IRI DarkShield-Files RPC API
The IRI DarkShield data masking tool features a self-hosted (on-premise) Remote Procedure Call (RPC) Application Programming Interface (API) for PII data masking in structured, semi-structured and unstructured files. This data masking API allows DarkShield to be easily embedded as middleware in a pipeline outside of IRI Workbench.
Note this API is also leveraged in the IRI Workbench GUI for DarkShield through the File Search/Mask wizard (which now also supports the detection and redaction of signatures among other PII), as described in this article.
Currently supported file formats include:
- CSV/TSV
- Fixed Width
- FHIR/HL7/X12
- JSON
- MS Excel (.xls/.xlsx)
- MS Word (.doc/.docx)
- MS PowerPoint (.ppt/.pptx)
- Parquet
- Plain / Raw Text
- XML
- PDFs (with embedded images)
- Images (png, .jpg/x/2, .tif/f, .gif, .bmp)
- DICOM (medical studies, including metadata and burned in pixels)
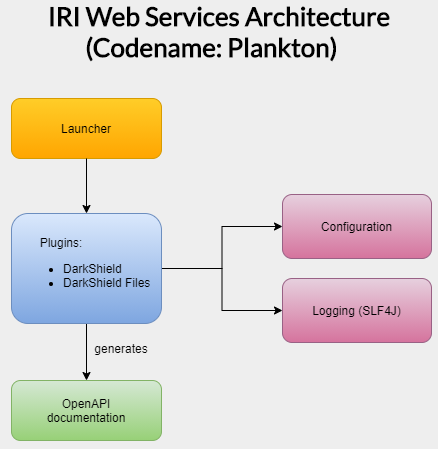
The API is built as a plugin on top of the IRI Web Services Platform (codenamed Plankton), allowing the user to pick which services they will require while utilizing the same hosting, configuration, and logging capabilities provided through the platform. It is typically used for at rest unstructured data masking, and can be used for dynamic data masking.
Before continuing with this article, please familiarize yourself with the operations of the base DarkShield API in this article. It outlines the declaration and use of Search and Mask Contexts to search and mask free-form text sent in JSON payloads.
The Files API utilizes the same Search and Mask Contexts to perform search and masking operations on text parsed from the different file formats. The Files API includes additional matchers, filters, and configuration options for specific file formats.
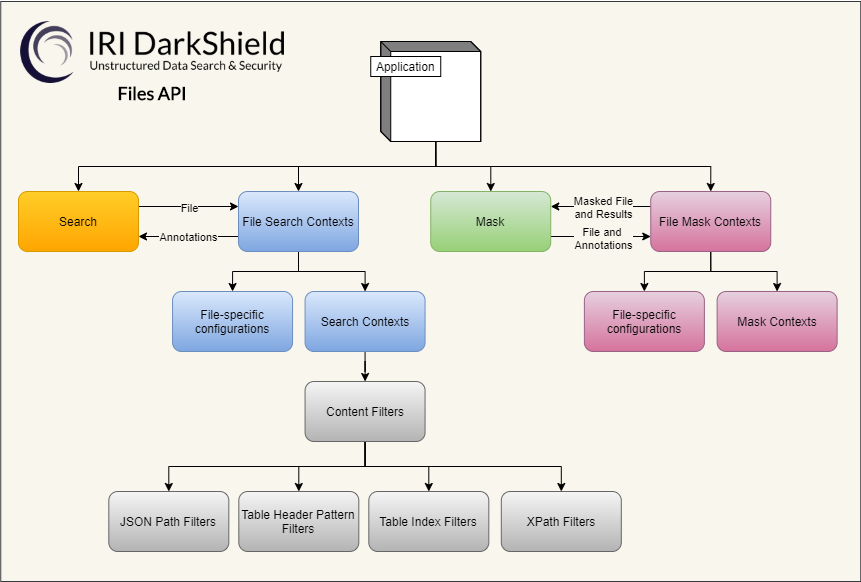
The rest of the article consists of an explanation of the various configuration options available through the File Search Contexts and File Mask Contexts, followed by a general demo setup guideline. After reading these three sections, you can choose to navigate to the sections on the different file types that you are most interested in searching and masking.
All demos associated with this article can be downloaded from our Git repository here. To run the demos, you will need a working copy of the DarkShield-Files API hosted locally on your computer. Read the instructions in the Readme.md file for information on how to setup an environment to run the demos. Contact your IRI representative for a trial copy of the software.
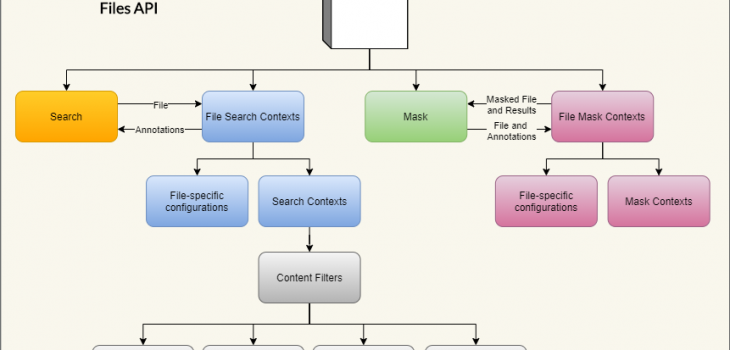
File Search Contexts
The Files API introduces an extension to the base Search Context, a File Search Context, for defining search criteria for files. The following snippet of the OpenAPI definition shows the structure of its schema:
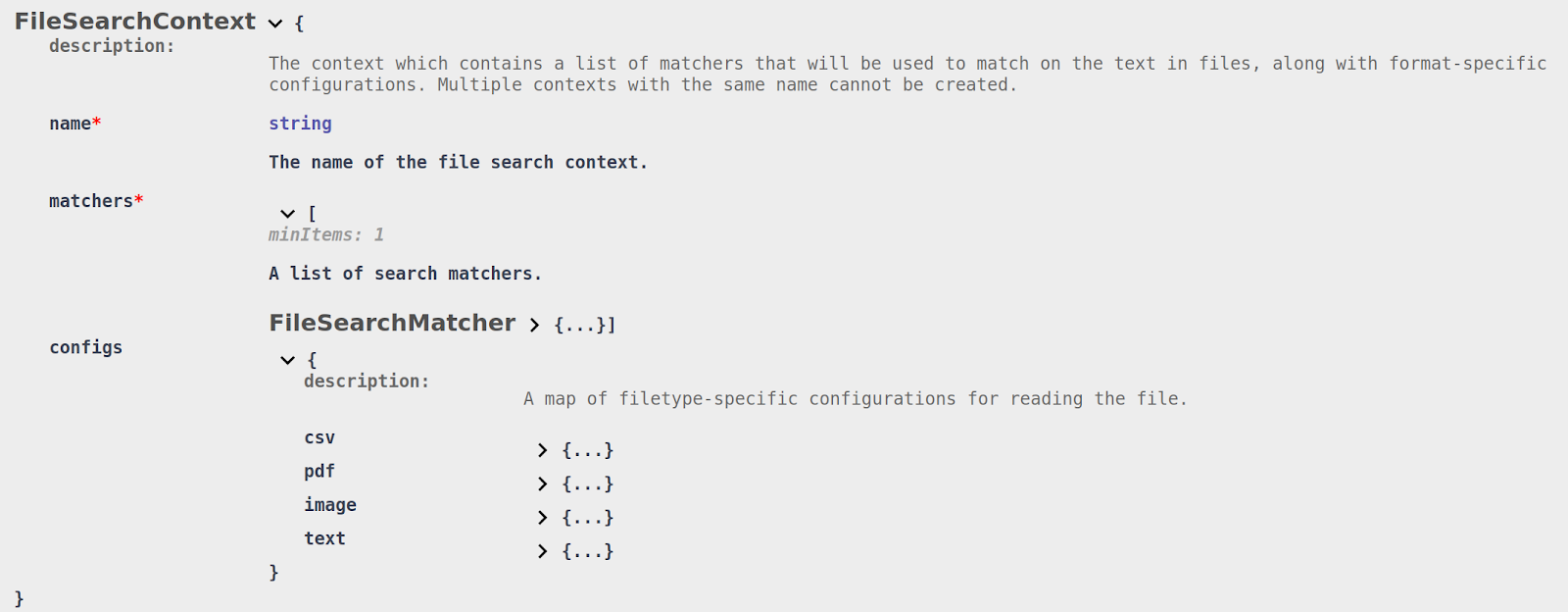
The File Search Context is structured very much like the base Search Context. The name attribute is used to uniquely identify the context when performing search operations. The matchers array contains a list of matchers used to annotate the files.
Following are the supported matchers:
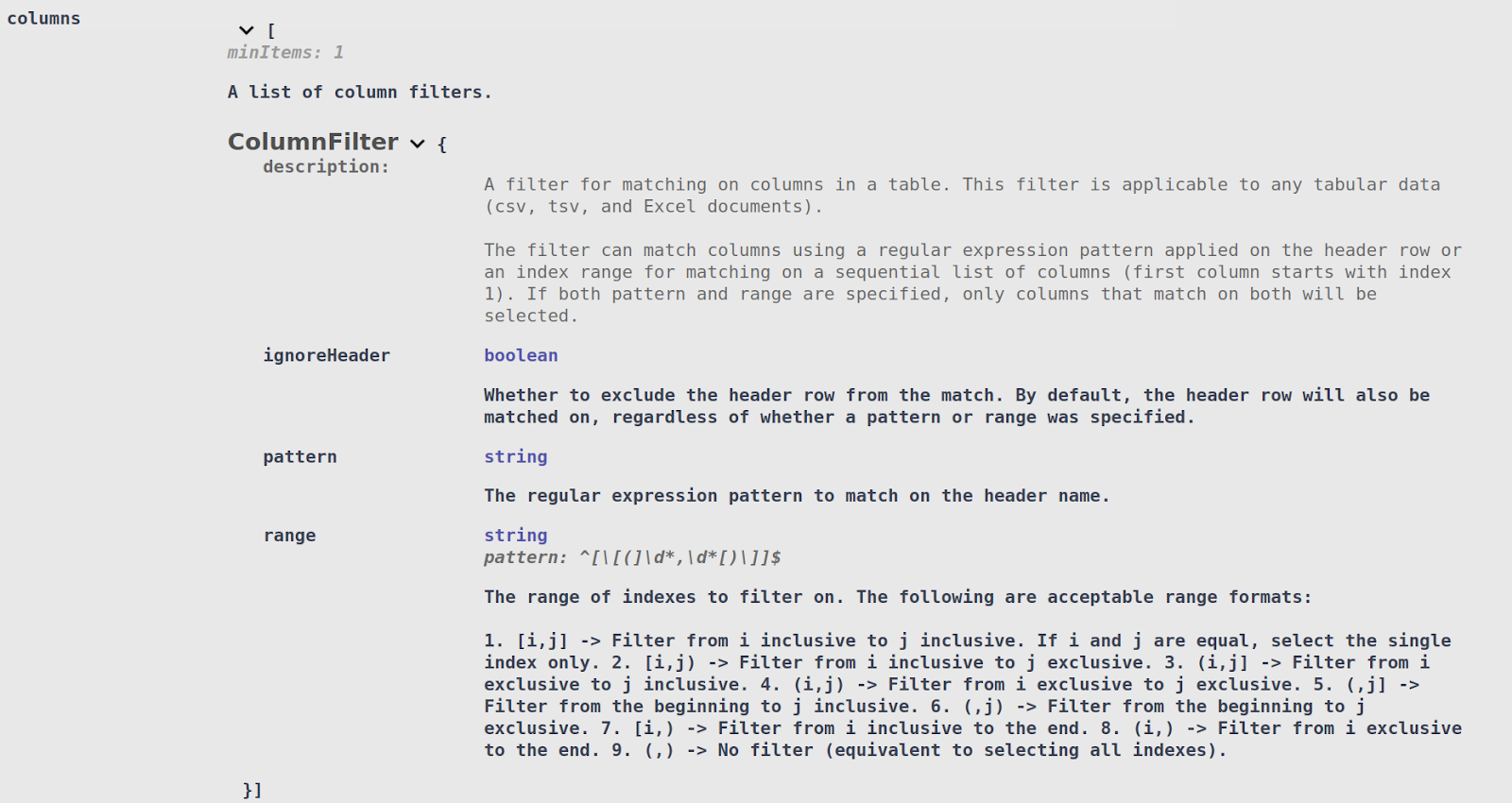
- Column Matcher (column): A matcher used in tabular files to match an entire column based on a regular expression match of the column name and/or an index range. This matcher works on delimited (CSV/TSV) files.
- Excel Cell Matcher (excelCell): A matcher for matching on cells inside of Excel sheets. There are numerous options available for filtering on the sheet name and/or index, as well as matching on specific table headers or cell addresses. Unlike standard CSV/TSV tabular data, it is also possible to match by row instead of column.
- JSON Path Matcher (jsonPath) – A matcher which matches all values found under a given JSON path. This matcher only works with JSON documents.
- Search Context Matcher (searchContext) – A matcher which delegates search tasks to a Search Context hosted in the base API (see the associated article for details of all supported search matchers). Can define additional format-specific filters for narrowing down the search to specific locations (a given json path in json documents, for example).
- XML Path Matcher (xmlPath) – A matcher only for XML documents that matches all values (within tags and attributes) found under a given XML path.
The name of each File Search Matcher will be saved with the annotations that they generate. For annotations generated by the Search Context Matcher, the names of the Search Matchers in the base API will be used instead.
Each of the format-specific matchers can also be used as filters for the matchers inside of the Search Context Matcher (#4):
