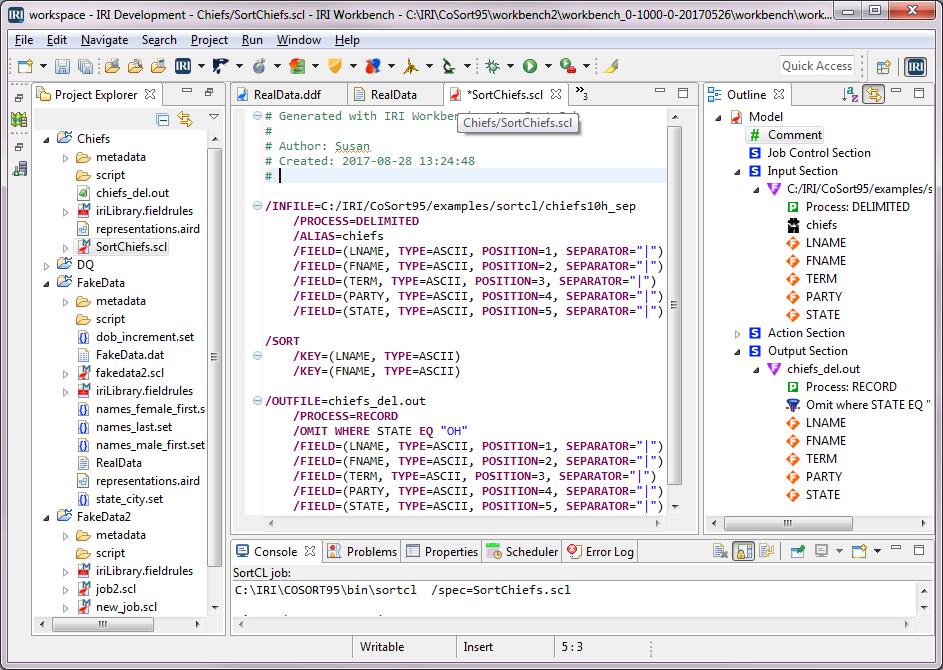
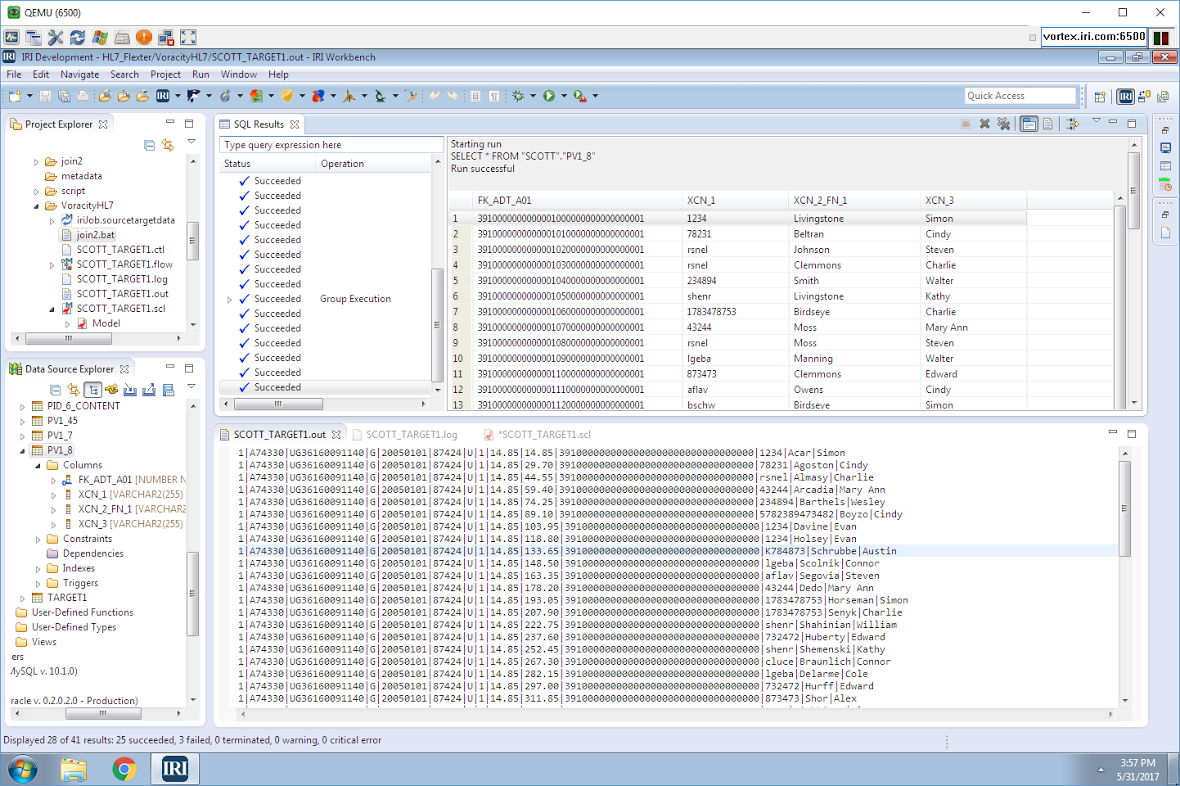
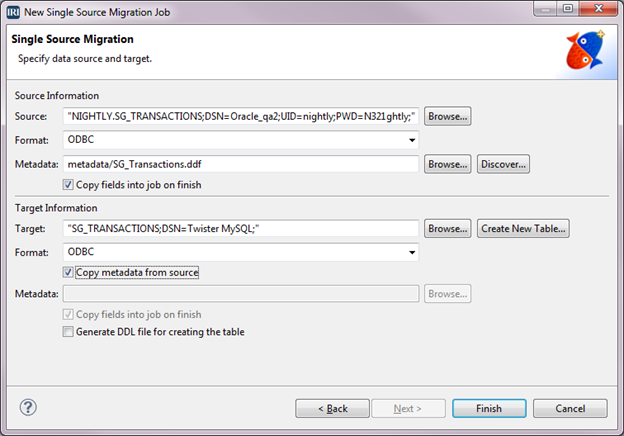
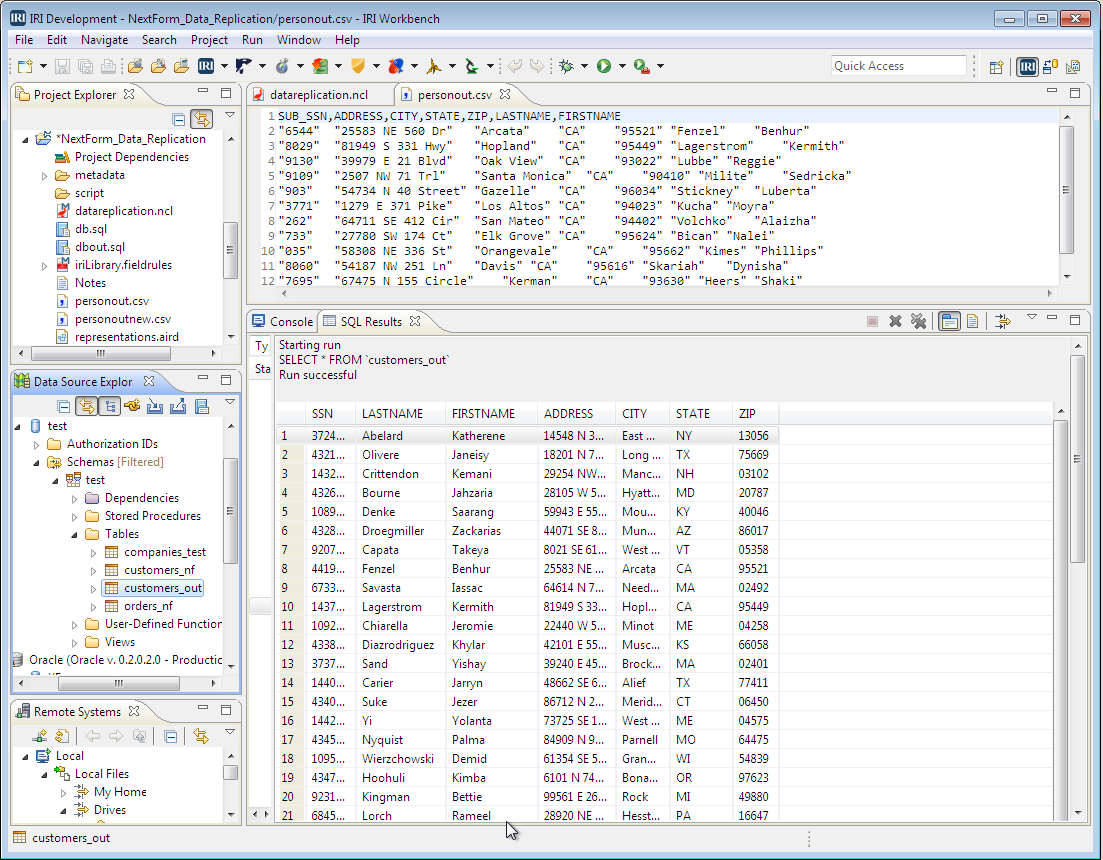
Detecting Incremental Database Changes (Oracle to MongoDB ETL)
