Production Analytic Platform #2/4: Data Processing Drives Efficiency
This is part 2 of a 4-part series on Production Analytics.
Processing on Par with Information [Part 1]
Processing Real World Data [Part 3]
Unifying the Worlds of Information and Processing [Part 4]
Considering data processing as a central component of data management and on a par with databases offers new insights on how to improve overall efficiency and return on investment in traditional data warehouses. This article looks at the Inclusive Production Analytic Platform and the role an end-to-end processor like IRI Voracity would play in it. A podcast and a video supporting these concepts can be found here.
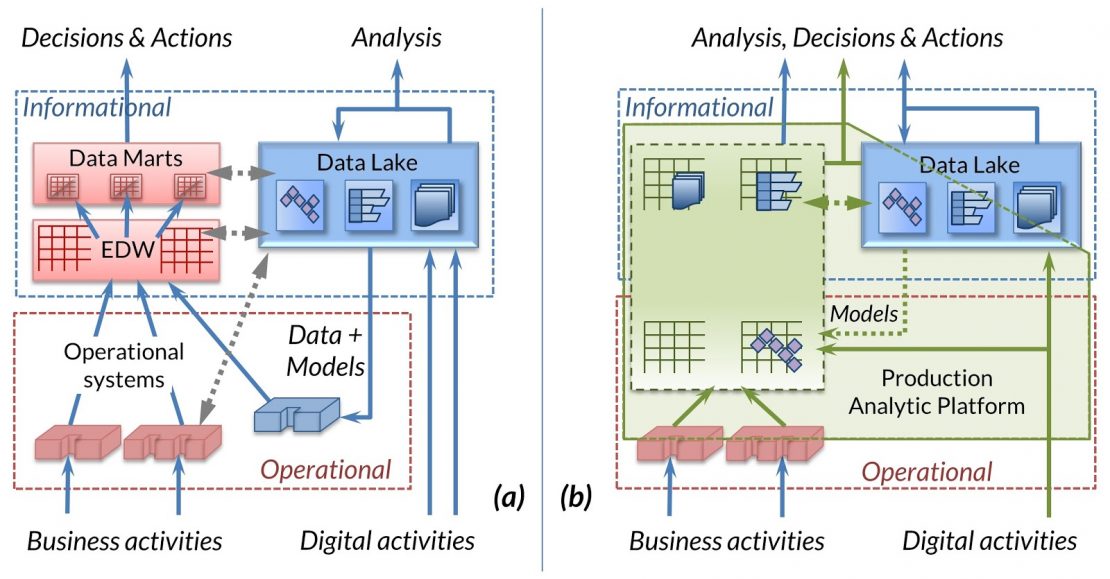
As discussed in the previous blog post, extending the Production Analytic Platform as shown in Figure 1b is a logical architecture that allows and encourages new thinking: What would it mean to place process on an equal footing with information? Where would we explicitly place the process needed to prepare data for business use? How many times should identical or largely similar data be physically stored? Is the old division between operational and informational worlds still valid?
Discussing logical architecture is no easy task. Our approach, therefore, is to examine some simplified but realistic scenarios from the world of data warehousing and data lakes and consider what would change if a Production Analytic Platform were to be implemented using the data processing functions of IRI Voracity. First we look with the boundaries of a traditional data warehouse.
De-layering the Data Warehouse
A traditional data warehouse often consists of multiple layers of staged data between the original sources (operational systems) and the tools the business people use to view and analyze the data. Each layer has a specific purpose. For example, a staging layer may cleanse data from individual sources. The enterprise data warehouse (EDW) layer reconciles data from different sources, matching related records, and removing duplicates. The data mart layer offers optimized subsets of data to specific user groups in a structure suitable to their differing analytic needs. Figure 1a shows the two main layers: EDW and data marts.
