 ETL
ETL
Smart, Safe Test Data for DevOps, MLOps and DataOps
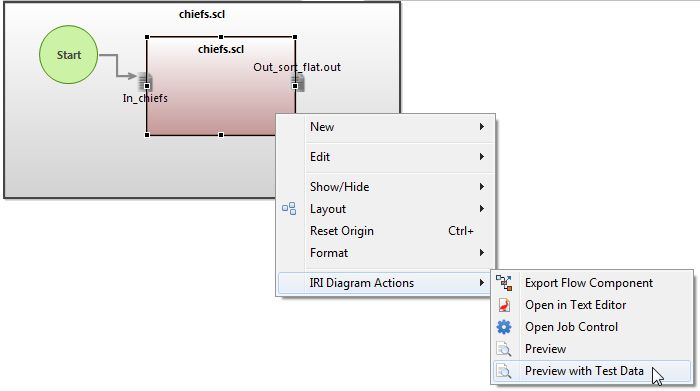
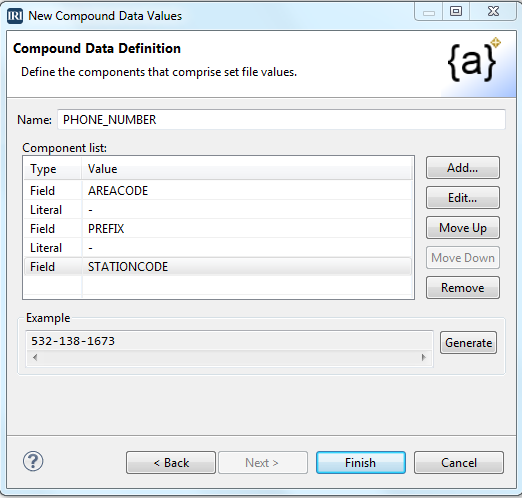
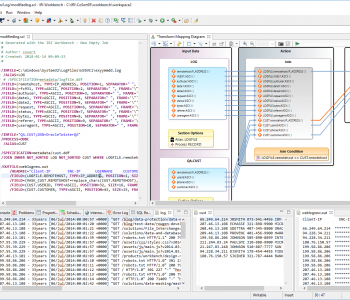
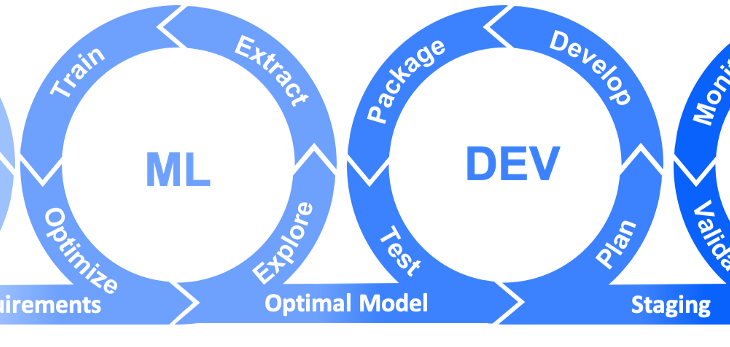
Data flowing through application development, machine learning, and analytic pipelines must address several needs common to all three, including:
Realism, to reflect production data characteristics and application test requirements; Compliance, with business and data privacy rules, plus DB and analytic models; Availability, or security, of the data (depending on your perspective); and, Auditability, for lineage and accountability. Read More