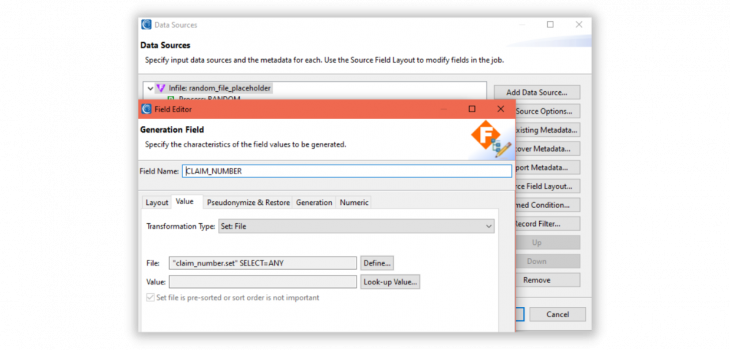
Creating Set Files in IRI Workbench
As discussed in our primer article, set files are used to furnish data for a variety of IRI Voracity-compatible applications, like CoSort, FieldShield, DarkShield, NextForm, and RowGen.
Set files are usually text files with rows of single- or multi-byte characters or numeric values in one or more tab-separated columns, where each row is separated by a new line character.
Alternatively, set files can contain one more literal range of values (e.g., [100-999]). Values are selected from a set file randomly by default, and optionally, there are additional selection methods such as ALL, ONCE, or PERMUTE. If the value selected represents a range of numbers or date/time values, a final value within the designated range will be drawn randomly.
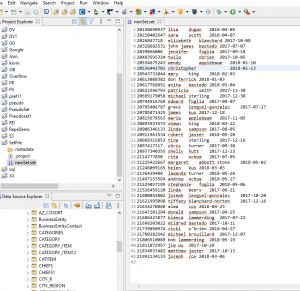
For the purposes of this article, we will discuss the more conventional set file with a list of values, and named with a .set extension. The IRI Workbench image below shows a two-column set file opened in the default editor:
The wizards provided, and described in this article, are: Bucketing Values, Compound Data values, Date Range Generator, Email Generator, Pseudo Hash Set, Pseudo Set, Pseudo Set from Column, Range or Literal Values, and Set from Column:
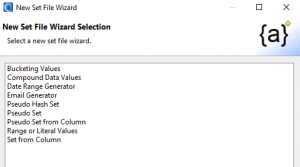
Bucketing Values
The Bucketing Values wizard creates a set file that associates real values with more generalized replacement values that are still real enough, but safe for testing. This type of trait ‘binning’ helps reduce the risk of identifying people from the indirect or quasi-identifying (demographic) information in the same record.
To use this feature, select Bucketing Values from the New Set File … wizard and click Next > to open the Define Destination screen to hold the new set file you will be creating. After giving the path and file name, click Next > to go to the Data Source screen.
In this example, I am using a JSON input file where one of the keys pertains to educational levels for which I want to create generalized replacements. Note that this part of the wizard supports the option to use sources in other formats as well, including CSV, Delimited, Fixed, LDIF, MongoDB, XLS, XLSX, and XML files as well.
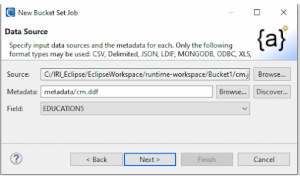
On the Data Source screen (above), click Browse … to select the (input) file that contains the original data values to be bucketed into less specific categories. In this case, it’s my JSON file with individualized key values for Age, Race, Marital_Status, Education, Native Country, WorkClass, Occupation, Salary, and ID:

SortCL-compatible Data Definition Format (DDF) file containing the /FIELD layout (metadata) for this data source must be specified. The DDF can either be imported through the Browse … button if it exists, or created through the Discover … option. The latter runs the Metadata Discovery Wizard to build the DDF file.