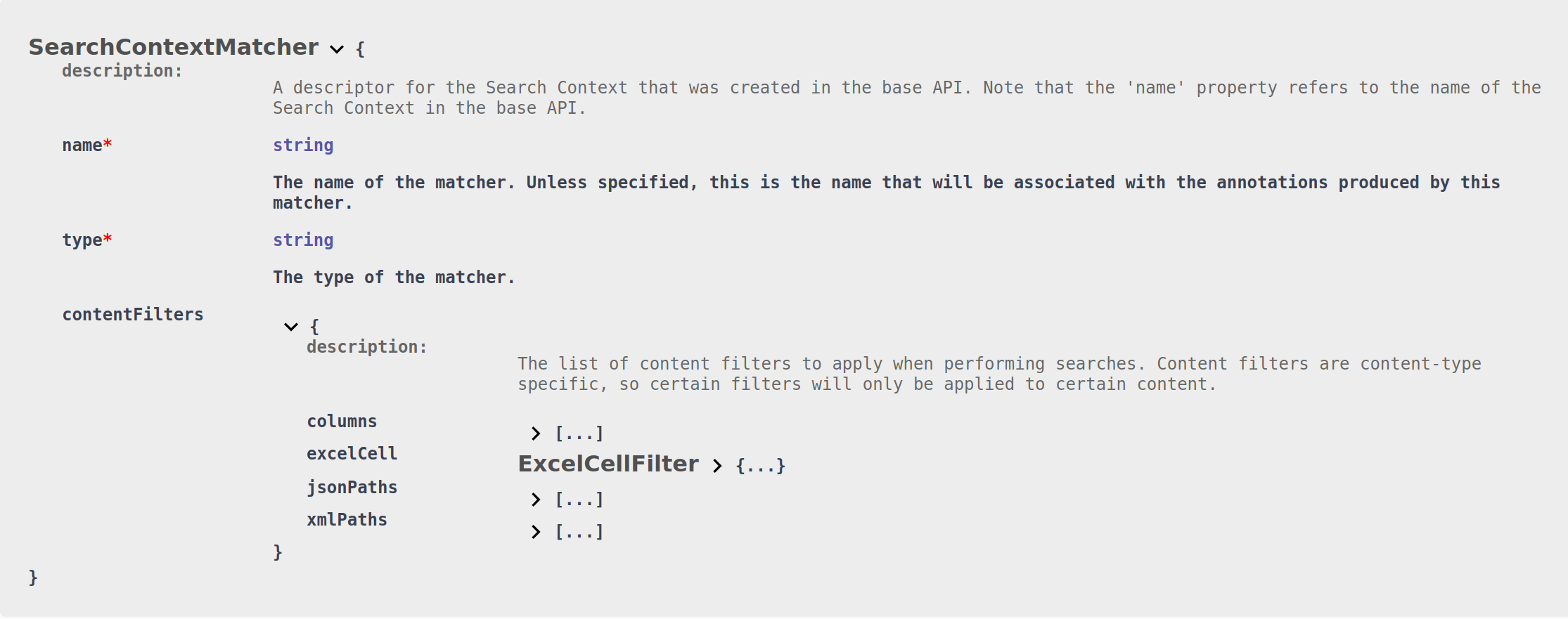
If a filter is present in the SearchContextMatcher for a specific format, the search contexts will only search through content that first matches the filter for the given file format. This can be used in a variety of different situations, for example only using named entity recognition on a comments column in a csv file, or matching only on customers’ emails inside of a deeply nested JSON file.
The last attribute within a File Search Context is the configs. This object contains format-specific configuration options for how files should be parsed.
DarkShield sets reasonable defaults for how each file type should be parsed, so it is unlikely that you will need to tweak these options except for very specific use-cases. We will go over some of these options in the file-specific sections below. File search contexts can be created by sending to the endpoint /api/darkshield/files/fileSearchContext.create.
File Mask Contexts
Just like the File Search Context, the Files API also defines an extension for the Mask Context. The following snippet of the OpenAPI definition shows the structure of its schema:
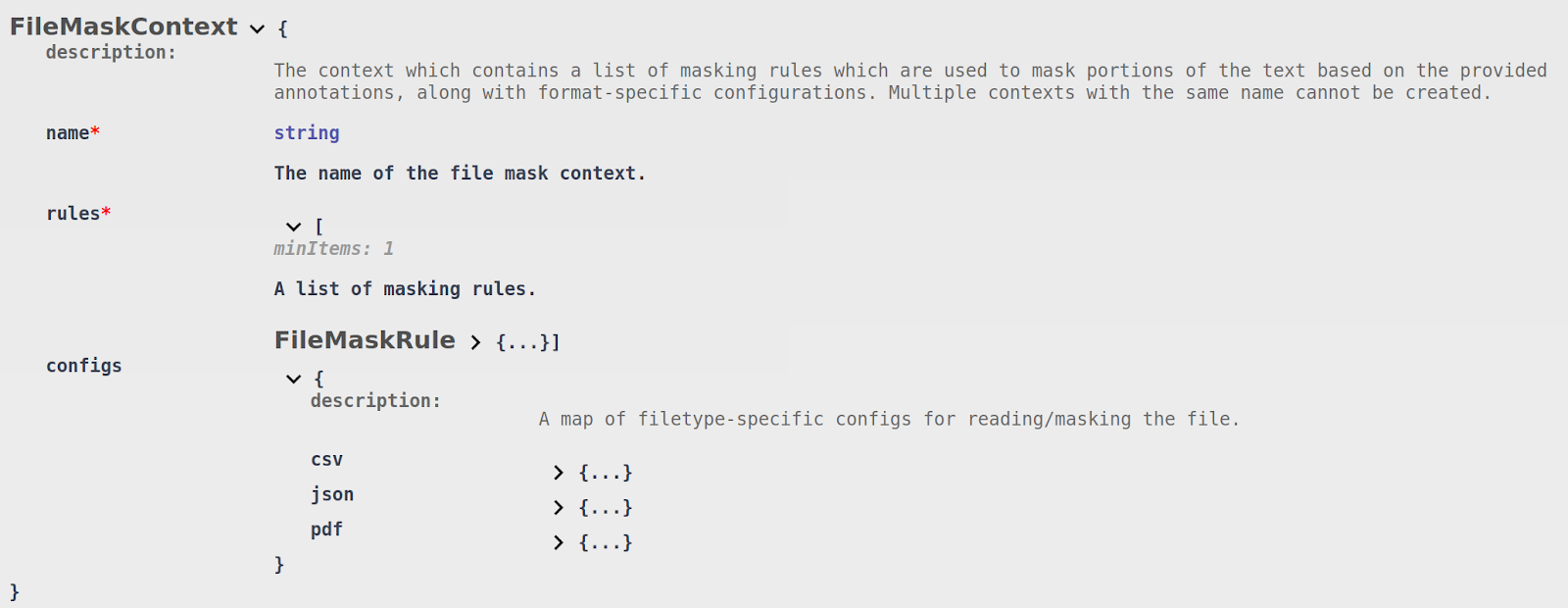
The File Mask Context is structured in a very similar manner to the base Mask Context.
The name attribute is used to uniquely identify the context when performing masking operations. The rules array contains a list of rules which will be used to mask the annotations that were found in the files.
Currently only one type of rule is supported, the Mask Context Rule, which delegates masking operations to a Mask Context hosted in the base API. Just like the Search Context Matchers in the File Search Context, the name attribute in a Mask Context Rule indicates the name of the Mask Context in the base API. The rule name applied to the mask results will be the same rule name that matched in the base Mask Context.
Also like the File Search Context, the File Mask Context contains a configs object. That object holds format-specific configurations for how the original files should be parsed (if a mask operation is being performed with an annotations.json file), or some additional masking-specific configuration options.
Some of the configuration options may be the same as their File Search Context counterparts, although in many cases DarkShield will utilize some information that is stored in the annotations.json file to parse the file in the same way as the File Search Context. File mask contexts can be created by sending to the endpoint /api/darkshield/files/fileMaskContext.create.
We will go over some of these options in the file-specific sections below.
Demo Setup
The demos below were written in Python to send requests and process responses from a locally hosted Files API. The same interactions can be simulated using any other programming language or tool which can interface with an RPC API.
The purpose of the demos is to illustrate how the API searches and masks different files, as well as how to correctly structure the requests. The sources and targets of the files vary with each use-case, and will not be the focus of this article.
The Files API utilizes multipart/form-data requests and responses to send and receive files, delegating the task of retrieving files and storing the masked files to the client (the calling program, or Python script here). This approach maximizes the flexibility of the API while reducing its complexity, since scripting these interactions is almost always easier than trying to mould the use-case to match the supported functionality of the API.
Every demo project listed below contains a setup.py file with a setup and teardown function, responsible for setting up and destroying the contexts necessary for performing the demo respectively. To execute the demo, simply run python main.py. An additional README.md is provided to describe the expected results of the execution.
Each demo produces the masked file along with its resulting results.json file, which contains the locations of the annotations and masked results. The results can be used as an audit trail, or discarded if PII retention in this form cannot be secured.
Plain Text Files (.txt)
While regular text files are deceptively simple, in some cases it is important to understand how DarkShield handles them internally.
By default, DarkShield will load, search, and mask the entire file in memory. While fast, this approach may clash with memory-constrained servers or very large files which cannot fit into memory. DarkShield therefore provides an option to process the file in text blocks.
Here is a snippet of the configuration options for text files inside of the File Search Context, as seen from the OpenAPI document:

