How to Pseudonymize New Values and Minimize Re-ID Risk
Abstract: It is common practice to mask sensitive production data for non-production purposes. Creating realistic values presents the challenge of handling new values introduced into production data sources and the risk of re-identification. In this post, we will look at a method available to IRI FieldShield, DarkShield, and CellShield users to address both issues at once.
When masking production data used for non-production usage (e.g. testing), it is desirable for the data to be fake but realistic. One of the most common methods of masking data for this purpose is pseudonymization.
Pseudonymization is a form of data substitution where data may or may not be restored to its original value. For more information on IRI methods of pseudonymization, please see this page.
The masking approach covered in this post is based on a common pseudonymization method, but does not guarantee data can be restored to their original values. This may seem a little confusing, but the reasoning will become clearer later on.
While the approach described below can be leveraged for a variety of data fields, this post focuses on the masking of last names.
Challenges to Address
Pseudonymizing data that results in realistic values brings with it the challenges of masking new values introduced into production, and the risk of being able to derive the original value from the masked value (re-identification). Before we discuss a method for addressing these issues, let’s look at a common approach for performing data pseudonymization.
Basic Pseudonymization
One of the easiest ways to pseudonymize data is to use a substitution value contained in a lookup file or a database table with two columns like the maskedLastMap.txt file shown below. Masking names in this case involves finding a matching value in the first column, and using the second column as the output value.

The ability to do this type of search and replace is built into IRI tooling, which will be covered in more detail later in this post.
With basic pseudonymization, what happens if there is a new input value from production that is not in the file above? A maintenance process could be built to update the file, but that will not work in a dynamic environment where masking capabilities are needed on-demand.
What about the risk of determining the original value from a masked value? The file above provides a direct one-to-one mapping back to the production value. You could secure the file, but properly securing this type of file may be easier said than done.
Reducing Re-identification Risk
So, how can we reduce re-identification risk? One possibility is to use a file like the LastName.set file below instead of a file that has direct mapping like the one illustrated in Basic Pseudonymization above.
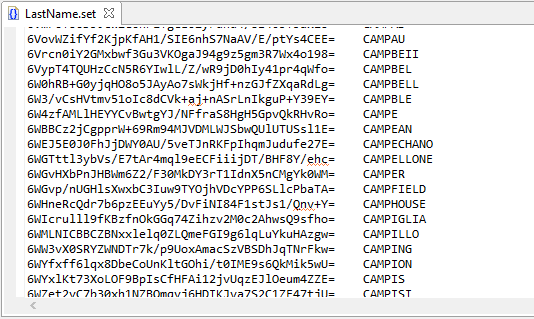
The first thing you will notice is that the first column in the file appears to be an arbitrary string of characters, but is in fact a hash value derived from actual names. Since the hash value is not reversible, mapping masked dataset values back to their production values is not possible.
With this file, the input name must be hashed prior to searching the first column for a match.
Introducing hashing into the process may seem to make things much more complicated, but don’t worry, the process is pretty simple with IRI FieldShield and is covered in Pseudonymization with FieldShield below. And in case you are wondering, the process for setting up the LastName.set file is covered at the end of the post.
Handling New Values
Over a period of time, new values will likely be introduced into production and will need to be masked. As we saw earlier, a standard search and replace approach will not work if the input value doesn’t exist in the file.
One method for resolving this issue, using the LastName.set file from above, is to use the first row containing a value less than the hash value of the input name.
For example, the hash value of Wonderkin is not contained in the LastName.set file and using the first row with a lesser value would result in CAMPER being the masked output value.
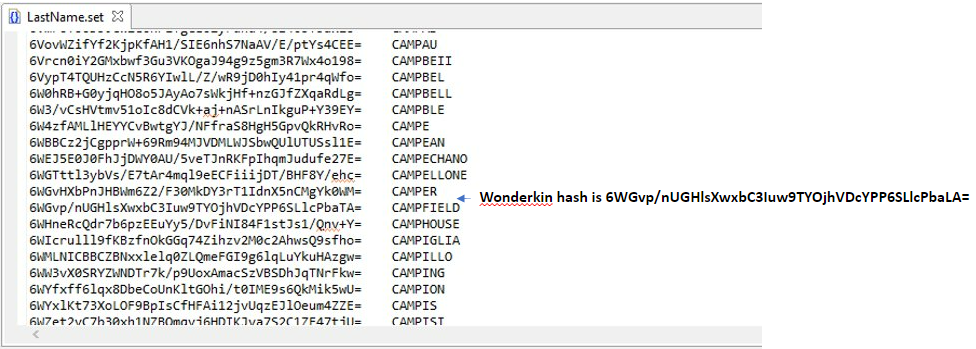
As illustrated above, using the less than method can result in multiple input names mapping to the same output name and will therefore not allow the data to be restored to its original value.
