Synthesize Smart Test Data & Provision It Your Way
Do you need a test data management solution that can:
- produce and populate realistic test data for databases with referential integrity
- generate smart test data in text files, documents, reports or images
- enhance application quality through stress testing and automation
- produce the volume needed for hardware and software benchmarking
- preview ETL mappings and prototype Data Vault models with test data
- put anonymized datasets online for offshore developers
- integrate directly with database cloning, virtualization and DevOps pipelines
using just data models or metadata, but not actual production data?
If so, you need a robust test data generation tool. Table views, index orders, key relationships, and file and report contents, must reflect the characteristics of production data to be useful in testing. Generating realistic values and formats with synthetic data in ideal ranges and frequencies -- and populating large targets -- can take a long time with other test data generation tools or programs.
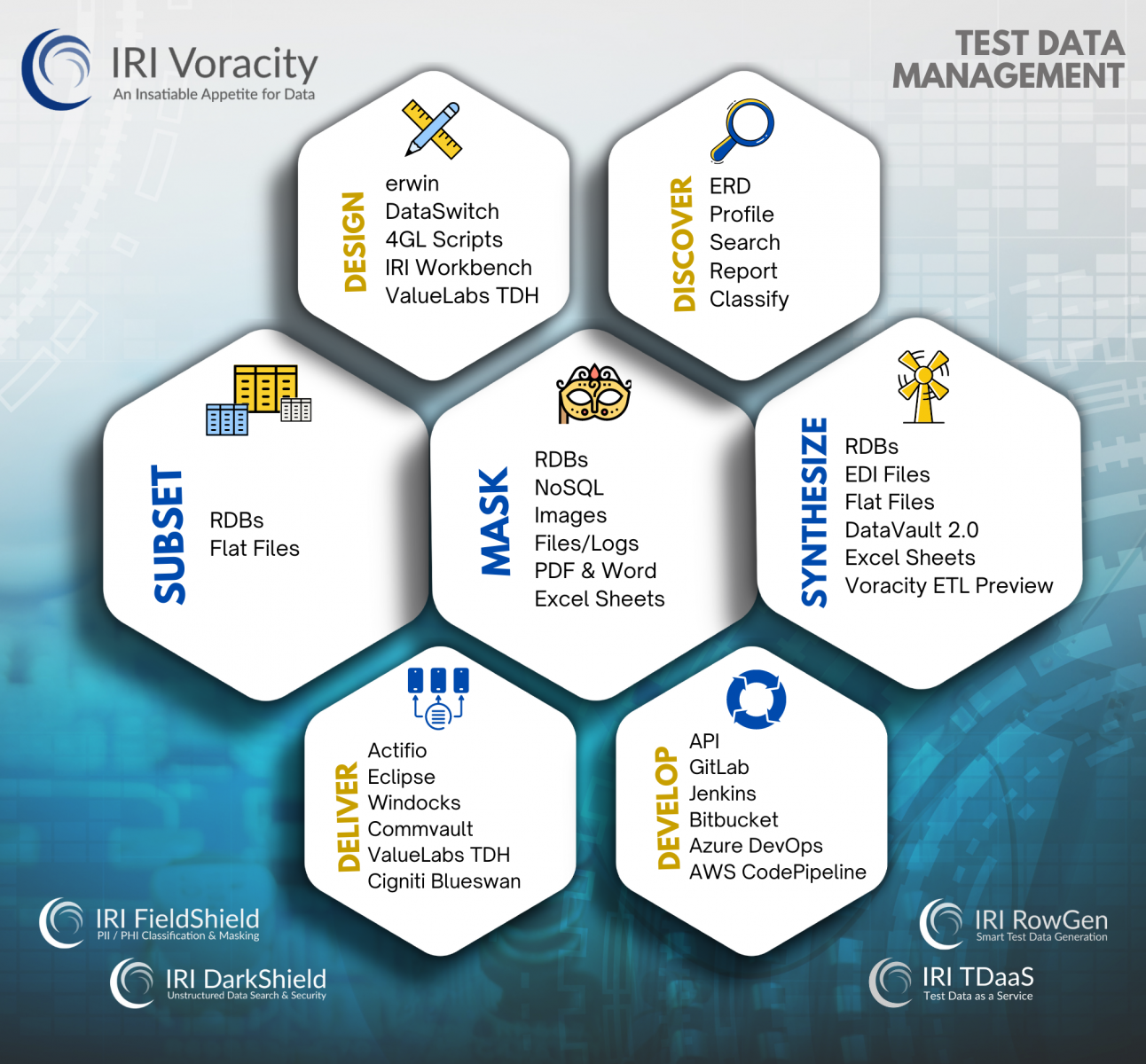
With the IRI RowGen test data synthesis tool or the IRI Voracity test data management (TDM) platform that embeds RowGen, you can generate multiple, intelligent test data targets -- for test databases, file structures, and custom report formats -- from scratch, all without access to real data. Or if you want to use and anonymize, subset, or otherwise mask real data from production, you can do that with IRI data masking and test data provisioning tools in Voracity, too.
IRI test data software gives you four ways to produce anonymous, but intelligent, test data in referentially correct database, flat-file, semi-structured file, formatted report, and even unstructured file targets:
- DB or file synthesis (via random data generation or selection) in IRI RowGen
- Prod or test data masking in IRI FieldShield, CellShieldEE, or DarkShield
- RDB table subsetting and masking using RowGen or FieldShield
- Any combination of the above in IRI Voracity (which includes it all)
Data Synthesis Capabilities
In addition to structurally and referentially correct synthetic test data for every popular RDBMS with defined constraints, RowGen can also create smart synthetic data for software testing. RowGen can seed randomly generated or selected values into custom detail and summary report layouts, document and image files, and popular file/feed formats like these:
- Record, line, or variable sequential
- ASN.1 CDRs
- COBOL index (MF ISAM, Vision)
- CSV, LDIF, JSON, and XML
- Excel (XLS/X)
- FHIR, HL/7 and X12 EDI
- Fixed position text and mainframe blocked
- HDFS
- Image files and PDFs (using DarkShield with RowGen)
- MQTT and Kafka topics
- KNIME (analytic & visualization nodes) in Eclipse
RowGen randomly generates field values in more than 100 data types. It can also randomly select data from set files at the field level. That, along with custom/compound data values, value ranges, and distributions, improve test data realism.
Support for standard and complex data transformations, set files, and conditional selection also contribute to RowGen\'s value in simulating production table and file formats for a variety of applications.
For database users, RowGen leverages the DDL information for Oracle, DB2 UDB, SQL Server, Sybase, Teradata, and other platforms to create realistic tables with structural and referential integrity. Use RowGen to populate an entire test enterprise data warehouse (EDW) or Data Vault 2.0 environment.
Data Masking Capabilities
Use any of the static data masking tools available in the IRI Data Protector Suite, or included free in the IRI Voracity platform:
- IRI FieldShield for structured files and databases
- IRI DarkShield for structured sources as well as many semi-structured and unstructured data sources
- IRI CellShield for Excel spreadsheets
to discover (profile, search, and classify), de-identify (encrypt, pseudonymize, blur, redact, etc.), data in production systems and replicate it anonymized in lower dev, test and QA environments.
If you use IRI Voracity, you can use its included RowGen synthesis and FieldShield data masking capabilities to find, classify, subset, and mask data, and integrate that data for static development use in lower environments or virtual use in live testing environments.
Consider our test data management advice as you plan your strategy, and see these links for more information on using safe test data for: