The Biggest Challenges in Data Integration
- Procrastinating - chancing SLAs on slow ETL tools because too much was spent
- Betting - on complex Hadoop code, NoSQL or columnar DBs, or ELT appliances
- Partitioning - transforming data in multiple chunks or stages (versus one step)
- Outsourcing - using programs written or maintained by turnover-fraught BPOs
- iPaaS in the Cloud - adding security and bandwidth concerns to functional ones
Real World Solutions
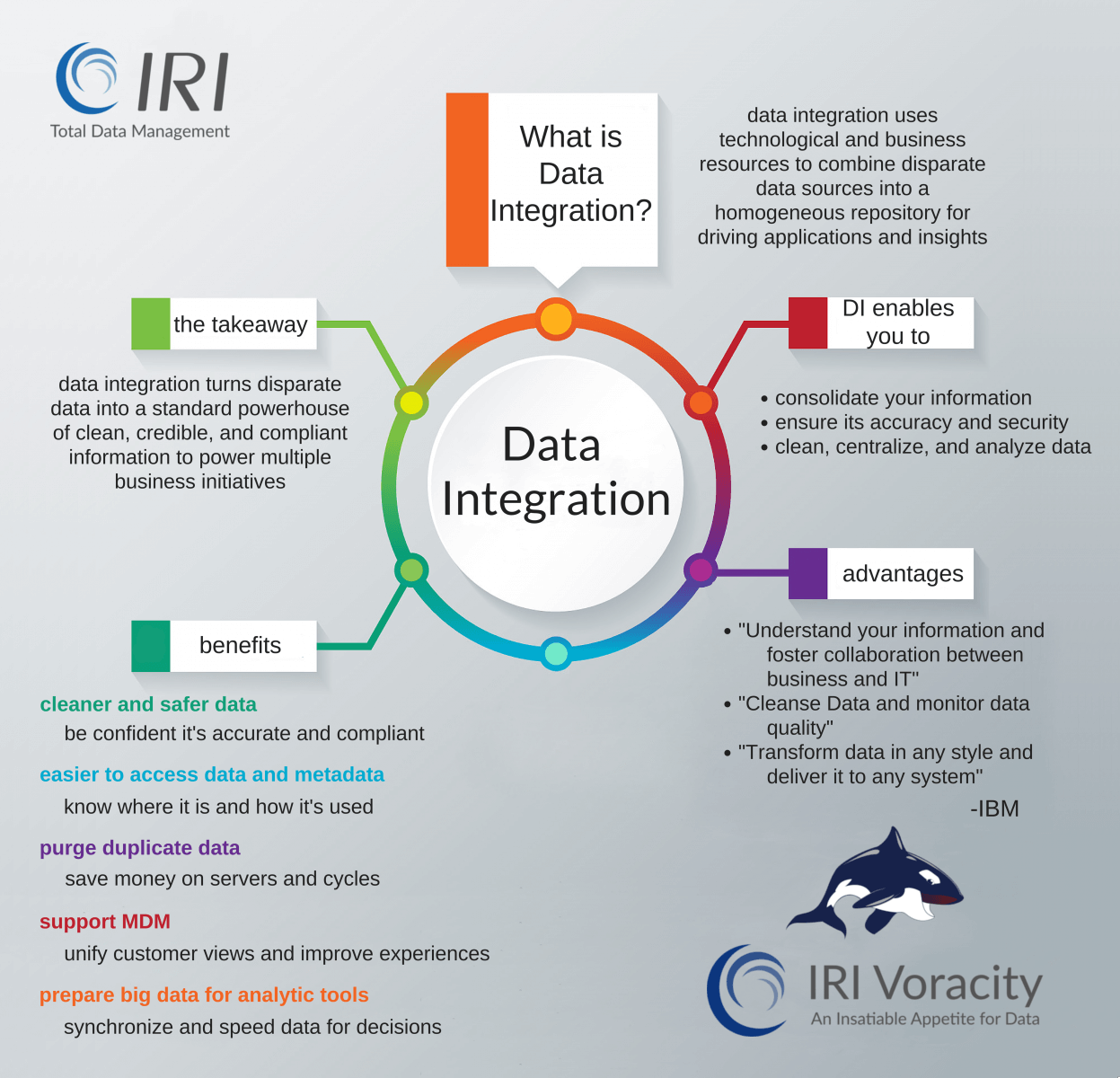
IRI Voracity is an end-to-end data life-cycle management platform powered by decades-proven data transformation technology that addresses the speed, cost and complexity issues in the data integration tool market. You can use Voracity in greenfield projects, or to accelerate or replace existing ETL tools:



Voracity is not only ideal for fast, affordable ETL operations. It is a future-proof solution stack for multiple data management use cases involving structured, semi-structured, and unstructured sources.
The Voracity Edge
Voracity uniquely combines the seamlessly interchangeable power of IRI CoSort and Hadoop engines with multiple job design and deployment options in Eclipse™. In fact, Voracity has more job design, deployment, and licensing options than any other data integration tool.