Production Analytic Platform #4/4: Unifying the Worlds of Information…
This is part 4 of a 4-part series on Production Analytics.
Processing on Par with Information [Part 1]
Data Processing Drives Efficiency [Part 2]
Processing Real World Data [Part 3]
In this final article of the series covering the Production Analytic Platform paradigm, we look at data virtualization—a key requirement in today’s multi-source, data-overloaded world. Coming from a process view, IRI Voracity addresses key data integrity concerns often overlooked in traditional data virtualization solutions. A podcast and a video supporting these concepts can be found here.
Over the past two decades, business people have increasingly demanded access to information, irrespective of its provenance, location, or format. Such demands raise real issues about the quality of the data sources and the ability of decision makers to understand the real meaning of the information used and limitations to its use. While IT generally understands—and often fears—these issues, we have nonetheless striven to facilitate unfettered access by business people to all available data. The Production Analytic Platform, shown in Figure 1b, is a further response to these needs.
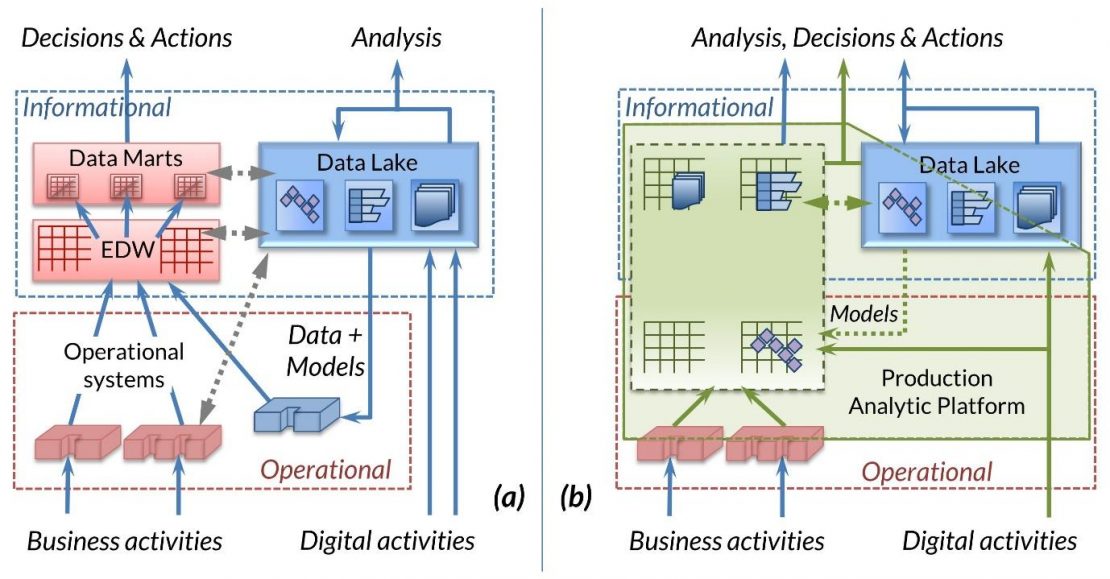
Both data warehouses/marts and data lakes, as well as the optimized storage infrastructure of the Production Analytic Platform, comprise an extensive and varied set of data stores of interest to business users in support of decision making. Business people need not only to access such data but also to “join” it together seamlessly when needed. Meeting these needs is the role of data virtualization function, represented initially by the green arrow at the top of Figure 1b.
Most current thinking about virtualization is in information terms: A query from a user or app is decomposed into two or more sub-queries, each of which is directed to the appropriate data store in the required format where the individual result sets are retrieved, which are then joined together into a single result. This leads to consideration of the metadata needed to know which data resides where and how the resulting data relates to an overarching business and technical model that enables the returned subsets to be correctly joined and understood in context.
Data virtualization (or federation) first emerged in relational database theory as a means of making relational joins across tables in distributed databases, requiring new methods of query optimization that took account of (often slow and unreliable) networks between the database servers. Vendors added such function into their databases, first to enable homogeneous federation between instances of their own databases, and then between disparate relational databases.
Of course, there is a real and growing need to join data between all sorts of databases and data stores. Such heterogeneous functionality is now generally known as data virtualization, while federation is largely reserved for the pure relational environment. Heterogeneous virtualization can be—and is—implemented within databases, but is also increasingly offered as a stand-alone product that runs on its own server “between” all the data sources to be accessed and the users or apps that need access to them.
