 Business Intelligence (BI)
Business Intelligence (BI)
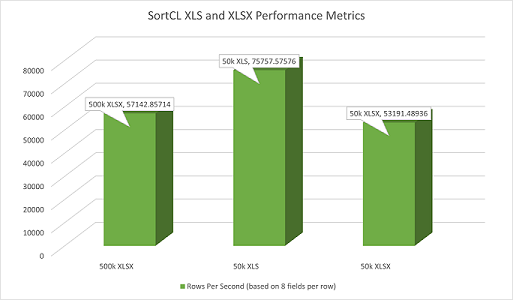
Processing Data in, and for, Excel Spreadsheets
In addition to all the other structured data sources that IRI software already supports, it is now possible to read, process and write data from and to XLS and XLSX files in the SortCL program central to:
IRI CoSort, for fast sorting, transformation, and reporting IRI NextForm, for mapping, migration, and replication IRI RowGen, for random selection or generation of realistic test data IRI FieldShield, for sensitive data masking IRI Voracity, for all the above, plus ETL, data cleansing, and wrangling for analyticsand to write the resulting data back to those or other targets, including one or more Excel sheets. Read More