Each layer stores a copy, a subset, and/or a derived copy of the data from the layer below. Extract, transform and load (ETL) processing exists between each pair of layers and is often very specific to each. This design has its strengths: It maintains strong separation of concerns. It allows the provision of a permanent and reusable store of integrated data and similar stores of optimized data. It also presents problems: Multiple related but non-identical copies of data must be managed. Multiple layers of ETL delay data delivery to the business and present long-term maintenance problems to IT, and financial headaches for management.
As seen in the previous post, the Production Analytic Platform reduces the layers in the data warehouse environment and further suggests that some production operational function should also be incorporated into the resulting store. Using IRI Voracity to process operational systems data within the Production Analytic Platform as shown in Figure 1b offers a different approach to reducing layering. A single job takes data from multiple sources, cleanses and integrates it, and simultaneously creates an appropriate subset of the data for the analytic needs of a specific business department. The various processes are defined in the SortCL language via the IRI Workbench graphical IDE built on Eclipse™, which generates a complete set of metadata describing all the steps needed. The entire job runs via the SortCL executable (or interchangeably in Hadoop MapReduce v2 / Spark / Storm / Tez), taking the data from end to end in one smooth and efficient memory-resident, multi-core process. This approach clearly addresses the problems of the staged/layered approach outlined above.
Classically trained data warehouse architects will complain that the absence of a staging layer and EDW means that the cleansing and reconciliation processes run individually for each data mart, rather than once for all data marts. They are correct. What they may miss, however, is that we are simply trading off processing against storage. The use of a highly efficient and cost-effective data processing engine offsets the advantages—and disadvantages—of the centralized storage layers. And although we no longer have a physically instantiated EDW, the metadata maintained in SortCL contains a logical description of the common model to which data is reconciled. The approach is conceptually identical to the modern concept of a logical data warehouse (LDW).
As with all trade-offs, the pros and cons must be evaluated in each specific implementation. In my view, there is likely to be a subset of today’s EDW, which I call Core Business Information (CBI), which will continue to be of sufficient value and wide-enough reuse to make it worthwhile to create and maintain a physical copy. Such CBI is a form of reference data for the entire business and is accessed so often that generating it every time would be rather inefficient, a typical Master Data Management type of concern. While an EDW may run to hundreds of terabytes (or more), the CBI is likely to be considerably smaller. The goal is no longer to store all business data in the warehouse; rather, the aim is to store only that data that is central to many decision-making processes and is regularly used.
One vital role of a physical EDW—as the repository of an agreed and legally accepted history of the business—should not be overlooked. Using IRI Voracity, such a repository simply becomes another sink of data from each processing run. Rather than being another layer in a staged process, it becomes an end point, what might be called a historical data mart.
Over the course of its evolution, the EDW has become the source of many semi-operational reports and dashboards that require data reconciled from multiple operational sources. (While conceptually similar to data marts, these deliverables do not depend on another storage layer above the EDW.) Depending on the business processes and organizational structures involved, this reconciliation takes two broad forms: semantic and/or temporal. In the former case, the reconciliation logic and report generation and formatting logic all reside in a single IRI Voracity job that takes data all the way from the sources directly to the user, with gains in speed of delivery and improved cost characteristics.
Where temporal reconciliation is involved, however, some level of staging is likely to be necessary to ensure that the data combined all relates to the same timeframe. In essence, what Voracity does here is to eliminate some or all of the layers of a traditional data warehouse architecture in many business and/or technical circumstances by combining analytic activities with data integration and others in the same pass:
This reduction in layering comes with many benefits. Data is made available to business people more quickly and cost-effectively in support of near real-time decision making. On the IT side, reducing the number of layers and copies of data to be managed is very worthwhile. Ongoing maintenance effort and costs are also reduced as the entire end-to-end process for a business deliverable resides in one job.
Note the trade-off here as well. Ease of maintenance in the vertical direction is partially offset by the increased requirement to reconcile processing across multiple jobs that access data from the same set of operational sources: When any of these sources changes, impact analysis across multiple job streams is required.
Next Up… Processing Real World Data
We turn our attention to the new world of externally sourced data and operational analytics, and see how a data processing focus reduces the complexities associated with the combination of data warehouses and data lakes.