Generally, multiple input names mapping to a single name for non-production testing should not be an issue. The frequency of this occurring can be minimized by having a file with a large number of names.
Pseudonymization with FieldShield
IRI FieldShield is a software product for masking personally identifiable information (PII) using many different methods, including pseudonymization. Instructing FieldShield how to read and protect structured RDBs and flat files is specified via a scripting language called the FieldShield Control Language (FCL), which is based on the antecedent, broader Sort Control Language program, aka SortCL; SortCL can thus run .scl or .fcl job scripts.
Among other methods of pseudonymization, FieldShield supports the implementation of find and replace using what is referred to as a Set file and SEARCH function. The LastName.set file discussed earlier is an example of a Set file and will be used to demonstrate pseudonymization of last names with FieldShield.
Using a Set File
Using the Set file for search and replace is as simple as defining the name of a Set file and a search operation in a /FIELD statement.
Masking the last name is a three step process:

Step 1: The input name is converted to upper case to ensure any difference in a name’s case will result in the same search result. For example, Smith and SMITH will be converted to SMITH.
Step 2: The uppercase name is hashed using a built-in SHA-256 hashing algorithm.
Step 3: The Set file is searched for a value less than or equal to (LE) the value of the hashed name. Note: If the name’s hash value is less than the first record of the Set file the masked last name will be assigned a value of “NONAME”.
Addressing the Challenges
As was mentioned at the beginning of this post, new values and risk of re-identification are two issues that need to be addressed when pseudonymizing names (or other data) for non-production uses.
The use of LE for the /FIELD statement search option addresses any new values that may not exist in the Set file. As mentioned earlier, any less than conditions could result in multiple input names being masked to the same name, but generally this shouldn’t impact its usage.
Using hash values in the masking processes greatly reduces the risk of re-identification. For someone to map a masked name back to its original production value, they would need execute authority for the FieldShield software and access to the encryption passphrase used to hash the names.
Complete Pseudonymization Script
Below is a complete example of the FieldShield job script that demonstrates the concepts discussed in this post to address new values and reduce the risk of re-identification. The script defines a source file (/INFILE statement), performs the specialized pseudonymization work in the /INREC section, and creates the target file with pseudonymized last names file (/OUTFILE statement).
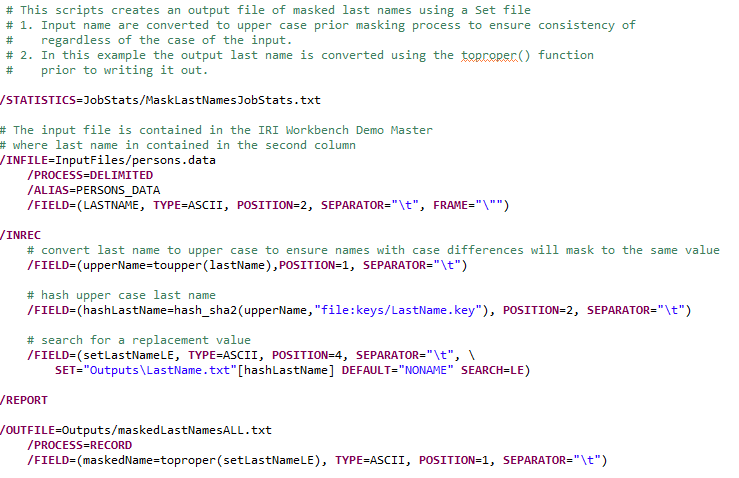
Note again that the input sources and/or output targets can also be RDB tables as well as files.
Creating the LastName.set File
To minimize the many to one mappings that can occur using the method described earlier, it is important when creating the LastName.set file that it contains a large number of names.
For purposes of this post, a Set file of names provided as part of the IRI Workbench install and a 2010 US Census file of last names were used. Some suggested additional sources of last names would be your company’s master person data repository as well as numerous resources that can be found on the internet.
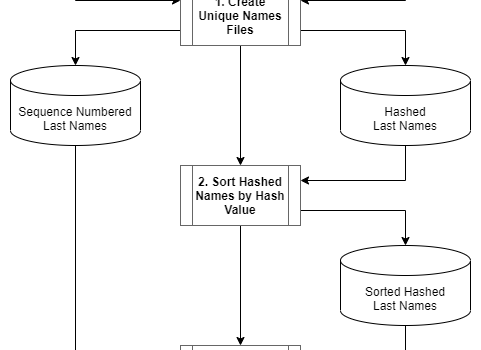
The LastName.set file discussed earlier was created by a three step process depicted in the flowchart below. A detailed description follows.
