Using Tensorflow and PyTorch NER Models in DarkShield

Named entity recognition (NER) is a type of machine learning (ML) used to detect named entities within the grammatical context of unstructured text (documents). NER is needed to find things like people names and street addresses, since those do not conform to patterns, nor likely have a match to values in a defined list (lookup set).
Since many entities like people’s names or addresses are personally identifiable information (PII), IRI DarkShield uses NER to find such data and mask it. While knowing just a person’s name alone might not be too much of a risk, in combination with other sensitive data, the risk for that person to be the target of cyber criminals increases if the dataset were breached.
DarkShield has supported the import and further training of OpenNLP models to find and mask named entities for years. New in the 2022 DarkShield RPC API though is support for state-of-the-art Tensorflow and PyTorch NER models. This is a significant enhancement over the first set of fast, but fewer NER models based on OpenNLP.
![]() Tensorflow and PyTorch support many more publicly available, pre-trained NER models, including those from sources such as the Hugging Face model hub. There are NER models available in over 100 languages from that hub alone. Many of these models take advantage of the relatively new Transformer machine learning architecture for reduced training times and improved accuracy.
Tensorflow and PyTorch support many more publicly available, pre-trained NER models, including those from sources such as the Hugging Face model hub. There are NER models available in over 100 languages from that hub alone. Many of these models take advantage of the relatively new Transformer machine learning architecture for reduced training times and improved accuracy.
![]()
To use the Transformers search matcher with the DarkShield API, we recommend a system with a GPU to speed up the inference of most models (usually by at least 20 times). The DarkShield API will automatically download the dependencies necessary for the Transformers matcher when the server starts.
Models are specified either as a local directory, or from the Hugging Face model hub. If specifying directly from the Hugging Face model hub, then the model_util.py Python script from the plankton/utils folder should be run beforehand to download the model. This script can be given the arguments of the model and tokenizer name (often the same as the model name).
I will demonstrate the detection of named entities in English, Turkish, and Japanese text using three different NER models, all available from the Hugging Face model hub.
English
This first example is actually available as an example in the DarkShield API’s OpenAPI spec.
At the /docs endpoint on the server and port on which the DarkShield API is hosted, there is an interactive example of using a pre-trained NER model to detect four different named entities within a sentence.
![]()
First, a search context must be created. This can be done by trying out and executing a request to create a search context with a PyTorch named entity recognition model from the api/darkshield/searchContext.create endpoint examples.
This example has no model or tokenizer specified, so it uses a default pretrained Bidirectional Encoder Representations from Transformers (BERT) model. This model should be downloaded beforehand by running the model_util.py script available in the utils directory of the DarkShield API distribution with no arguments.
This is done by changing directory to the utils directory and running the command python model_util.py, assuming that python is on the PATH and can be referenced with the python command. In some cases, python3 may need to be used instead of python.
![]()
Once the model has been successfully downloaded and a search context named TransformersMatcherContext created, the context can be used to search English text for named entities. From the api/darkshield/searchContext.search examples, try out and execute the example to Search for named entities using the TransformersMatcherContext. The first time the example runs it will take more time than subsequent searches, as the model has to be initialized the first time.
![]()
After sending the request to the API to search the text with this pretrained NER model, search results are returned that contain what named entities were found in the search, along with the label for the type of named entity the match is, and the probability that it is a named entity.
Note that various different types of named entities have been found, as the model was trained to label more than just people’s names. John Doe was found as a PER entity, which means a person’s name. New York City was found as a LOC entity, which means a location. ‘Knicks’ was found as an ORG entity, which means it was detected as an organization.
The DarkShield API offers flexibility with the entityLabels option in the transformers search matcher, which allows for entities to be filtered to only the entity labels specified. This could be useful if only wanting to match against names, or some combination of labels without matching on all of them. Entity labels can vary between different NER models, so it is important to be familiar with the model you are working with.
Turkish
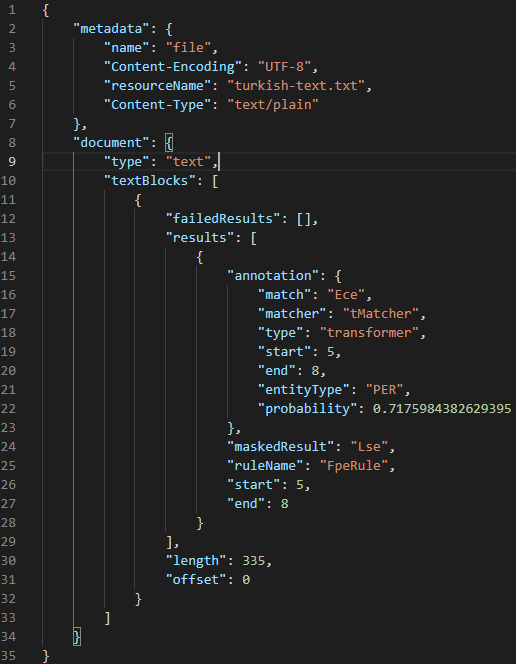
The next example searches text in Turkish for named entities using a different NER model specifically trained for Turkish. The original text is shown below. It contains one name (Ece):

