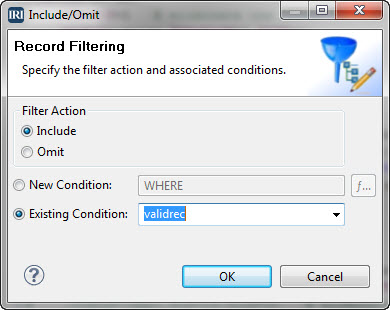
Using Selection to Reduce Data Bulk (and Improve Data…
One of the best ways to speed up big data processing operations is to not process so much data in the first place; i.e. to eliminate unnecessary data ahead of time. Read More
One of the best ways to speed up big data processing operations is to not process so much data in the first place; i.e. to eliminate unnecessary data ahead of time. Read More
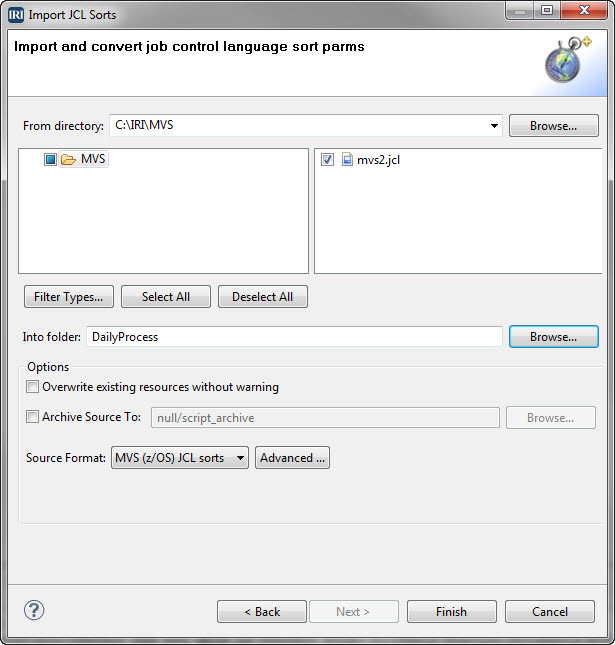
MVS, short for Multiple Virtual Storage, is the original operating system for IBM mainframe computers that is now z/OS. Its shell scripting or job control language (JCL), instructs the system how to run batch jobs or start subsystems. Read More

The sort included with each Unix-based operating system is a standard command line program that prints lines of input or specified input files in the specified sorted order. Read More
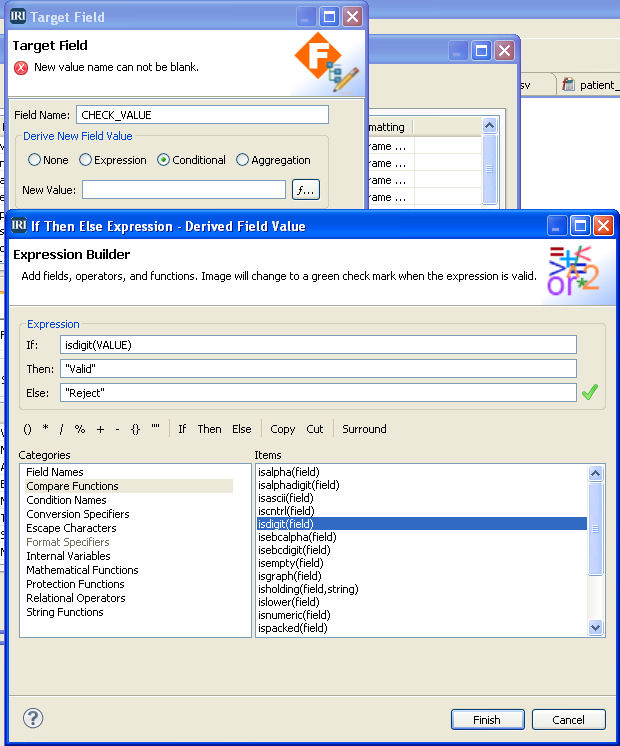
Data validation is a process that ensures a program operates with clean, correct and useful data. It uses routines known as validation rules that systematically check for correctness and meaningfulness of data that are entered into the system. Read More
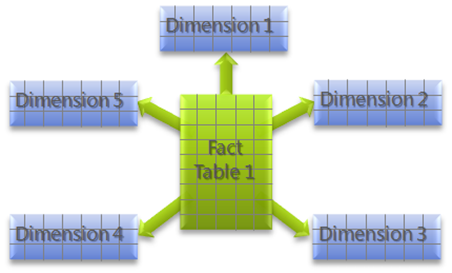
Star schema is the simplest and most common database modelling structure used in traditional data warehouse paradigms. The schema resembles a constellation of stars — generally several bright stars (facts) surrounded by dimmer ones (dimensions) where one or more fact tables reference different dimension tables. Read More

LDIF (Data Interchange Format) is a standard, plain text-based file format representing LDAP (Lightweight Directory Access Protocol) data for address books, spreadsheets and other structured data forms that can be easily manipulated with a text editor. Read More

ODBC, Open Database Connectivity, is an industry-standard application programming interface (API) for access to both relational and non-relational database management systems (DBMS). ODBC was first developed by the SQL Access Group (SAG) in 1992 in response to the need to access data stored in a variety of proprietary personal computer, minicomputer, and mainframe databases without having to know their proprietary interfaces.
Unicode began as a project in 1987 between Apple and Xerox engineers in response to a need for an international standard of representation for every character in all major languages of the world. Read More

One of the main concerns DBAs who need to unload big data from very large database (VLDB) tables have is speed. Faster unloading makes data accessible in different forms for different purposes and platforms. Read More

IRI FACT (Fast Extract) rapidly unloads huge tables in Oracle, Sybase, DB2 UDB, MySQL, SQL Server, Altibase, Greenplum, Teradata, and Tibero to flat files. FACT uses native drivers and parallelization technologies to unload up to 7X faster than other methods. Read More
IRI NextForm converts, replicates, federates, and reports on data in multiple sources and targets. There are six editions that specialize on different migration goals: Lite Edition – basic file conversions, COBOL edition – migrates MF COBOL, MF-ISAM, Acucobol, DBMS edition – database migration, Legacy edition – extracts data from hundreds of legacy sources, Modern edition – addresses cloud, SaaS, and big data sources, and Premium edition – which customizes your migrations for any of these data types, sources, and targets. Read More
{kind=link}
{kind=link}
{kind=link}