Here is that DDF file:
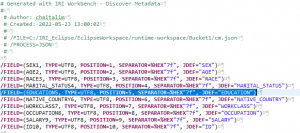
Note that DDFs auto-created for JSON fields automatically append an ordinal number to each field to make sure field names stay unique (as JSON key/item names may repeat).
At this point, I could select the Education5 field from the dropdown for FIELD, which was presented from my DDF for the JSON file. I then clicked Next > to take me to the Options page:
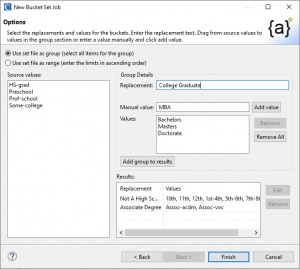
Here I select the type of bucket set to create. I chose Use set file as a group in order to replace the original discrete values with more general values; for example, 9th, 10th, 11th, and 12th grade students are more anonymous in a general high school bucket.
In this example I will create a few categories to generalize my original set file values; i.e., Not a High School Graduate, High School Graduate, Some College, Associate Degree, University Degree. The source values are extracted from the input file.
Drag and drop the Source values into the group values box and name the group in the Replacement Field. Then add a Group result. Once done with all source Values, click Finish.
Once I name the Replacement field, I get Bachelors, Masters, and Doctorate students in the same College Graduate category (bucket), for example. I can also add additional replacement values. In the example above, I entered “MBA” as a Manual value: and clicked Add value: to append it to the list of Values.
Now if I click Add group to results, I will see College Graduate in the Replacement area of the Results section and the values Bachelors, Masters Doctorate, and MBA in the values section. After finishing with this wizard, the set file is built, and I can double-click on it in the file explorer to see these (automatically sorted) values:
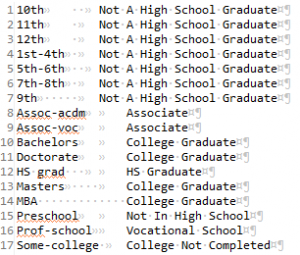
This two-column lookup set file can now be used in FieldShield pseudonymization or RowGen valid pairs selections to produce realistic, but more anonymous test values than my JSON file.
For the second type of bucket set (Use set file as range), I will use an ODBC-connected Oracle table called CLAIMS3. Below is its DDF layout; I want to bucket the values in the AGE column.
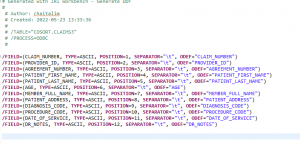
As you can see in the Data Source dialog below, I selected CLAIMS3, added the above metadata, chose the AGE field, and clicked Next > to bring up the options screen:
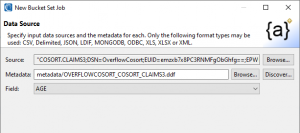
The Options screen below displays my source values from the CLAIMS3 table:
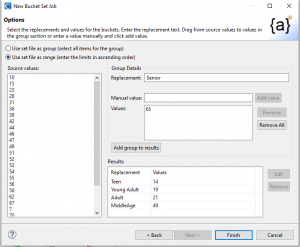
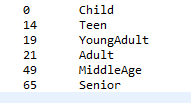
To assign general age-range terms to my values, I need to specify a minimum value for each, along with the age category in the replacement text. In this case, my age categories are Child, Teen, Young Adult, Adult, Middle Age, and Senior, each with a manually specified lowest age (minimum limit value):
Compound Data Values
The Compound Data Values wizard synthesizes values in custom-defined formats using a combination of literal strings and generated values in specified data types. In this example, I am using the wizard to generate a list of realistic phone numbers in standard US format.