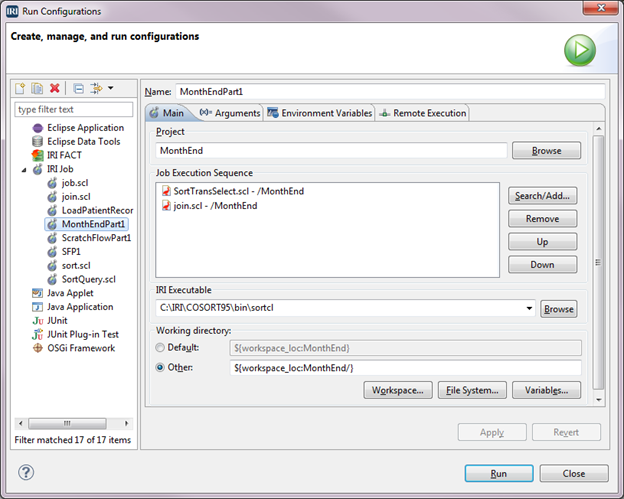
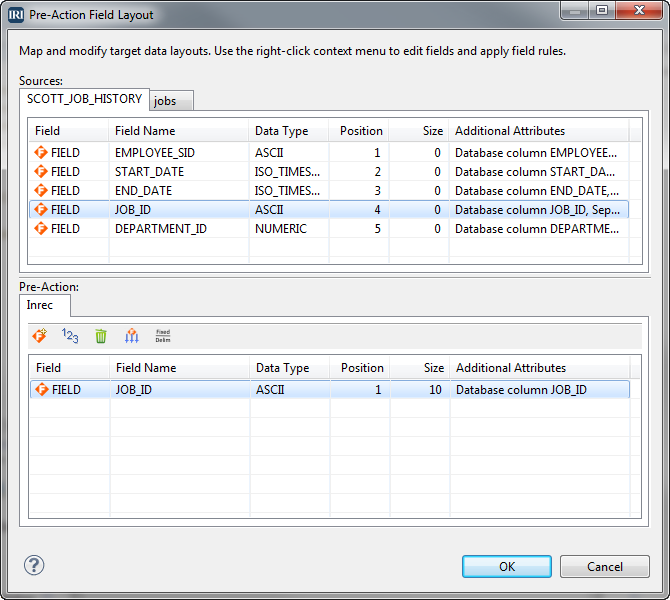
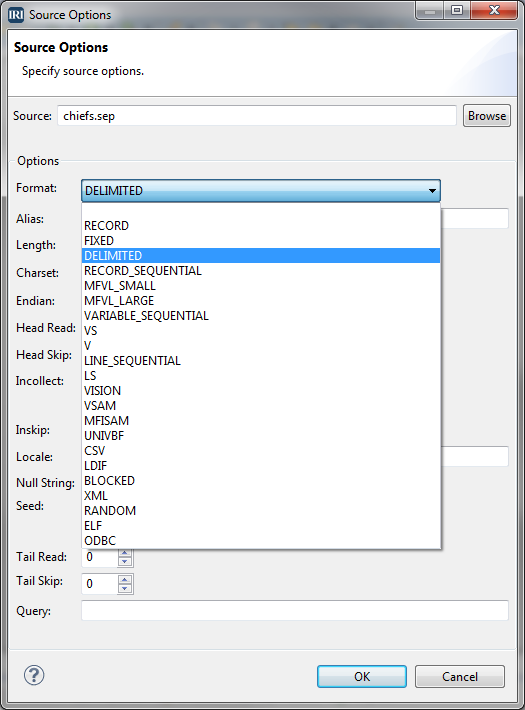
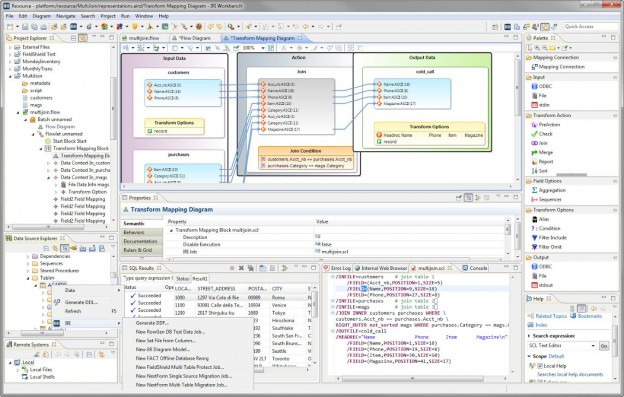
Detecting additions and updates to database tables for data replication, ETL, PII masking, and other incremental data movement and manipulation activities can be automated in IRI Voracity workflows designed and run in IRI Workbench (WB). Read More