Smart, Safe Test Data for DevOps, MLOps and DataOps
Data flowing through application development, machine learning, and analytic pipelines must address several needs common to all three, including:
- Realism, to reflect production data characteristics and application test requirements;
- Compliance, with business and data privacy rules, plus DB and analytic models;
- Availability, or security, of the data (depending on your perspective); and,
- Auditability, for lineage and accountability.
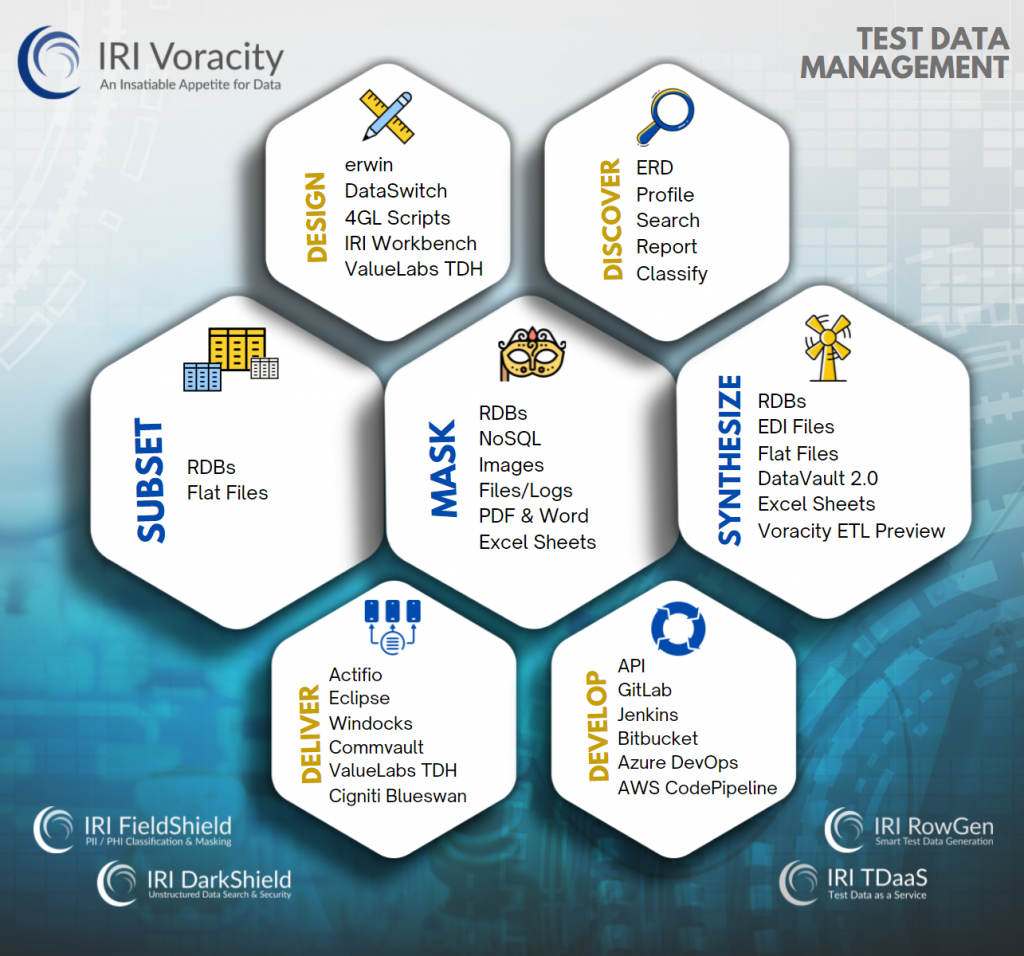
Stakeholders in these pipelines understand these requirements from their own perspectives. IRI, aka The CoSort Company, provides a multi-faceted test data management framework to meet these needs.
IRI roles in this broad area began with the need to create rich, realistic data to test the volume and variety of data transformation and formatting activities supported in the IRI CoSort data manipulation product.
Using the core “SortCL” data definition language and processing program of CoSort, IRI changed the input phase of its ETL process from reading files to building them, either through random value generation of specified data types and ranges and/or random selection of data from external sets.
IRI launched the RowGen spin-off product from SortCL in 2004, and later expanded it to parse, synthesize and load pre-sorted, structurally and referentially correct RDB schema from only DDL details. RowGen can now also: generate new data formats and computationally valid CCNs and NIDs, and sets to handle all-pairs; create nulls and realistic value distributions; work in ETL and CI/CD pipelines; and populate test data in semi- and unstructured sources like EDI and Excel files, PDF and Word documents, and images with embedded test data when used with the IRI DarkShield search/mask API.
Test Data for DevOps (TestOps)
DevOps streamlines software development lifecycle (SDLC) operations to accelerate software delivery. Many developers use CI/CD pipelines to make software releases more agile and continuous. Test data created in IRI Voracity data masking, subsetting, or synthesis tools can be executed and consumed by Jenkins, Amazon CodePipeline, Azure DevOps, GitLab, etc. and be used within those pipelines to assess software functionality and capacity at each build.
The emerging TestOps discipline manages the operational aspects of testing in the SDLC, which include collecting, preparing, and securing exposure data, production systems, and test case sources … in order to scale test coverage, people, and activities (but also to ensure software quality). Intelligent data integration and anonymization of those sources in Voracity thus plays key TestOps roles while improving DevOps QA and mitigating privacy risks.
Test Data for MLOps
Rich, anonymous data also helps in testing machine learning operations (MLOps), which include: saving, loading, and transforming data, as well as model testing and data validation. For each of these phases, for example, the IRI RowGen product in Voracity can rapidly synthesize huge, realistic files in bulk load (e.g., CSV) and ML model formats like PMML/XML and PFA/JSON.
Alternatively, the FieldShield or DarkShield data discovery and masking tools in Voracity can search and sanitize database collections, files, or data streams used in machine learning for safe use in testing.
Test Data for DataOps
Implementing a DataOps testing approach for ETL projects means automating testing for source and target datasets and ensuring those sets reflect the characteristics of data used in real analytic models without identifying people. IRI software facilitates data integration and analytic test automation in several ways.
One way is by combining data transformation and wrangling with data masking or synthesis. Unique to Voracity is the back-end metadata and engine support for such task consolidation. In a single I/O pass through the aforementioned SortCL data processing program, Voracity users can simultaneously synthesize, transform, and format test data into multiple artificial, but realistic analytic targets. Conversely, the program can read one or more production sources, integrate and transform them, as well as cleanse, mask and reformat data into desired targets.
Another way is the data integration preview feature for Voracity ETL architects which runs a mapping job using auto-generated test data. This option builds target subsets with realistic test data so architects can validate their transformation logic and output layout.