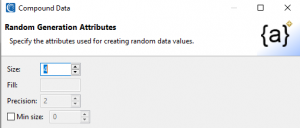
The first step is to define the path and name of the set file I am creating. On this first page, I can also define the number of rows my set will contain and whether the values in it should be sorted:
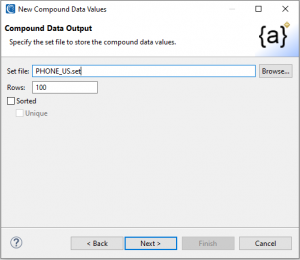
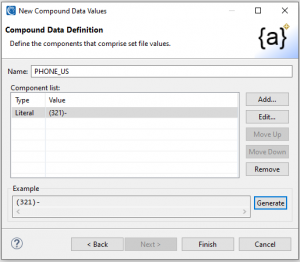
Once I have selected these options, I click Next > to open the Compound Data Definition page of the wizard and begin to define the name of each part of the customs value I am designing.
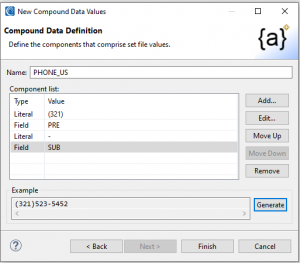
To define the first component, I click Add …to define a literal – here a fixed (321) area code. After that, to create the dash before the prefix, I added the literal “-”.
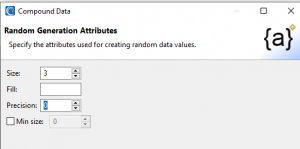
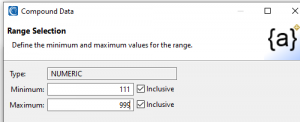
To specify a three-digit phone number PREfix, I clicked Add to generate a numeric value of size 3 and precision 0 with a range between 111 and 999. During that process, I can preview values.
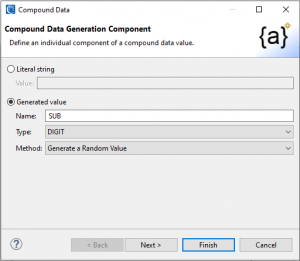
I then added another “-” literal and a randomly generated numeric called sub for the 4-digit remainder of the number. The following pages of the wizards reveal the steps I took:
When I click Finish, the RowGen/SortCL code produced to generate the set file looks like this:

When I run the job to generate this set, I get these phone numbers:

which can now be used in other RowGen jobs to provide randomly selected test values in a phone number column, in FieldShield for pseudonymous phone number replacements, etc.
Date Range Generator
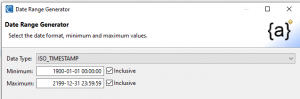
The Data Range Generator wizard creates a set file containing a range of date or timestamp values in one of several default formats.
The Date Range Generator wizard dialog has three options: the data or timestamp format, the minimum and maximum date value range you can modify between 1900 and 2199. Note that you decide whether the minimum or maximum value will be included as a selectable value.
When you click Finish, a ranged set file will be produced reflecting your specifications; e.g.,
Will generate the following, single line ranged set in a named .set file:
[01/01/1900 12:00:00 AM,12/31/2199 11:59:59 PM]
At runtime, values in this format will be drawn from within this range, either at random, or randomly within specified Distribution frequencies, per this article on data generation rules.
Pseudo Hash Set
The Pseudonym Hash Set Creation Wizard creates a specially formatted pseudonym replacement set file where the first column contains a lookup list that has been hashed. This specially formatted pseudo set file is meant to be used in conjunction with a Pseudonym Hash Replacement Rule.
Using a pseudo hash set file with a pseudo hash replacement rule holds a couple of advantages. First, because the lookup list is hashed, the lookup values do not need to be stored securely.
Second, a pseudonym hash replacement rule is more flexible than regular pseudonym replacement because it matches to an exact match but also the closest possible match. This frees users from the need of having to continually update and expand their lookup list.

For more information and an example of this type of set file, see this article.
Email Generator
The Email Generator wizard synthesizes random email address values with custom-defined size ranges and domains. The emails can be used to populate test target columns or replace real email addresses during masking jobs.
