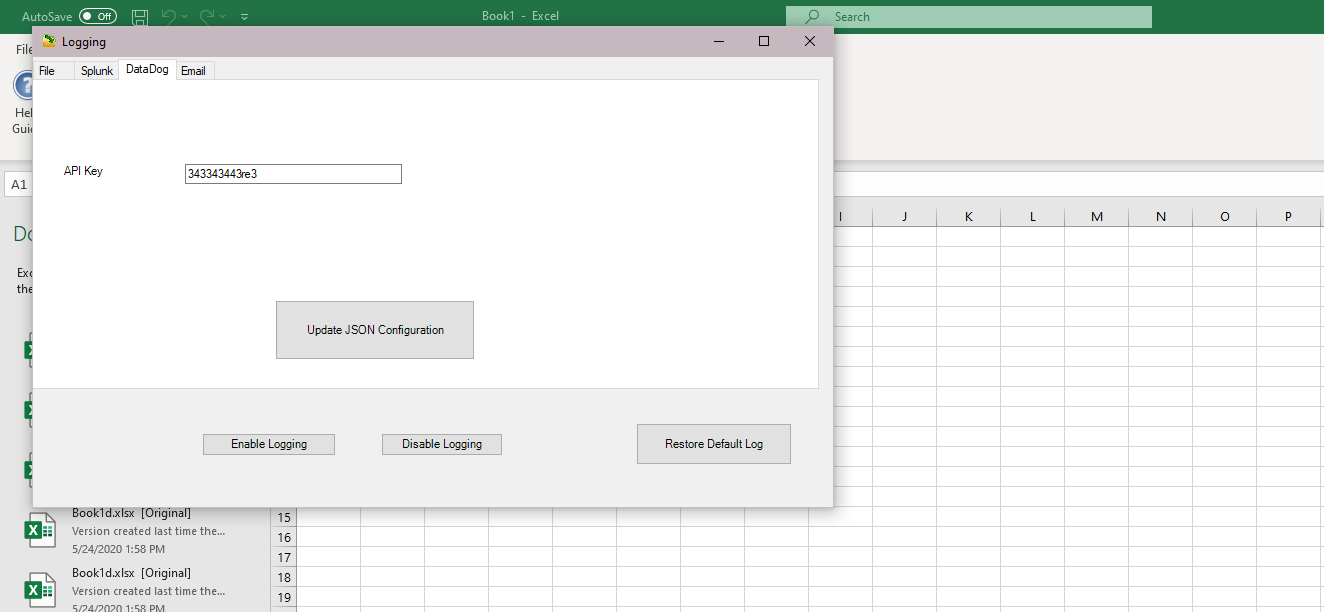
In CellShield Version 2.0, a future release of CellShield that is included in the IRI Voracity suite, error and audit logs will be able to be directly logged to Datadog. The only specification necessary is an API key, which can be edited in an appsettings.json file or directly through the CellShield logging menu.
In the next article of our series, I will demonstrate how to prepare data in Voracity for Datadog.










