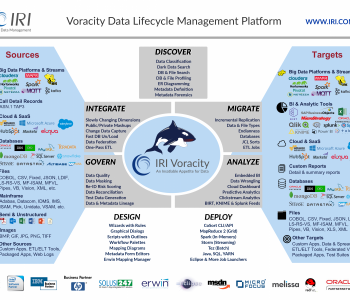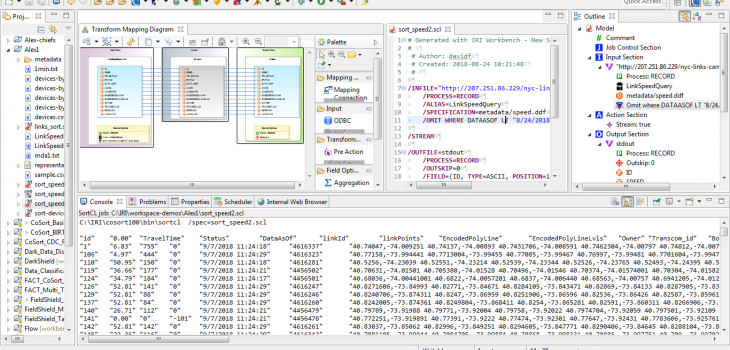
Processing Live Data Feeds in Voracity
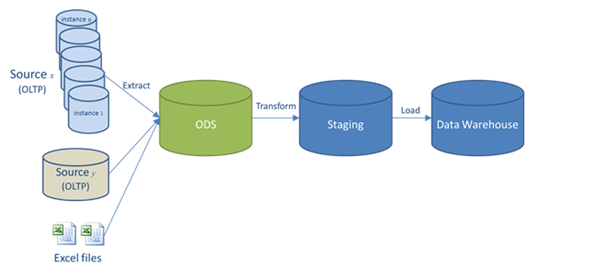
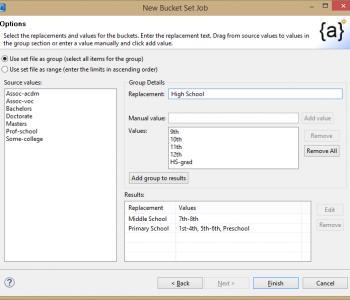
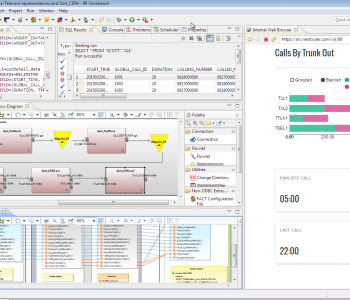
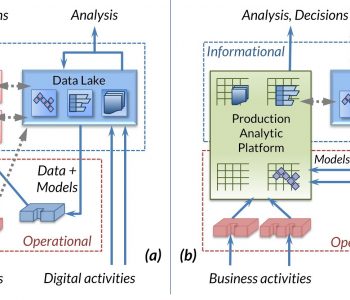
This article demonstrates processing a web-based data source in the IRI Voracity data management platform. Static and streaming data defined in URLs — including flat files in formats like CSV or through FTP/S, HTTP/S, HDFS, Kafka, MQTT, and MongoDB — are supported by the default data processing engine in Voracity, CoSort Version 10. Read More