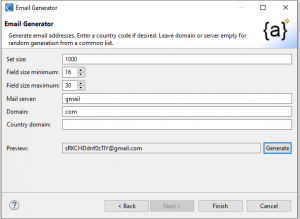
Set Size defines the number of records to be generated in a set file. Field size minimum and maximum define a range of the number of characters that the emails generated will be within, inclusive.
There are several options for the mail server, including Gmail and ATT. For the final part of the Domain, you can select .com, .ded, .net, etc. A country domain can also be added; e.g., .in, ae.
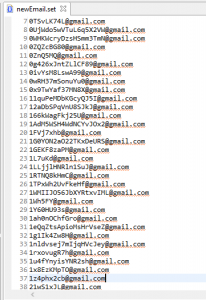
To preview the address, click Generate. Click Finish to build an output (set) file like this:
Pseudo Set
The Pseudo Set wizard creates a two-column set file that can be used for reversible pseudonymization The data in the lookup column serves as the original value, and the data in the results column is its consistent replacement in a static pseudonymization job.
The sources of data from each column can be different. For both the Lookups and the Results Column, you can Add … values from flat files, ODBC-connected database tables, or data streamed from a supported URL connection like a file in HDFS or a cloud bucket, MongoDB HTTPS, FTP, etc.
A default value for a lookup can be specified. The default value is produced if there is no match from the field to the lookup column.
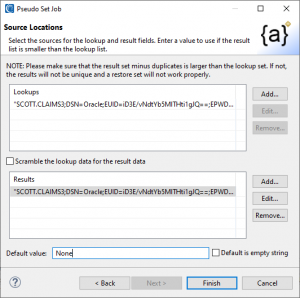
In this example, my source values will come from the PATIENT_FIRST_NAME column in Oracle table called CLAIMS3 (with a predefined DDF file).
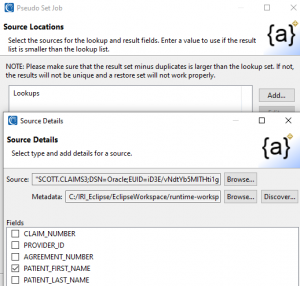
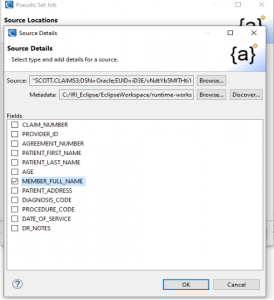
The pseudonyms in the second column will be drawn from the MEMBER_FULL_NAME column in that same table.
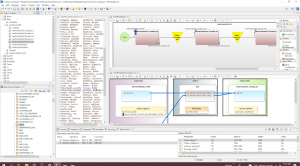
When I click Finish, the wizard builds and runs a batch file with three task scripts that create the pseudo set file. My workspace below shows the workflow diagram of the batch file, one of the scripts and its corresponding mapping diagram, and the resulting lookup set file.
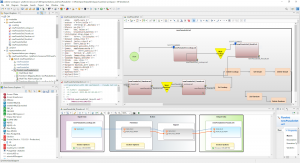
Note that the saved batch file could be incorporated into a masking workflow too, such that the set file is recreated just before a masking job runs so that there would be no missing values. However, this will change the random scrambling of the values in the replacement column, so it would not be consistent from job to job.
Pseudo Set from Column
The Pseudo Set from Column wizard is very similar to the Pseudo set wizard, in that it also produces a two-column set file suitable for pseudonymization. However, this wizard is more purpose-built and easier for creating a pseudo set for data in one or more source DB columns.
This wizard builds the set by reading and sorting table data for the first (lookup) set file column and scrambles those same values for use as pseudonyms in the second column. It also allows you to add data from other tables (which have more of the same kind of values, like last names) and scramble those into the pseudonym column, too.
On the Define Destination screen, type in the name for the job script that will create the set file when run. Check Save script to generate the set file and Execute script on finish to actually produce that file. By saving the scripts that generate the set file, the creation of the set file can easily be made a part of a data masking Flow later.