After sending to the DarkShield API, the named entity Ece has been encrypted as ‘Lse’.

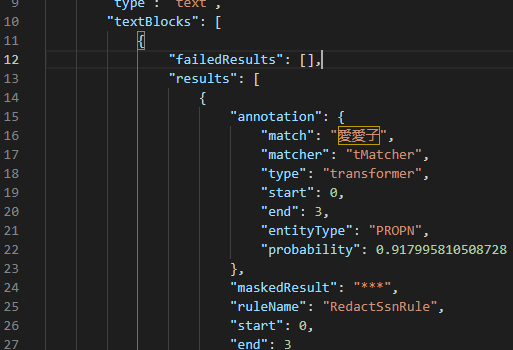
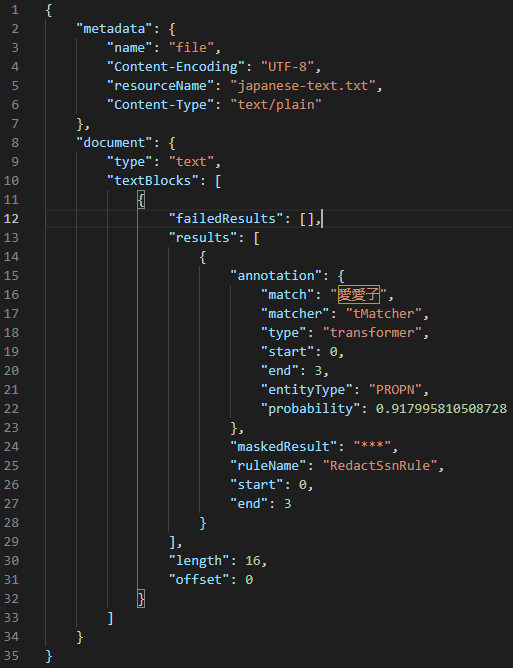
Japanese
My final example demonstrates the use of a Japanese NER model, also available from the Hugging Face model hub, to find a Japanese name in a sentence.
Shown below is the Japanese text I am using for this example, translated into English:
![]()
I set up a search context to utilize the model KoichiYasuoka/roberta-base-japanese-luw-upos from the Hugging Face model hub. This model classifies words based on universal part-of-speech, which includes tags such as VERB for a verb, PROPN for a proper noun, and ADV for an adverb.
Using the entityLabels property of the transformers search matcher, I am filtering tokens to only proper nouns, which are named entities. I have set the aggregation strategy to simple, as that seems to work best for the grouping of entities in this Japanese NER model.
The masking rule I have set up will completely redact all proper nouns with asterisks:

I had downloaded this model beforehand by using the model_util.py script available in the utils directory of the DarkShield API distribution. Just specify the name of the model using the -m command line flag, and the name of the tokenizer (the same in this case, and most cases) with the -t flag.
Once downloaded, either the name of the model in the Hugging Face model hub can be specified in the search matcher, or a path to a folder that contains the model can be specified. If using models from outside the Hugging Face model hub, then specifying a path to a folder that contains all the files associated with the model is the only option.
Here are the results of sending the text shown earlier (Aiko went to the store to buy a banana) to the DarkShield API with the aforementioned contexts.

Looking at the mask results also returned as a part of the response from the API, Aiko was identified correctly as a name and redacted:

That concludes an overview and brief demonstration of the newly added transformers search matcher in the DarkShield API as of version 1.4.0.
This article demonstrated just a fraction of the capabilities now possible with the transformers search matcher in the DarkShield API. This new matcher type further expands DarkShield’s NER capabilities by supporting the popular Tensorflow and PyTorch machine learning frameworks.
Contact darkshield@iri.com with any questions or comments about DarkShield and finding named entities with NER models.










