
Prepare and Protect Data for AI with Voracity
As I’m finding myself noting more and more frequently this year, AI, and especially generative AI or “GAI”, is the new darling of the tech world, to the point that it has even captured the attention and interest of the general public (albeit not always positively). As such, a huge number of organizations, both within and without the software world, are making plans to leverage GAI in the near future.
In principle, this is all well and good – no doubt a certain amount of the GAI buzz will prove to be empty hype, but such is the way of popular new technologies. I am more concerned that in the rush to jump on the GAI bandwagon, companies will forget to ensure the accuracy and efficacy of the AI systems they’re actually building.
It is all too easy to forget that AI models are trained on data, and that if that data is lacking in some way – if much of it is incorrect, if there’s missing or duplicated data, if there’s unsecured sensitive data, or if there’s undetected and unaccounted for bias in the data, to name only a handful of possibilities – whatever results your AI system spits out will be similarly flawed. It is very much garbage in, garbage out paradigm. For a good example of this, a few years back Amazon created a recruiting AI to parse applications, but it turned out the data it was trained on favored men, so the AI tended to make sexist hiring decisions. There’s no reason to think that modern GAI would not fall victim to the same phenomenon, and indeed early research seems to indicate that the most popular publicly available engines are doing exactly that (see this article on Bloomberg, for example, although I apologize in advance for the painfully over-elaborate visuals it uses).
The converse is also true. To consistently make accurate predictions, or to generate something meaningful in the case of GAI, your AI needs to be trained on highly curated and high-quality data. Your training data needs to be as complete and as accurate as possible, because these traits will carry over to your AI. Moreover, sensitive data will need to be detected and protected (for instance via data masking), so that it is not used or exposed unlawfully. You would also be well served to detect and eliminate any bias in the data. To these ends, it is useful to have access to various data preparation faculties, such as data cleansing, data enrichment, sensitive data discovery, data masking, high-volume data integration, and so on.
This is where IRI and its Voracity platform come in. Voracity component tooling – much of which we have discussed in some detail in other articles – facilitates the creation of high-quality, deidentified data sets which in turn enable you to build and train accurate, effective, and compliant AI (and GAI) models.
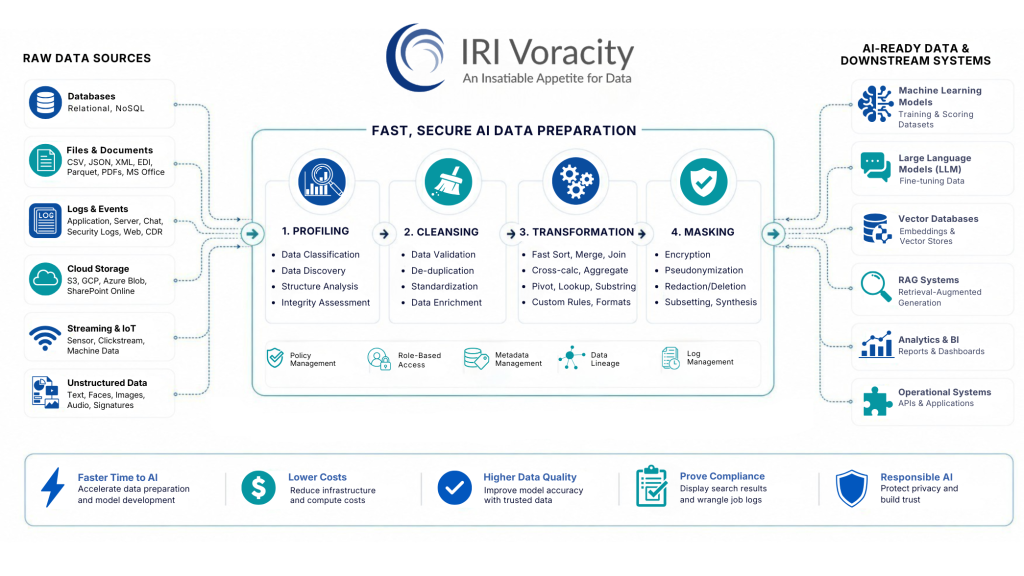
It also provides some specific capabilities to support the creation of more robust AI pipelines. For instance, the Voracity Provider for KNIME prepares and feeds big data sets into Konstanz Information Miner (aka KNIME) workflows. KNIME is an open-source data science environment with various facilities to support AI and machine learning, and its models thus benefit from properly prepared (or prototyped) data sets. One example of this was the use of Voracity-wrangled and anonymized tumor measurement data in a KNIME machine-learning model for breast cancer prediction, as documented here.
At the end of the day, data is an incredibly important factor in building AI. I implore you not to forget that amidst all the GAI hype, and instead to invest in a way to create data sets worth training an AI system on. The IRI Voracity platform, offering as it does a depth of data discovery, integration, migration, governance, and analytics capabilities is an attractive option for this.