Since this wizard removes all duplicates from the selected columns, it produces replacements which are suitable for restoration later. Checking the box to Create restore set also will create an inverse restore set which can be used to recover the original names after pseudonymization.
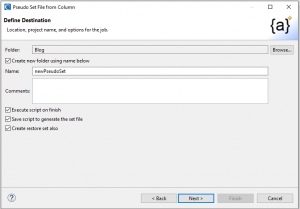
Click next to get into the Pseudo Column Selection page. Select a Connection Profile (in my case DB2), and then one or more tables with columns to use in your set file. In this case, I chose the President column from the Dems table and Name from the Customers_Flow table:
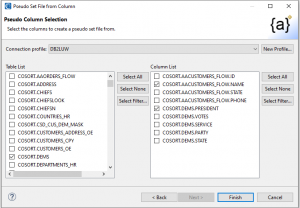
When you click Finish a batch file is created. When run, it creates several artifacts: the job scripts: newPseudoSet_Lookup.scl and newPseudoSet_Pseudo.scl, a newPseudoSet_Pseudo.set, newPseudoset.bat, and new PseudoSet.flow.
This Workbench screenshot shows all the job aspects, including the set file:
Set Range or Literal
This wizard creates a set file denoting a range of numeric values to select from, or a list of literally specified ASCII values. Either way, a test data synthesis job in RowGen would draw values at random when this set file is specified within an input /FIELD.
To include the endpoint values in a range of randomly generated numbers, check the option Including this value. For examples:

The set file built in this case will just contain the item: [1,1000]. You can also specify a range between 1 and 1,000 which does not include endpoint values: (1,1000); a square bracket indicates inclusive while a parenthesis indicates exclusive.
More fully shown, a numeric set file can be specified in the wizard this way:
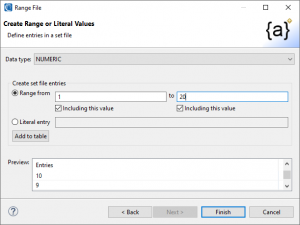
An example of a numeric set file is below. It illustrates a requirement where you might want numbers in a range of one to twenty, with a majority of the values being centered around, and close to ten.
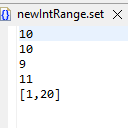
For each row of data, one of the five rows will be selected. If the value of that row is a single number, then that number is used. If the one row with the range is selected, a random value between one and twenty, inclusive, will be selected.
An example with specified literal values on the other is shown here:
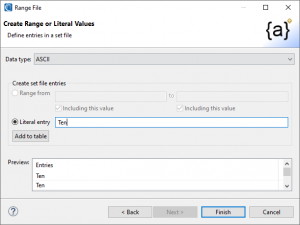
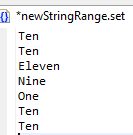
The example below shows a set file with ASCII, or string, entries. With ASCII, each row is a single value; there are no ranges.
Set from Column
This wizard can create a set file using the values in one or more database columns:
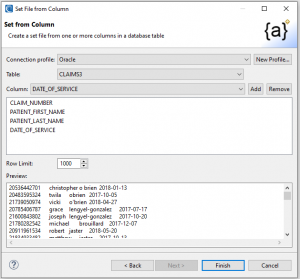
After specifying the set file folder and name you are building, click Next > to specify the source table and column for the data set. In this case, I want the values from four columns in my (tab-delimited) set file to be drawn from the CLAIMS3 table in my Oracle Database; i.e., Claim_Number, Patient_First_Name, Patient_Last_Name, and Date_Of_Service.
The connection profile dropdown menu displays active databases in the Data Connection Registry in Workbench Preferences. From there, the available tables will be shown, and then the columns in that table.
In this case, I sequentially added columns from the CLAIMS3 table and see the data in them previewed below. The Row Limit option refers to the number of rows to select from the table.
On Finish, a new set file like this one is built:
If you have any questions or need help building or using set files with IRI Voracity-compatible software, please contact support@iri.com.