Virtualization — The Final Process Component
The history and positioning above leads most people to consider data virtualization as somehow part of the information component of the architecture. Ths thinking is, of course, perfectly valid. However, it is also somewhat limited. It fails to see that data virtualization is actually a process. Furthermore, it misses the fact that virtualization depends on the other process components of the Production Analytic Platform.
The process view allows us to see data virtualization as “just another” way of moving, transforming and manipulating data in motion. Traditional ETL (extract, transform and load) tools perform these functions in advance of storing data in a form suitable for business use. Data virtualization performs such functions on the fly, in real-time, as the business person asks a question or submits a query.
In fact, data virtualization and batch ETL are at opposite ends of the timeliness spectrum of data preparation and integration. Bringing these processes together has been an elusive goal.
Enter Voracity
Recognizing this reality, IRI offers data virtualization as a no-added-cost attribute of its Voracity ETL platform. The same language (SortCL) that is used to define its offline data preparation (filter, integrate, cleanse, mask, etc.) operations is also used to define real-time data virtualization.
With Voracity, the metadata generated for the offline scenario is the same used in real-time virtualization, and vice versa. This is a mandatory data quality/integrity requirement when the same combination of data is needed in both ETL (for a stored copy) and via data virtualization (for an up-to-the-second view). This requirement is very difficult to achieve when separate ETL and data virtualization tools are used, because semantic differences between them can lead to confusion around business meaning and inconsistent virtualized and offline results.
In addition to ETL, Voracity offers virtualized data to business users through several approaches. Those include: embedded BI (ad hoc reporting) within Voracity; the open source BIRT tool in Voracity’s Eclipse front-end, a Splunk add-on; and cloud dashboards like DW Digest and iDashboards.
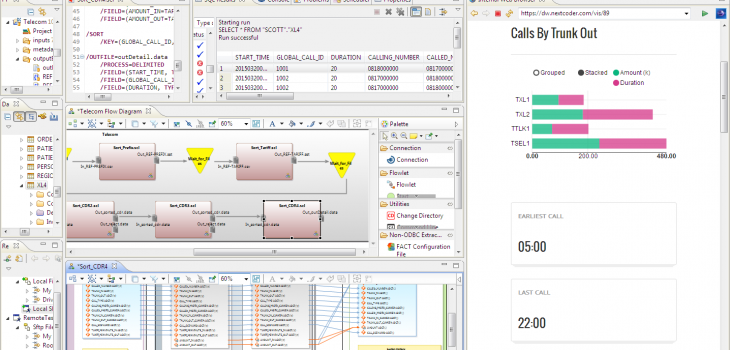
While it is possible to offer direct source-to-user virtualized data, most data virtualization implementations tend to separate business and IT concerns. And the skills required in each case tend to differ. For example, metadata creation in Voracity’s data discovery, definition, ETL, and custom-targeting processes is all wizard-driven, but those processes still require IT and data experience.
However, that work is worth it. The resulting, centralized metadata produced enables an efficient and reusable data preparation environment for IT, and is a natural place for business people to begin exploring the available data, including virtualized data.
Analytic use of the resulting joined data — which is something that business users can and should do for themselves — is still the remit of traditional business intelligence and data visualization environments. Therefore, beyond the tools mentioned above, one can also pipe or persist Voracity-prepared data for faster consumption and display in Cognos, QlikView, R, Tableau et al. Sharing of Voracity workflows and metadata with other (analytic) applications is possible through a Java API, documented in IRI’s “Gulfstream” SDK.
Conclusion
In this short series of blog posts, we explored the power of shifting our thinking from the information component of an informational architecture to its process components. In the case of the Production Analytic Platform, we saw that this process view enabled de-layering of a traditional data warehouse, ingesting and analyzing streaming data, and finally how to correctly position data virtualization.
With its process-centric viewpoint, IRI Voracity addresses all three areas above. Because it operates in-memory and lands data in storage only when absolutely necessary, Voracity achieves high levels of processing efficiency and cost effectiveness. A well-integrated set of technical metadata based on the open, explicit SortCL language eases data management and governance, and allows sharing of function between the three solution areas listed above. Taken together, Voracity enables more integrated processing and thus reduces the need for intermediate copies of data: a powerful driver of cost savings in today’s world of exploding data volumes.