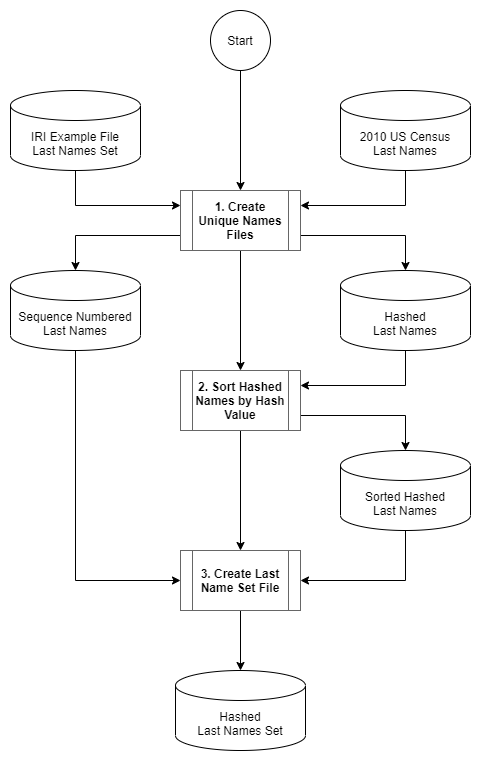
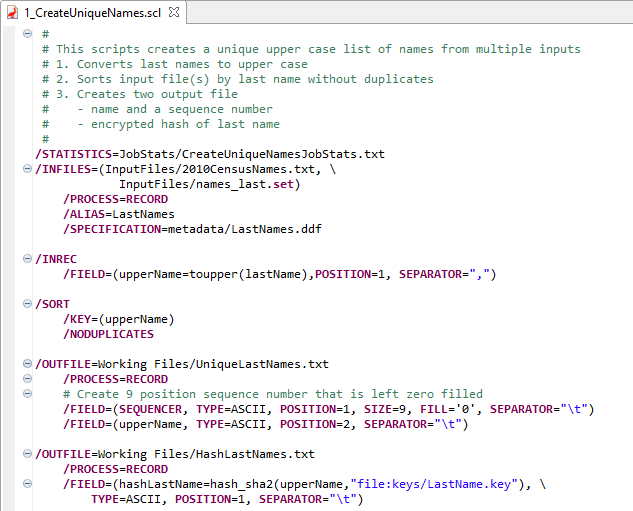
Step 1
The first step in creating the LastName.set file is to combine the IRI example last names Set file and a download of last names from the 2010 US Census. The names are converted to uppercase and sorted to order the records by last name and ensure any duplicates are removed.
Step 1 Script:
Step 1 Input Sample:
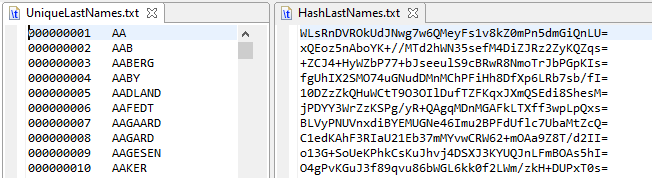
Step 1 Output Sample:
Step 2
In this step the hashed last names are sorted in sequence by hash value and any duplicates are removed. While it may be possible for duplicates to occur, this was not the case in the testing performed using the combined US Census and IRI files with more than 173,000 records.
Step 2 Output Sample
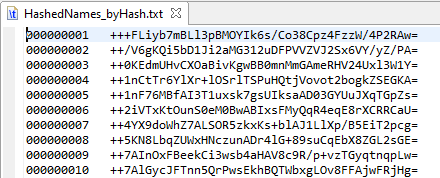
Step 3
In the final step of creating the LastName.set file, the unique last names file from step 1 and the sorted hash file from step 2 are joined by sequence number. The resulting Set file contains a hash value in the first column, and a last name in the second column and is now ready to be used in a script.
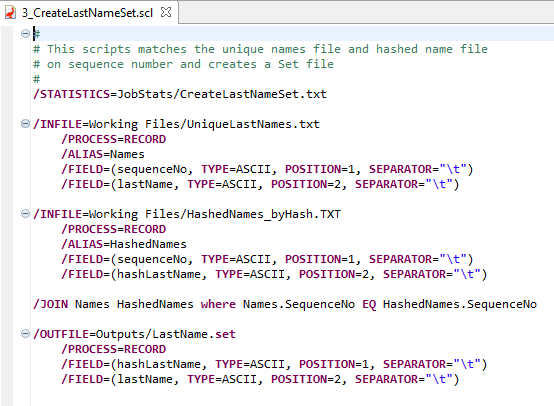
Step 3 Output Sample:
Summary
In this post, we discussed the challenges of new values being added to production and reducing the risk of re-identification when masking production data through pseudonymization for non-production usage. We conceptually addressed these issues using hashed name values stored in a .set file and demonstrated the solution using IRI FieldShield. Following this article and interest in the subject, IRI developed a fit-for-purpose hash-based pseudonymization rule, and hashed set file creation wizard, both now available in IRI Workbench for producing consistent, self-updating pseudonyms.