The bufferLimit parameter is used to specify the size of the text block in characters that will be read in when performing a search. DarkShield will search for the last delimiter within the buffer limit to create a text block.
By default, the delimiter is a new line (‘\n’), although this can be set to another string. If no delimiter is found within the buffer limit, a parsing error will be returned to the client.
You can modify the bufferLimit and delimiter parameters to see how they affect the resulting results.json file.
Note that the File Mask Context does not have an equivalent text configuration for specifying these parameters. Instead, the remediator will automatically resize its buffers to fit the largest text block in the annotations.json file. In search and mask operations, the remediator will operate on the text blocks that the annotator has already read.
This demo can be found under the text-files folder. The example will search and mask email and social security number (SSN) found inside the text file using regular expression pattern matches. The email will be hashed, and the SSN will have the first 5 digits redacted.
Here is a snippet of the original file along with the masked result:
Original:

Masked:
![]()
In addition to the masked text file, the API will also return a results.json file containing the annotations that were found and how they were masked, along with any failed masking results if something went wrong:
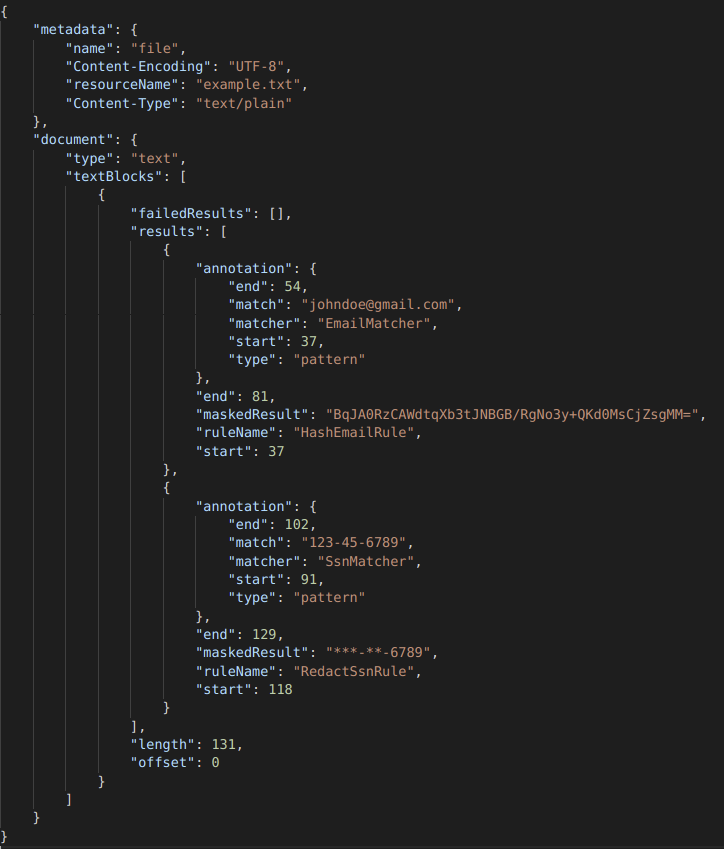
The structure of the results.json file varies for different file types. In text files, as the example above shows, the offsets are relative to the text block that the annotations were found in. We will not be showing the results.json for all subsequent examples, but one will always be generated for every file that is searched and masked.
Make sure this file is either securely stored or deleted, since it contains PII or other sensitive information.
Tabular Files (.csv, .tsv)
Tabular data often contains embedded free-form text, making it suitable for use with DarkShield. In many cases, you may also wish to combine DarkShield’s ability to mask portions of the free-form text with FieldShield’s ability to mask an entire column.
We may also want to filter on certain columns when deciding which text will be searched by a Search Context. This can reduce the number of false positives, and speed overall processing.
To match and mask an entire column in a tabular file, DarkShield supports the creation of Column Matchers:
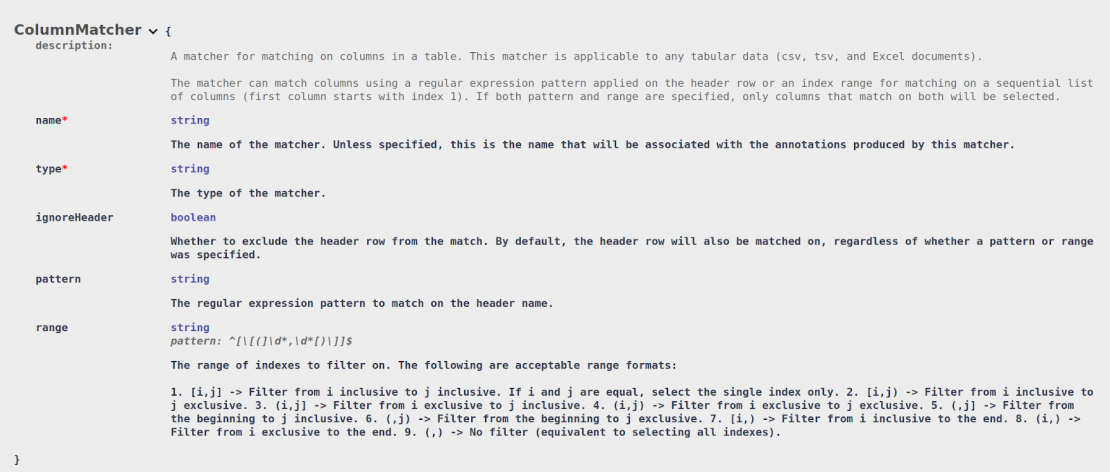
A pattern can be specified to match on particular column headers. For tabular files that do not have a header, a range of indexes can be specified. It is also possible to combine both pattern and range (for example, match on the firstName column but only if it appears in the first 3 columns).
Similarly, Column Filters can be attached to a Search Context Matcher. The Search Context Matcher will only search free form text in the columns that matched that Column Filter:
Lastly, additional CSV configuration options may be specified to improve CSV file parsing. While most CSV files follow a fairly common standard that can be automatically detected by DarkShield, in some cases it might be necessary to tweak certain options:
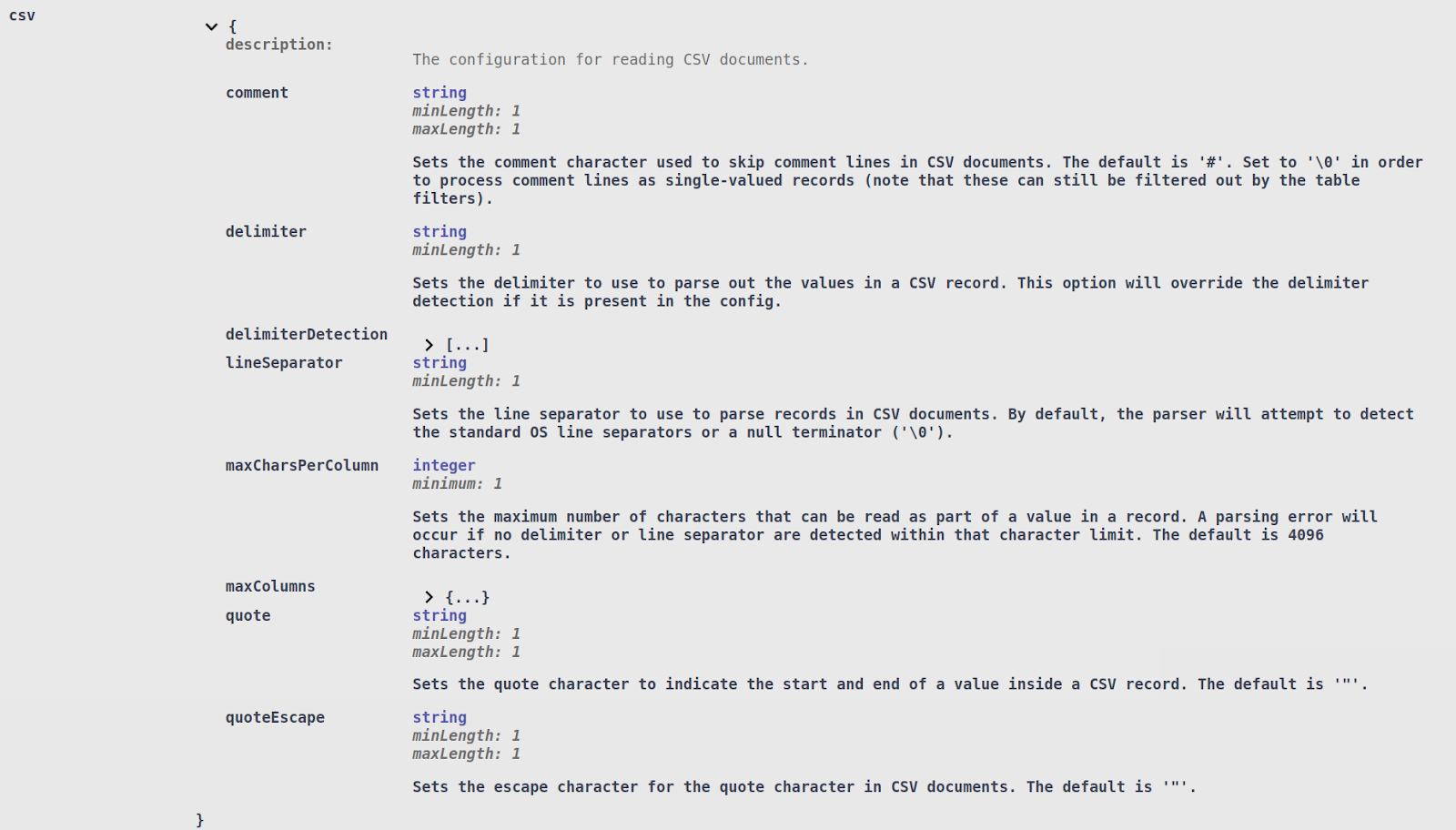
All standard CSV parsing options, like the delimiter and quote characters, can be configured. For very large CSV files, it may also be necessary to set the maximum size of any given column entry (maxCharsPerColumn), or the maximum number of columns (maxColumns), so that DarkShield can adjust its internal buffers accordingly.
The File Mask Context can also be configured with the same options, since it may need to read the CSV file on a subsequent masking run (if search and masking was not done in one step). However, by default, the File Mask Context will always attempt to use the CSV configuration options saved in the metadata object inside the annotations.json file, if available.
The demo can be found under the csv-tsv folder. The example will search and mask the following:
- Emails (EmailsMatcher): regular expression pattern matcher with hashing rule.
- Names (NamesMatcher): Using a column matcher on any column ending with ‘name’, and a Named Entity Recognition (NER) matcher to search through the comment field using a column filter (all names are masked using format-preserving encryption).
Note that this CSV file appears more structured, while the TSV file shows off some of the more non-standard cases that DarkShield can handle. Both contain the same information, and will be masked in the same manner.
Here is a snippet of the original CSV file along with the masked result:
Original:

Masked:

And here is the snippet of the original tsv file along with the masked result:
Original:

Masked:

Fixed-Width Files
Fixed-width text files are text files that are formatted with columns and each column has an absolute length. Each row in a fixed-width text file must adhere to the format for column widths. Column widths themselves can vary amongst each other in width. Unlike TSVor CSV files, fixed-width files do not use characters to delimit columns and each row is the same length.
To specify the column widths for the fixed width document there is a fixed-width configuration called columnWidths that will take an array of values.
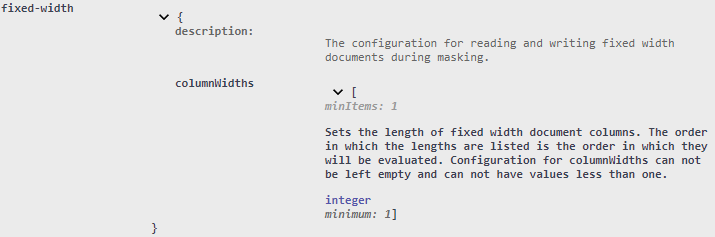
The columnWidths configuration will require at least one item in the array and the value for column width must not be less than one character in length.
The demo can be found under the fixed-width folder. The example will search and mask the following:
- Emails (EmailsMatcher): regular expression pattern matcher with format preserving encryption rule.
- Social Security Numbers (SsnMatcher) regular expression pattern matcher with a redaction rule.
Below is a view of the original fixed width text file followed by the masked result:


HL7 Files (v2)
The Health Level Seven (HL7) standard was conceived for the purpose creating a standard format for exchanging electronic health information. HL7 first appeared in the 1980’s and since then several versions of HL7 have been released. As of now, the DarkShield-Files API is able to support HL7 v2 along with the already supported HL7 v3 (HL7 v3 was already supported by virtue of its XML format).
A HL7 v2 message is strictly structured, and is broken down into segments, composites (fields) within segments, and sub-composites (sub-fields). An HL7 message must always start with a message header segment (MSH). The HL7 MSH segment contains information about the message, including what delimiters will be used in the message (e.g. ‘|^~\&’). Each line starts with a new segment and has a segment identifier (e.g. PID, MSA, NK1) at the beginning of the segment. Segments are split into composites (fields) using a composite delimiter and in most cases is a pipe delimiter. Within composites are sub-composites split up by sub-composite delimiters.
Usually the DarkShield Files API will search and mask an entire file based on what is found by the searchMatchers. That said, there are instances when a user may wish for masking to be more specific. For example, there are requirements that dictate that the patient’s name and the name of next of kin should be masked but not the name of the primary care provider. In these situations the DarkShield-Files API supports the ability to specify specific columns within specific rows to mask, instead of masking the entire document.
To accomplish the masking of specific fields within specific rows, a Column Matcher is specified in the file_search_context.
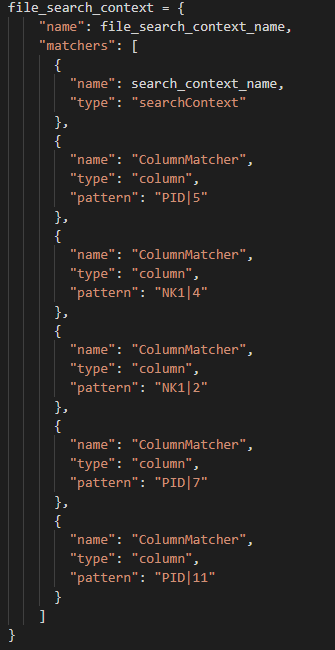
File Search Context of HL7
When targeting a specific column in a segment, note that the syntax for the column matcher uses a pipe delimiter to separate the segment identifier from the target column. Regardless of whether a pipe delimiter is used as a field delimiter in the document, this will be the syntax to indicate the specific column within targeted segment that will be masked by the API.
Below is a snapshot of an original HL7 message followed by the masked result:

Original HL7 Document

Masked HL7 Document
Below are links to a demo and to an article discussing HL7 v2 support with DarkShield-Files API:
X12 Files
X12 is a common format for electronic business documents, and is also in use in the healthcare industry. Every X12 document has a three-digit identifier to notify the receiver of what information it contains (e.g. X12 835 Health Care Claim and Remittance Advice).
The structure of a X12 message consists of segments, elements (fields) within segments, and composite elements (sub-fields) within elements. Each segment will have a segment identifier and a segment delimiter that is placed at the end of the segment. Within the segment are element delimiters that split the segment into elements. The elements can then be divided further into composite elements using a composite element delimiter.
As a rule, a X12 message must always start with an Interchange control header (ISA segment). The ISA segment contains information about the message including at the end of the ISA segment, a list of the delimiters that will be present in the message. Directly following an ISA segment is the Functional Group Header segment(GS) which is also called the inner envelope.
Usually the DarkShield Files API will search and mask an entire file based on what is found by the searchMatchers. That said, there are instances when a user may wish for masking to be more specific. In these situations the DarkShield-Files API supports the ability to specify specific columns within specific rows to mask, instead of masking the entire document.
To accomplish the masking of specific fields within specific rows, a Column Matcher is specified in the file_search_context.
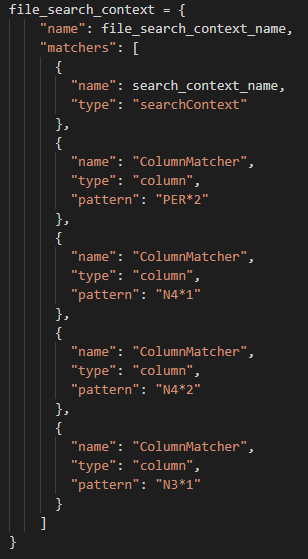
File Search Context of X12
When targeting a specific column in a segment, note that the syntax for the column matcher uses an asterisk delimiter to separate the segment identifier from the target column. Regardless of whether an asterisk delimiter is used as a field delimiter in the document, this will be the syntax to indicate the specific column within targeted segment that will be masked by the API.
Below is a snapshot of a X12 835 message unaltered followed by the masked result:
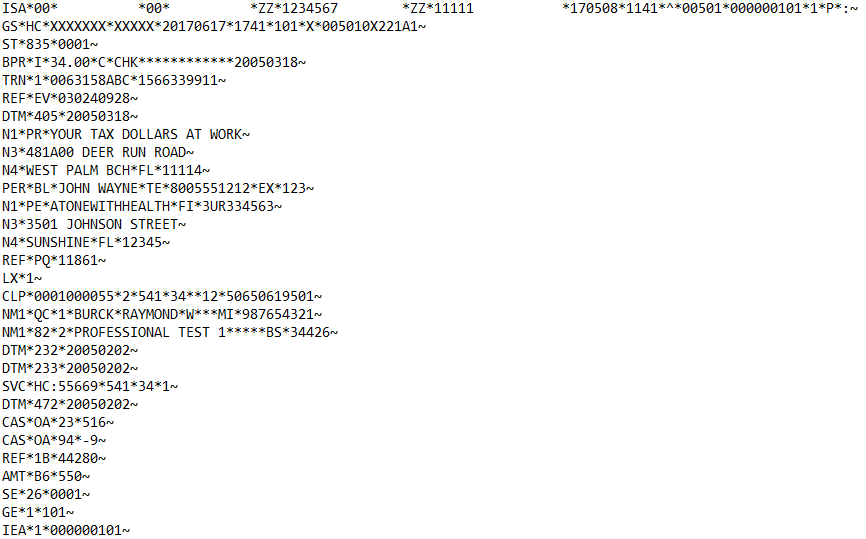
Original X12 835 Document
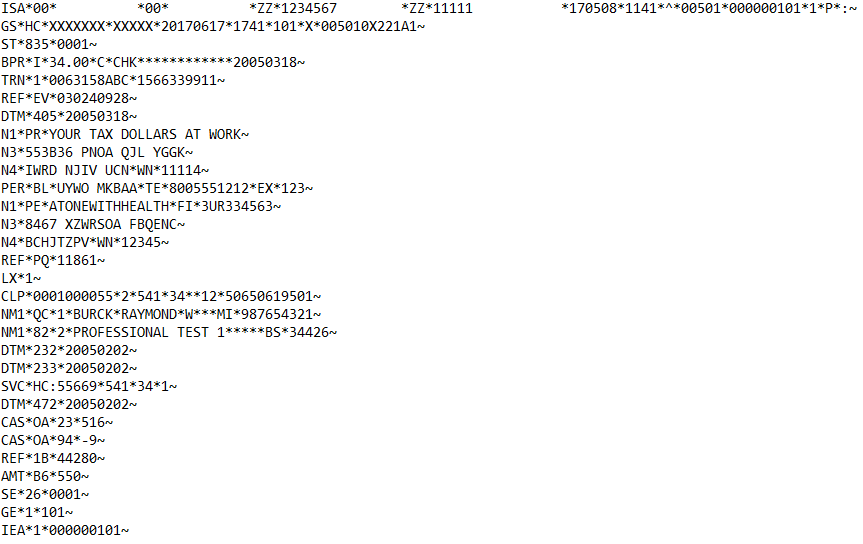
Masked X12 835 Document
Below are links to a demo and to an article discussing HL7 v2 support with DarkShield-Files API:
Semi-structured Files (.xml, .json)
Semi-structured files are a popular format for storing unstructured data due to their flexibility compared to traditional tabular or relational structures. The Files API is capable of handling semi-structured files with arbitrary nesting and can search and mask free-form text found with json values or xml tags and attributes.
In some cases, you may also wish to mask a value based on the name of the key in json files or the tag and attribute in xml files, similar to FieldShield’s approach to masking. Finally, you can also filter on which values will be searched by a Search Context using json/xml paths.
To achieve the first use case, DarkShield supports the creation of JSON Path Matchers and XML Path Matchers to match on an entire value for keys that match a json path in json documents and for tags and attributes that match an XML path in XML documents:
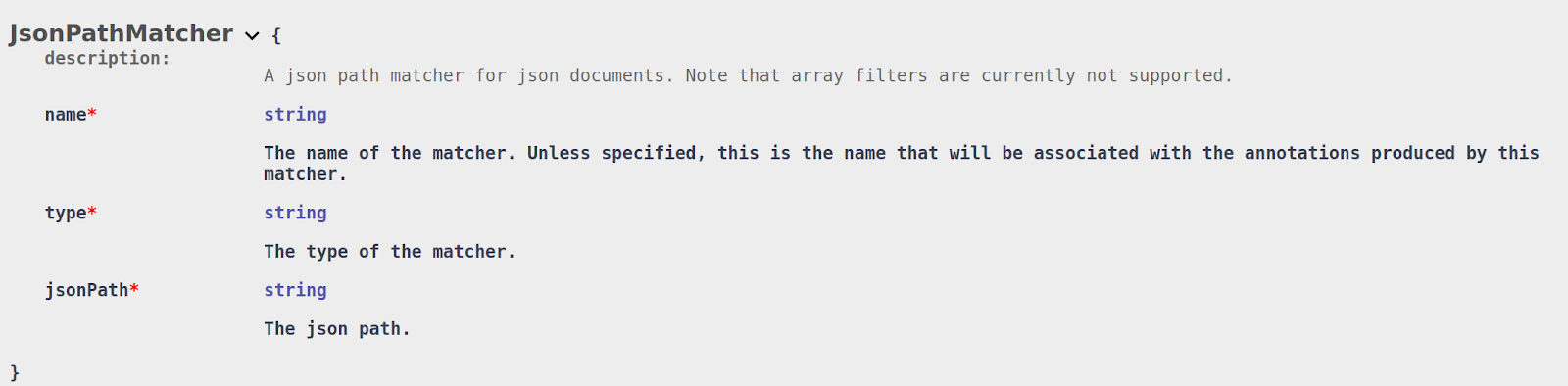
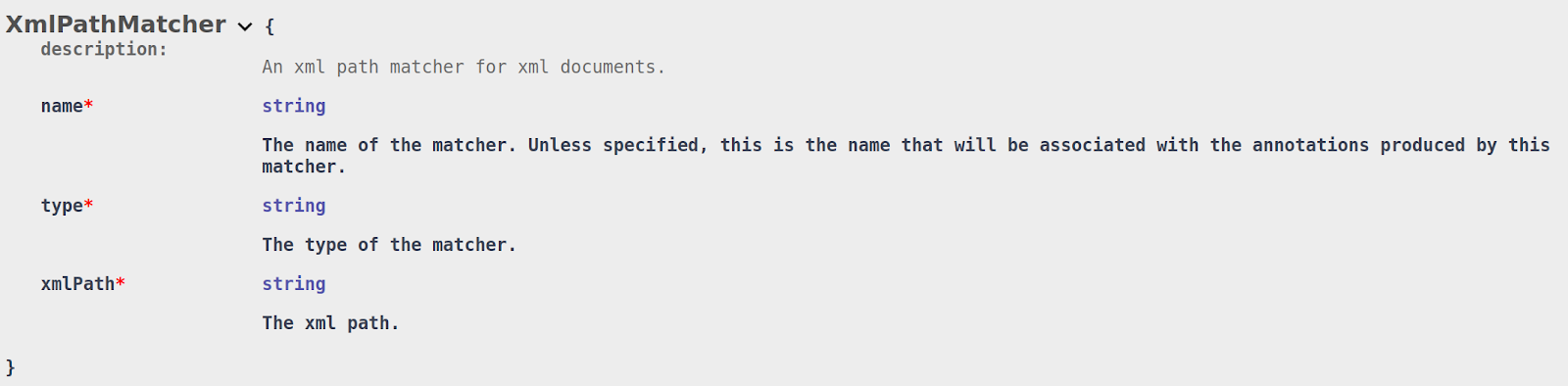
If the json/xml path resolves to a sub-tree, all values under the sub-tree will be masked.
Similarly, JSON Path Filters and XML Path Filters can be attached to a Search Context Matcher. Instead of matching on the entire value, the Search Context will be used to search mask portions of the free-form text found within:
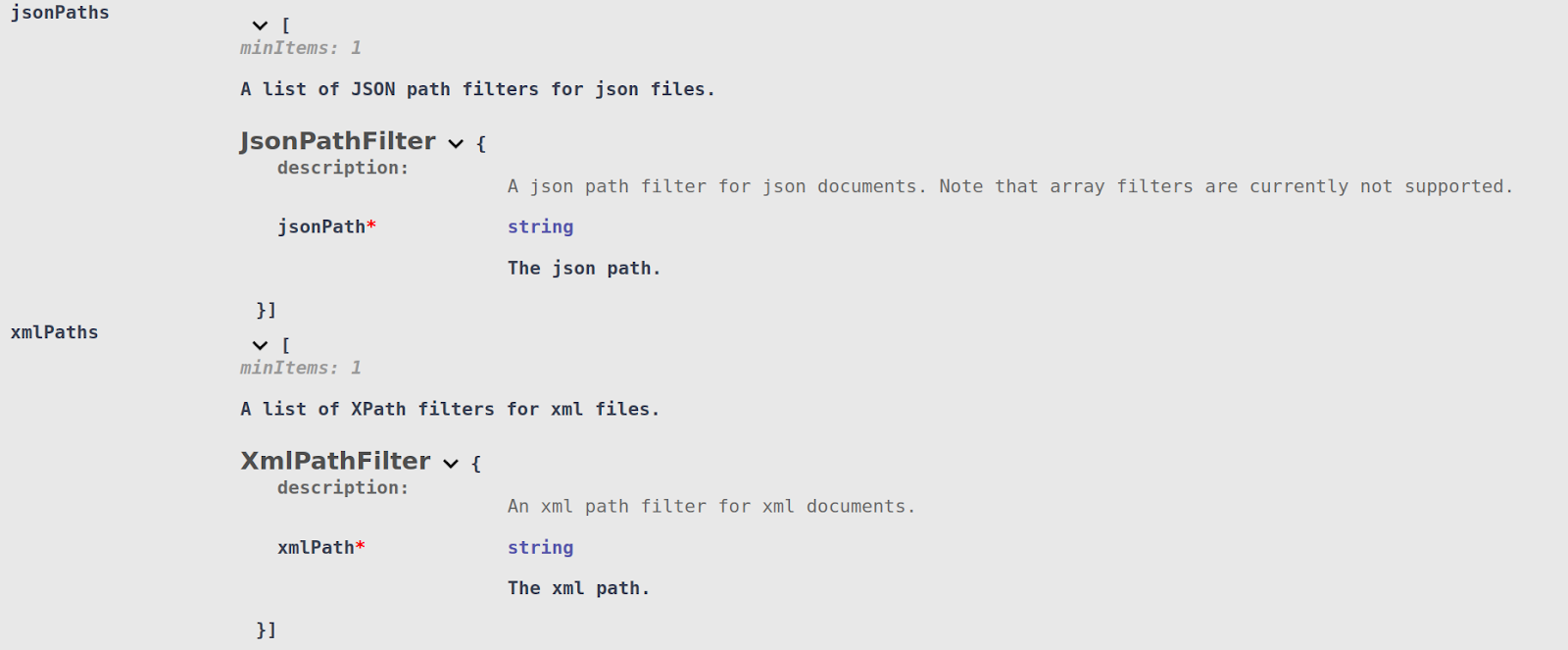
Note that as of this writing, using XML Path Matchers or Filters will force DarkShield to load the entire XML file into memory in order to extract the correct tags and attributes. The JSON Path Matchers and Filters process JSON in a streaming fashion, but currently do not support array filters (for example, $..name[2:]).
There are currently no parsing configuration options for either JSON or XML in the File Search Context. However, in the File Mask Context you can specify whether the JSON output should be pretty-printed (properly indented) using the prettyPrint parameter:

By default, masked JSON documents are written out in a compact format by removing any extraneous whitespace. XML is written out in the same format at the input.
The demo can be found under the json-xml folder. The example will search and mask the following:
- Emails (EmailMatcher): Found using a regular expression and masked using a hashing function.
- Phone Numbers (PhoneMatcher): Found using a regular expression and masked using format-preserving encryption.
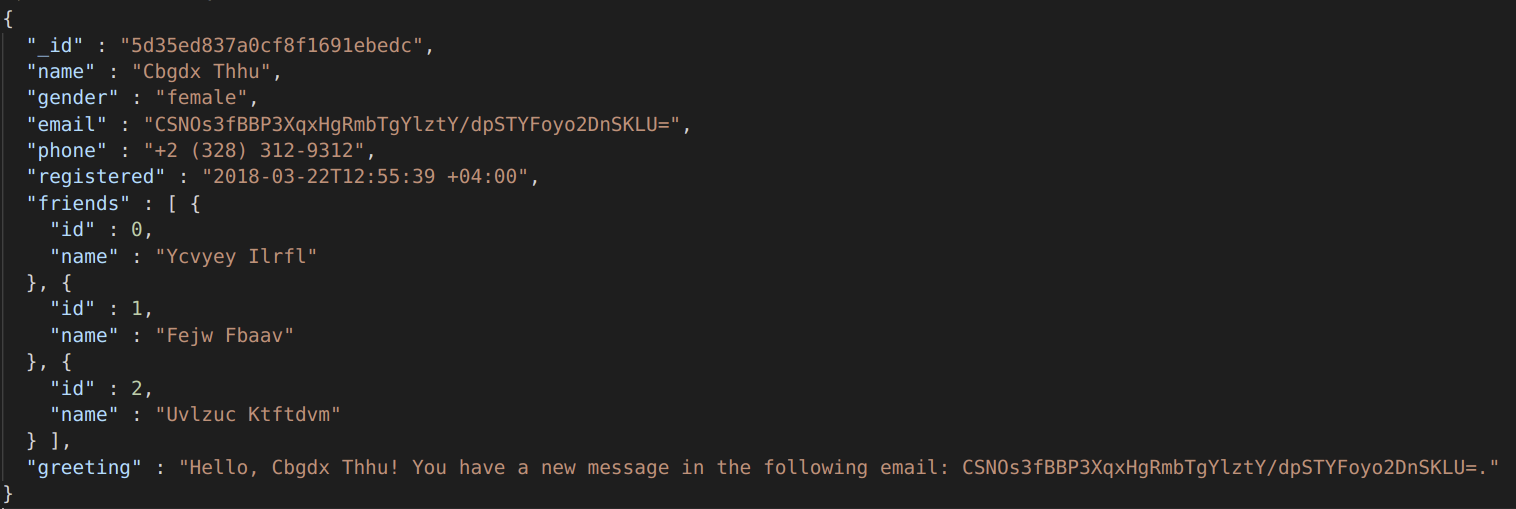
- Names (NameMatcher): Found using a Named Entity Recognition (NER) model AND using format-specific JSON/XMLpaths (all names can be found in the ‘name’ key/tag, regardless of nesting).
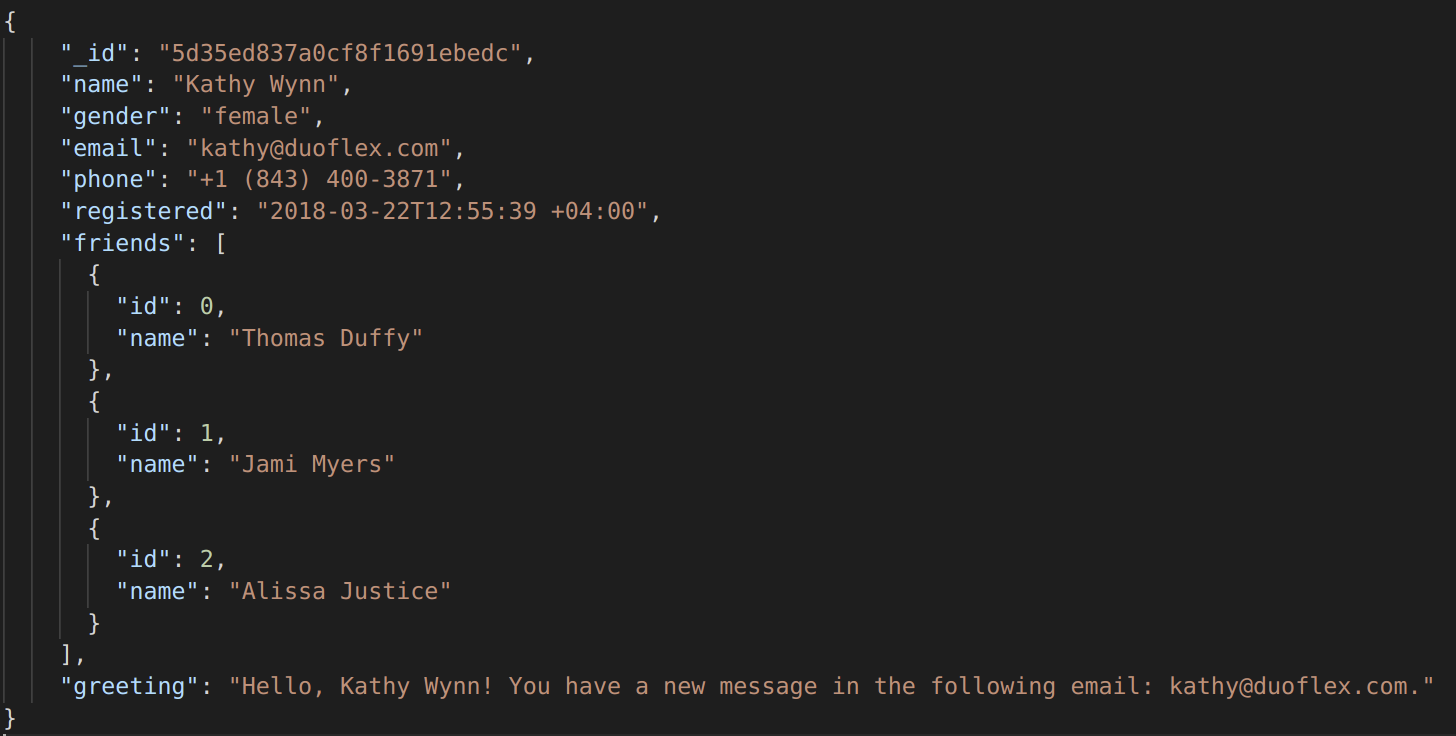
Here is a snippet of the original JSON file along with the masked result:
Original:
Masked:
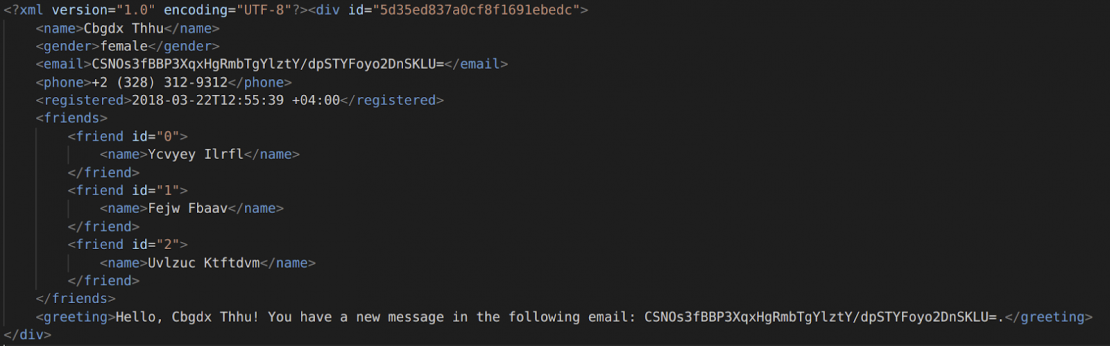
And here is a snippet of the original XML file along with the masked result:
Original:

Masked:
Microsoft Office Documents (Excel, Word, PowerPoint)
DarkShield supports searching and masking PII found inside Word documents, Excel spreadsheets, and PowerPoint presentations. This includes the older binary (.doc, .xls, .ppt) as well as the newer OOXML (.docx, .xlsx, and .pptx) formats. In addition to text found inside of the pages, sheets, or slides, DarkShield can also search and mask certain embedded objects within, for example charts and images.
Due to certain limitations with the older binary formats and the lack of official documentation, DarkShield does not support the full range of capabilities for .doc, .xls, and .ppt that are present in their OOXML counterparts. In particular, DarkShield cannot search and mask embedded charts within .doc and .xls files, .doc files only support searching but not masking embedded images., and .ppt files cannot mask notes.
Due to their internal structures, the older binary formats also have to be loaded fully into memory in order to be read and modified. This is in contrast to the newer versions which are streamed, meaning that DarkShield can handle them in memory more efficiently.
This should generally not be a problem, since the older formats have hard limits on their file size, but it is important to keep this in mind when processing multiple files at the same time to avoid running out of memory.
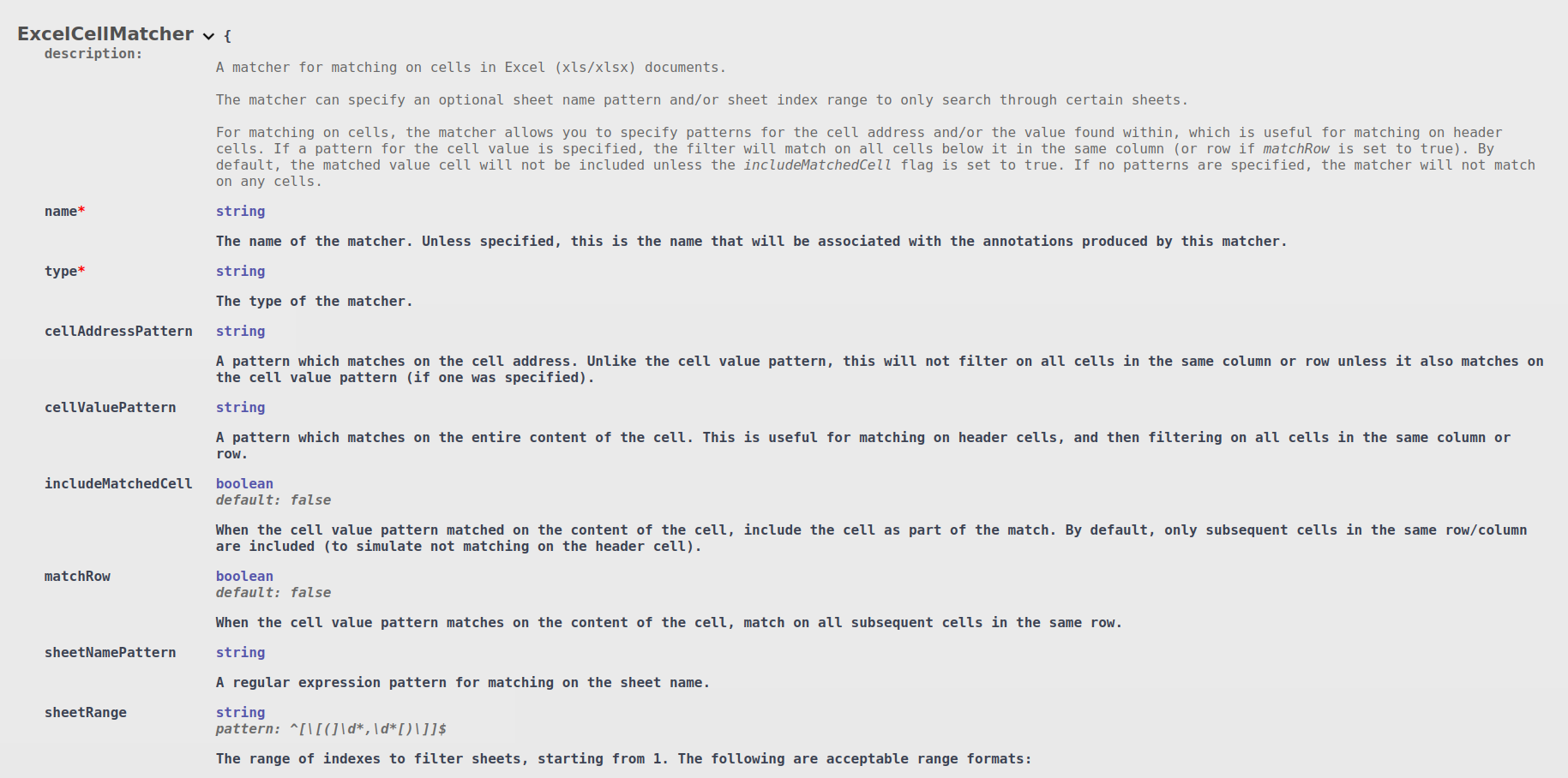
DarkShield provides additional support for finding PII in spreadsheets using its ExcelCellMatcher and ExcelCellFilter respectively. DarkShield can match or filter on rows or columns of data with a pattern-matched header stored as a value inside of a cell.
A regular expression can also be specified to match on specific ranges of cell addresses. These matchers and filters can also be applied to only specific sheets in the file by using a regular expression pattern on the sheet name or the sheet’s index range:
To demonstrate some of these capabilities, you can refer to the microsoft-excel-and-word demo project which contains a collection of Office documents.
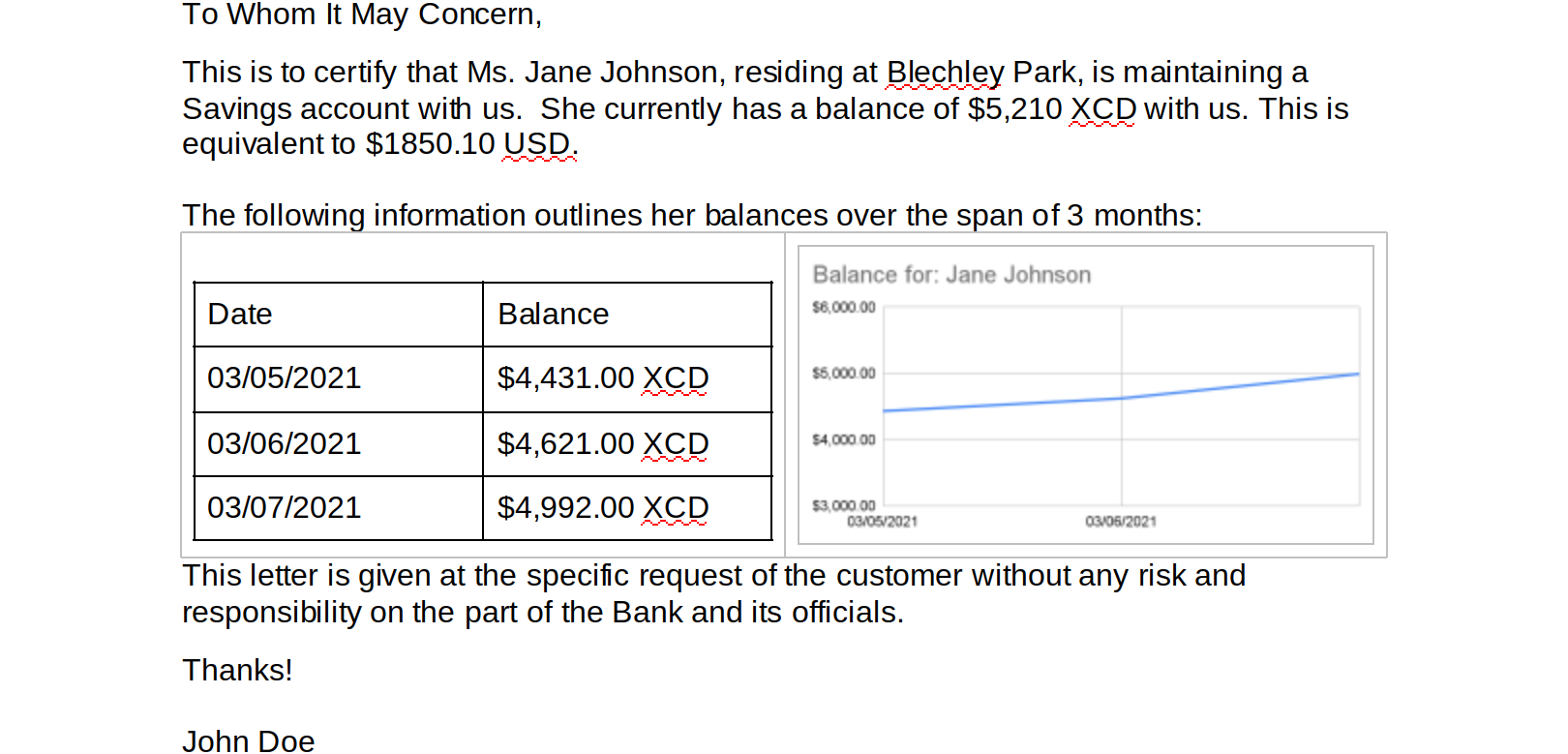
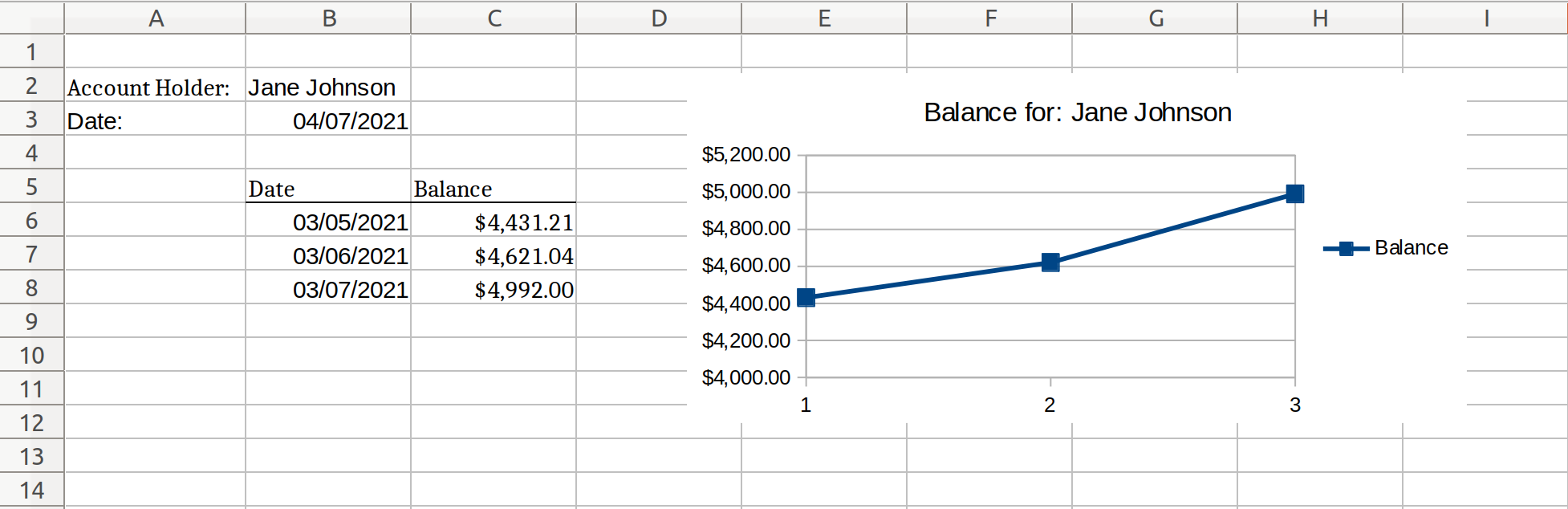
Both word documents contain a contrived bank statement that contains information regarding the account holder. The .docx version also contains a table and a graph containing which details the account holder’s balance over the span of three months:
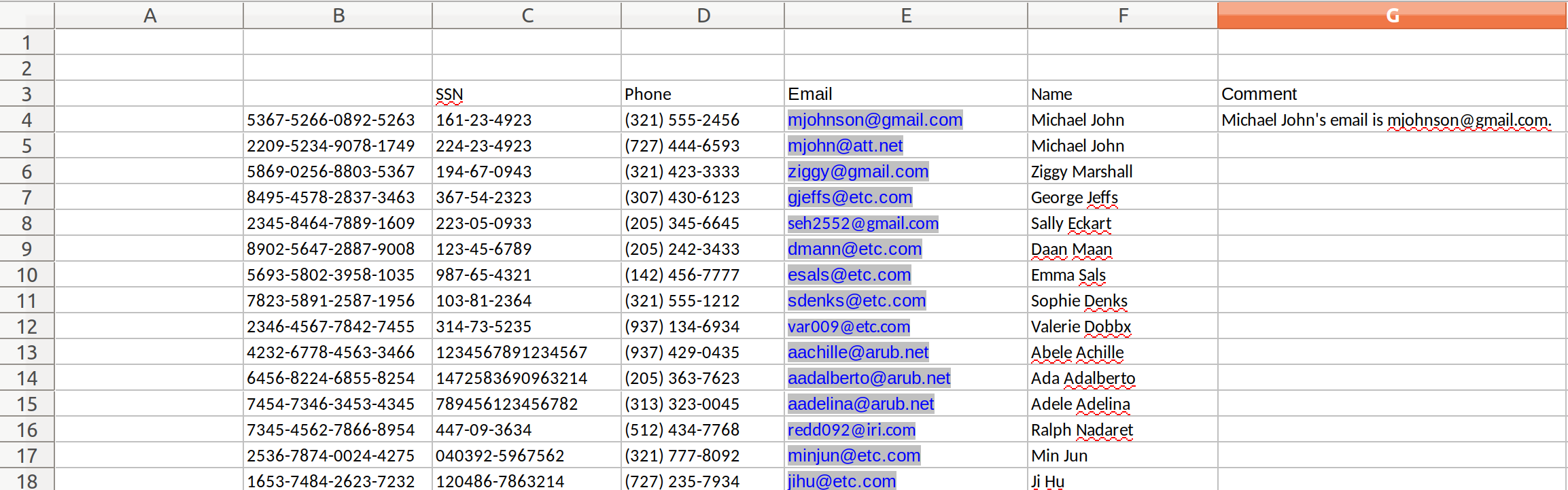
buyers.xls contains a standard tabular sheet containing a mix of structured data and free-form text (note the mailto hyperlinks that are stored alongside the emails):
Finally, Bank Report.xlsx contains the same tabular data and embedded graph which are present in Bank Statement.xlsx:
In addition to the standard regular expression pattern matching and named entity recognition used in other examples, we will also exploit the structure of the buyers.xls spreadsheet to match on the account number using a cell address pattern matching on column B, as well as a cell value pattern match on the Name column.
Below are the masked versions of these documents:

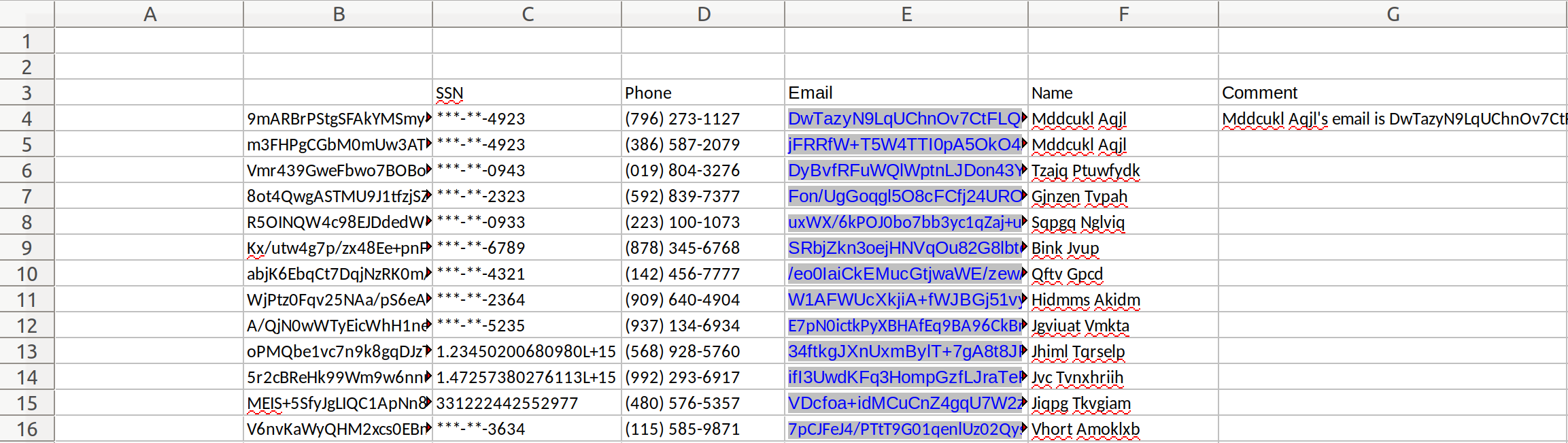
buyers.xls:
Bank Report.xlsx:
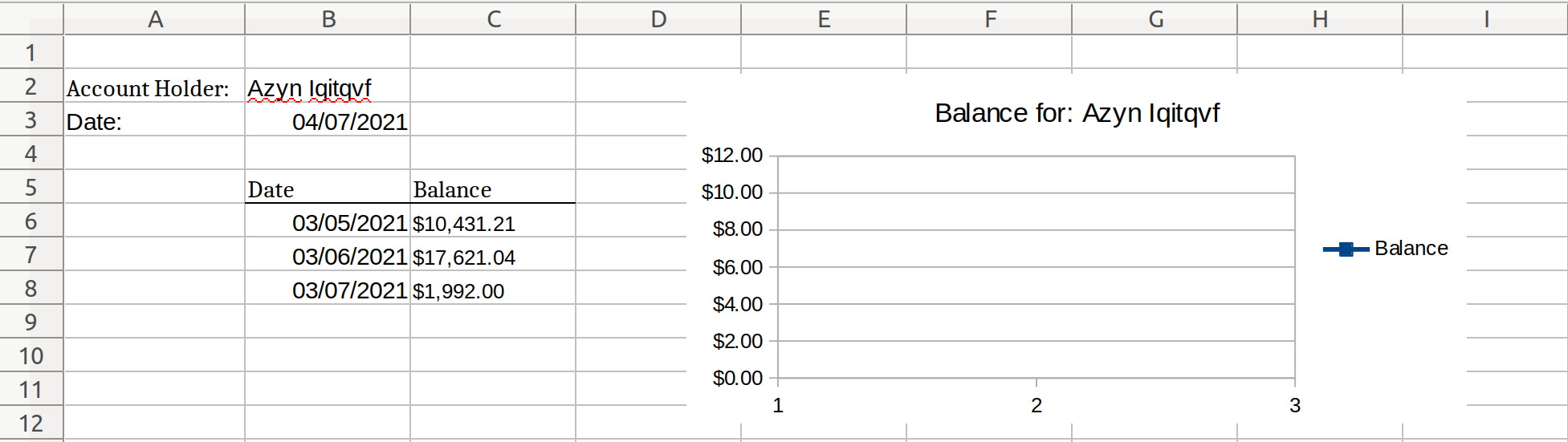
There are several things to note from the masked examples:
- A random offset was added to the balances in both documents, meaning that the numbers will not necessarily be consistent between different documents or separate demo runs. There are ways to apply a more consistent masking to these values (for example, format-preserving encryption).
- The masked balances are stored as string data rather than as floating-point numbers with a currency format (the internal representation within Excel). This means that the chart will no longer display information since the balances are no longer numbers. Future additions to DarkShield may allow for more conversions of masked string data to a formatted floating-point value under certain circumstances.
- Note how column B in Bank Report.xlsx is not matched on and masked as an account number. This is due to the sheet name filter that was also added to the account number excel cell matcher which limited its matches to cells found in the buyers sheet.
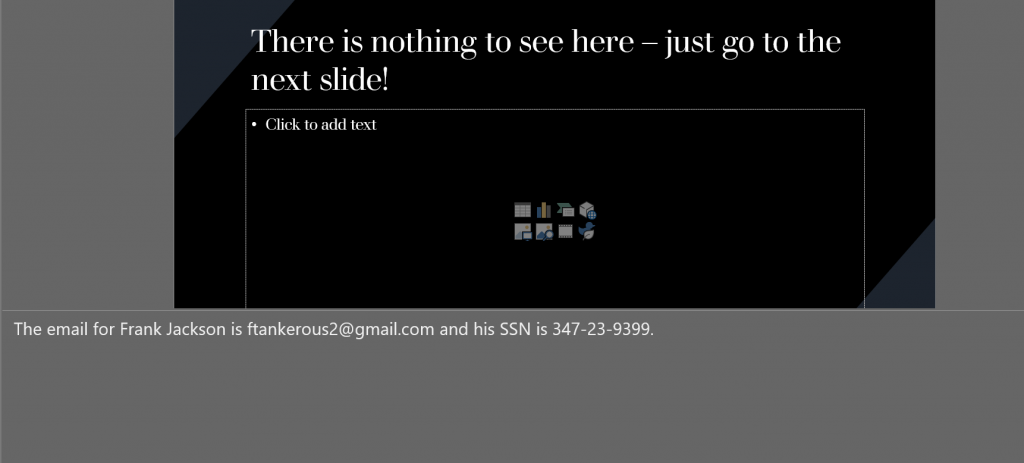
There is also a separate demo for powerpoint.
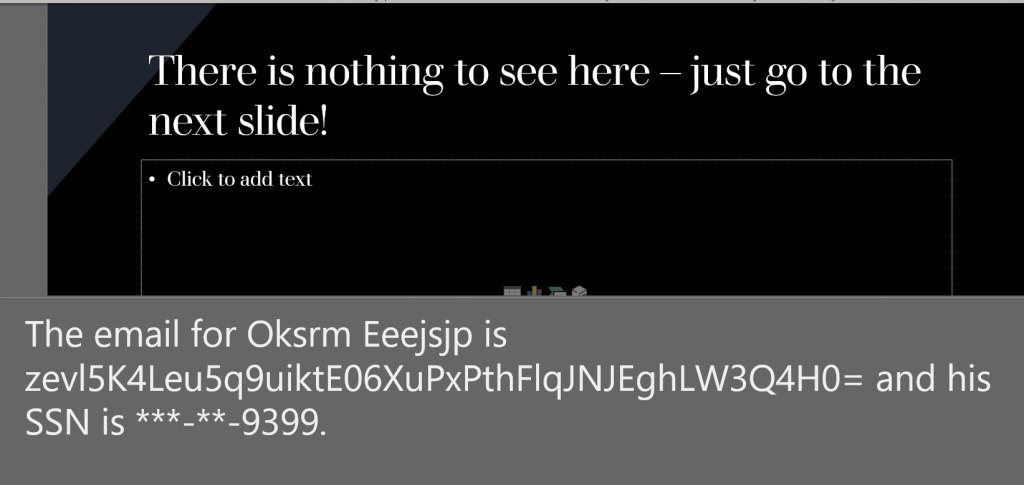
The PowerPoint demo is looking for names, social security numbers, email addresses, and credit card numbers within text, notes, tables, footers, and images within the slideshow.
Compare the content of some of the original slides with the masked slides:





Parquet File Format
Apache Parquet is a columnar, compressed file format that is optimized for performance. Parquet files are often found in cloud storage providers due to the optimizations of the file format that reduce costs in cloud environments when compared to CSV files.
While designed for rapid analytic querying and low disk space usage, Parquet is a complex binary format that is not easily readable, which may make it difficult to protect sensitive data.
However, the DarkShield Files API offers the capability to search and mask Parquet files for sensitive data. The Parquet file format allows for many data types and nested data structures; the DarkShield Files API is able to search and mask through common primitive types such as strings, integers, bytes, etc. as well as multiple levels of nesting.
The implementation of Parquet file format support in the DarkShield Files API was designed with bulk usage in mind. Many Parquet files are quite large, but if the size of each row group is limited to a reasonable size (a typical recommended amount is no more than 128 MB), the maximum memory used will be closer to the size of the row group than the size of the entire file.
This demo can be found in the parquet demo folder here.
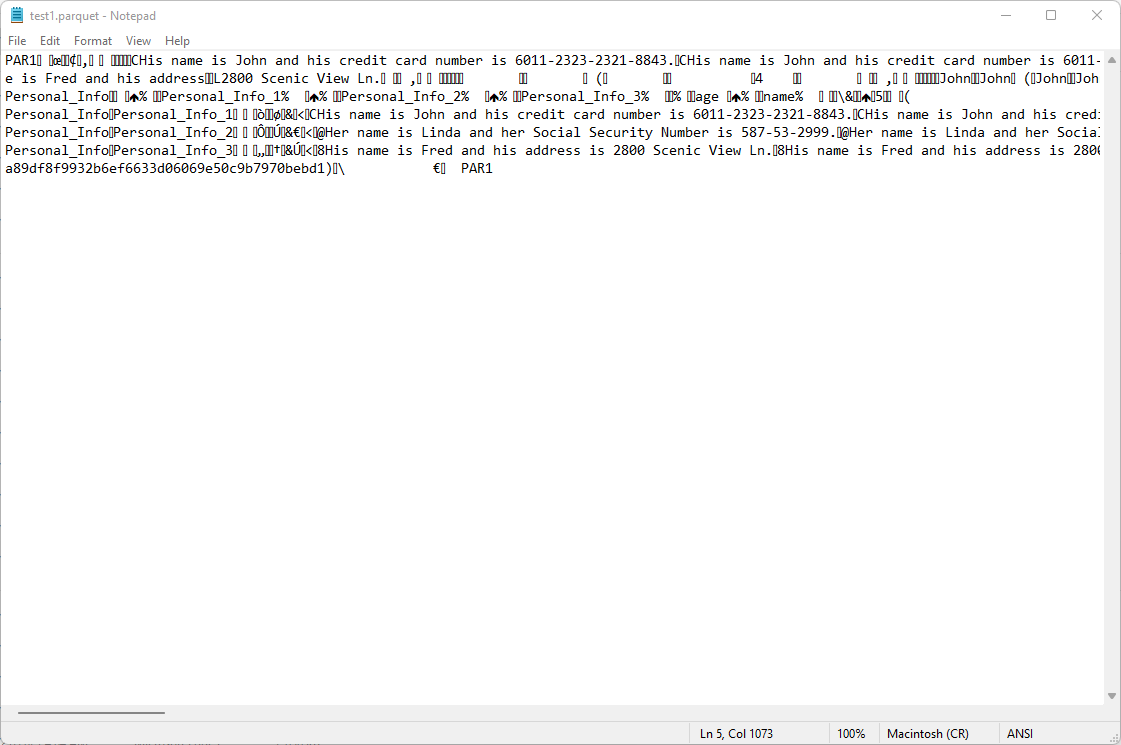
The demo has two Parquet files, of which one is a ‘flat’ Parquet file which has a single field for each column, while the other file has nested fields in one column.
Viewing one of the Parquet files in a text editor reveals the format – some string text is visible, but there is a lot of binary encoding as well.
Looking at the same file in a Parquet file schema viewer shows this schema structure:
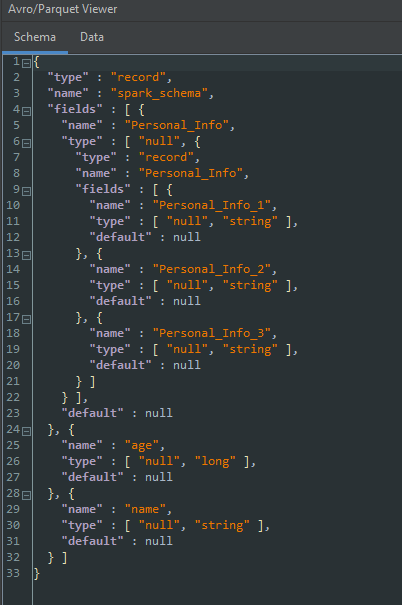
This is the Parquet file with nested fields in one column.
After using Python to run the main.py script inside the parquet demo folder, the resulting masked version of the previously shown file is shown here in a Parquet viewer:

Note that:
- The names and the Social Security number have been encrypted with format-preserving encryption.
- Certain other data that could be classified as sensitive (such as age, credit card number, and address) have been purposely left alone in this example.
- Users can classify data however they want to so that only what is needed to be masked will be masked, leaving other parts of the data field that are deemed as non-sensitive usable.
DICOM Files
DICOM, or Digital Imaging and Communications in Medicine, is a standard for the communication and management of medical imaging information and related data.
DICOM is implemented in almost every radiology, cardiology imaging, and radiotherapy device (X-ray, CT, MRI, ultrasound, etc.), and increasingly in devices in other medical domains such as ophthalmology and dentistry.
DICOM defines individual files (typically having a .dcm file extension) that have a unique binary structure consisting of a header and a data set consisting of a list of attributes. The attributes include information about the scan such as the patient name. The final attribute is the actual pixel data (imagery) of the scan.
DarkShield offers a solution for searching and masking sensitive attributes in a DICOM file.
Pixel data is just one of many attributes that may be contained in a DICOM file, and is separate from other attributes that may contain key- or quasi-identifiers such as patient name, date of birth, and hospital name. DarkShield will search through all attributes that are not a part of the pixel data.
Additionally, a series of black boxes may be specified in a file mask context to redact known portions of pixel data that may have sensitive information in burned-in text. The height, width, and X and Y coordinates of each black box can be specified in the configuration.
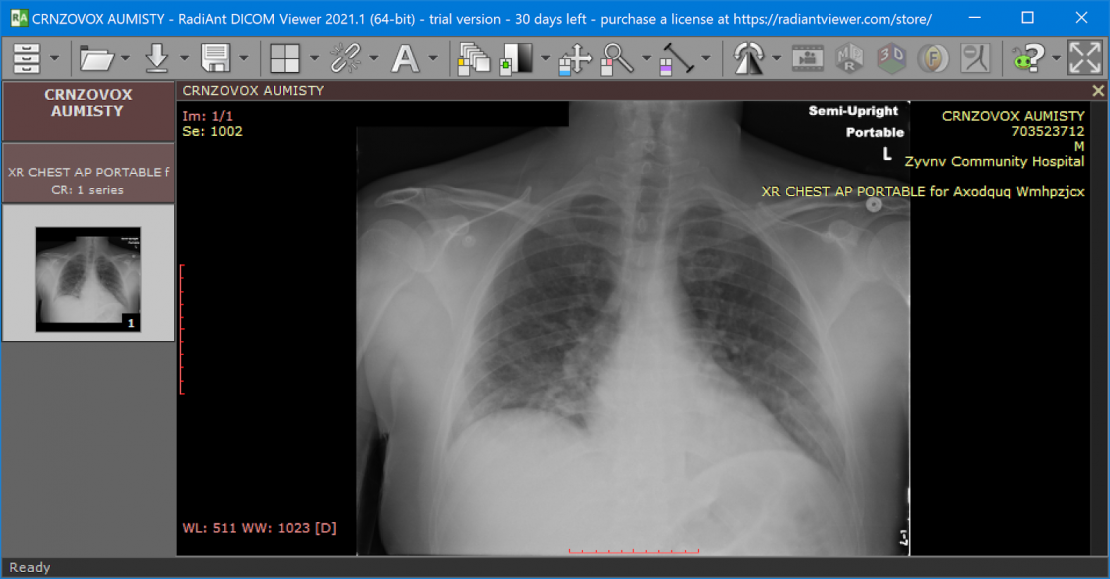
The example below shows patient information in a DICOM file being de-identified by processing with the DarkShield-Files API. The file contains burned-in text with the patient’s name and other sensitive information. Additionally, DICOM files have attributes containing identifying information of the scan that are not a part of the pixel data, but are overlayed onto the image when displayed in a DICOM viewer. A black box was defined as a configuration to the DarkShield-Files API to remove the burned-in text from view. Attributes that get overlayed onto the image, but are not actually a part of the image, were searched through and masked based on the text contents of the attributes. The results of a DICOM file being de-identified with DarkShield are shown below.
Original:
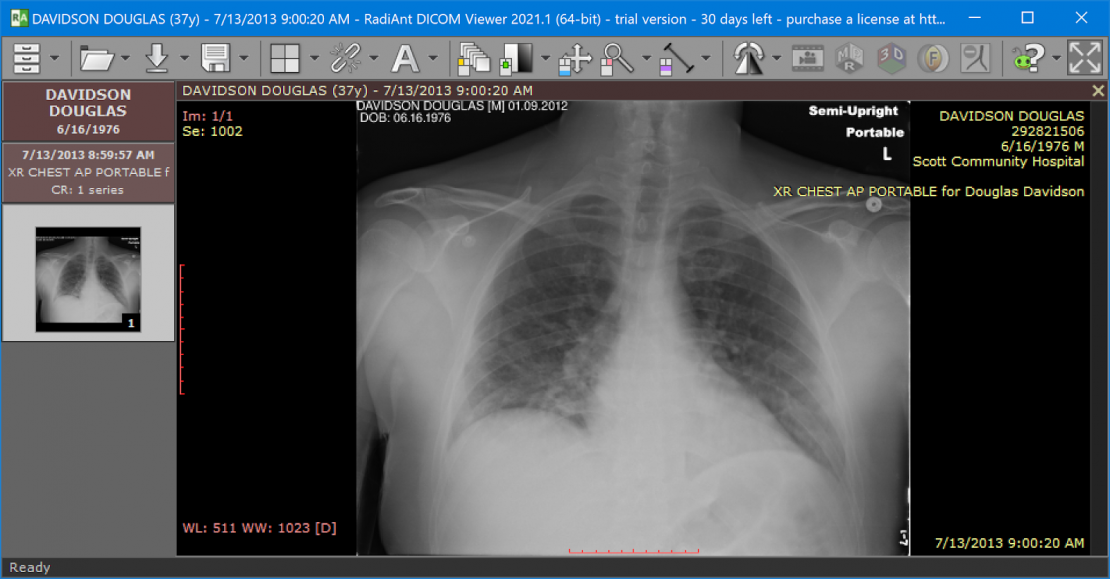
Masked:
PDF and Image Files
DarkShield can also process unstructured data inside of PDF and image files. DarkShield will use Optical Character Recognition (OCR) to extract the text from the file to perform the search. DarkShield can also handle images inside PDF documents.
The PDF configuration options inside the File Search Context deal mostly with memory efficiency vs. performance tradeoffs:
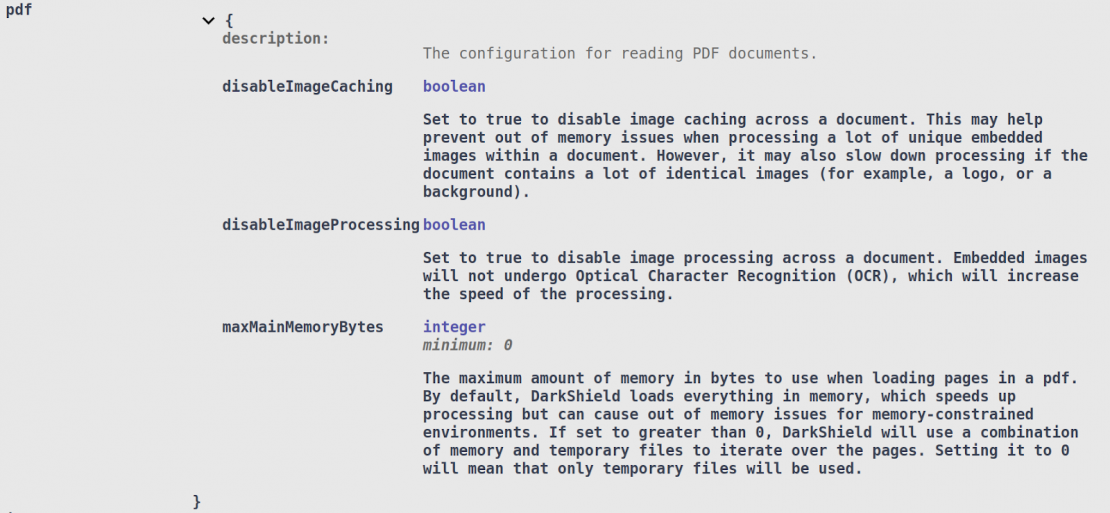
For PDFs that contain a large number of unique images, the disableImageCaching option can reduce DarkShield’s memory usage. In addition, you may choose not to search through images if you know that they do not contain any PII, by setting the disableImageProcessing option.
Finally, you can also set the maxMainMemoryBytes option, which limits how much of the document DarkShield will keep in memory at any given time. By default, DarkShield will load the entire document in memory for higher performance at the cost of more memory usage. All 3 options can also be set in the File Mask Context.
The image configuration options inside the File Search Context are related to tweaking its OCR engine:

DarkShield utilizes Tesseract models in order to perform OCR. By default, DarkShield will download the necessary models for you if they do not already exist and place them inside of the tessdata folder inside of the API’s installation directory — unless a different path is specified in the tessDataPath option.
You can also specify the language that the OCR engine will attempt to read from the image. Multiple languages can be specified using the plus (‘+’) character to separate them (for example, “eng+hin+ita”).
If you are familiar with the Tesseract engine, you can also specify specific configuration parameters inside of the tessConfigVariables dictionary.
DarkShield can insert masked text into a PDF, provided that two conditions hold true:
- The length of the replacement text is less than or equal to the length of the original. This condition eliminates certain masking operations like hashing, non-format preserving encryptions, and random pseudonym replacement. Note that the length is calculated in the number of characters, and not based on the widths of the glyphs as they are drawn out on the pdf.
- The replacement text can be encoded using a standard font available to DarkShield, or a font that is stored in the PDF.
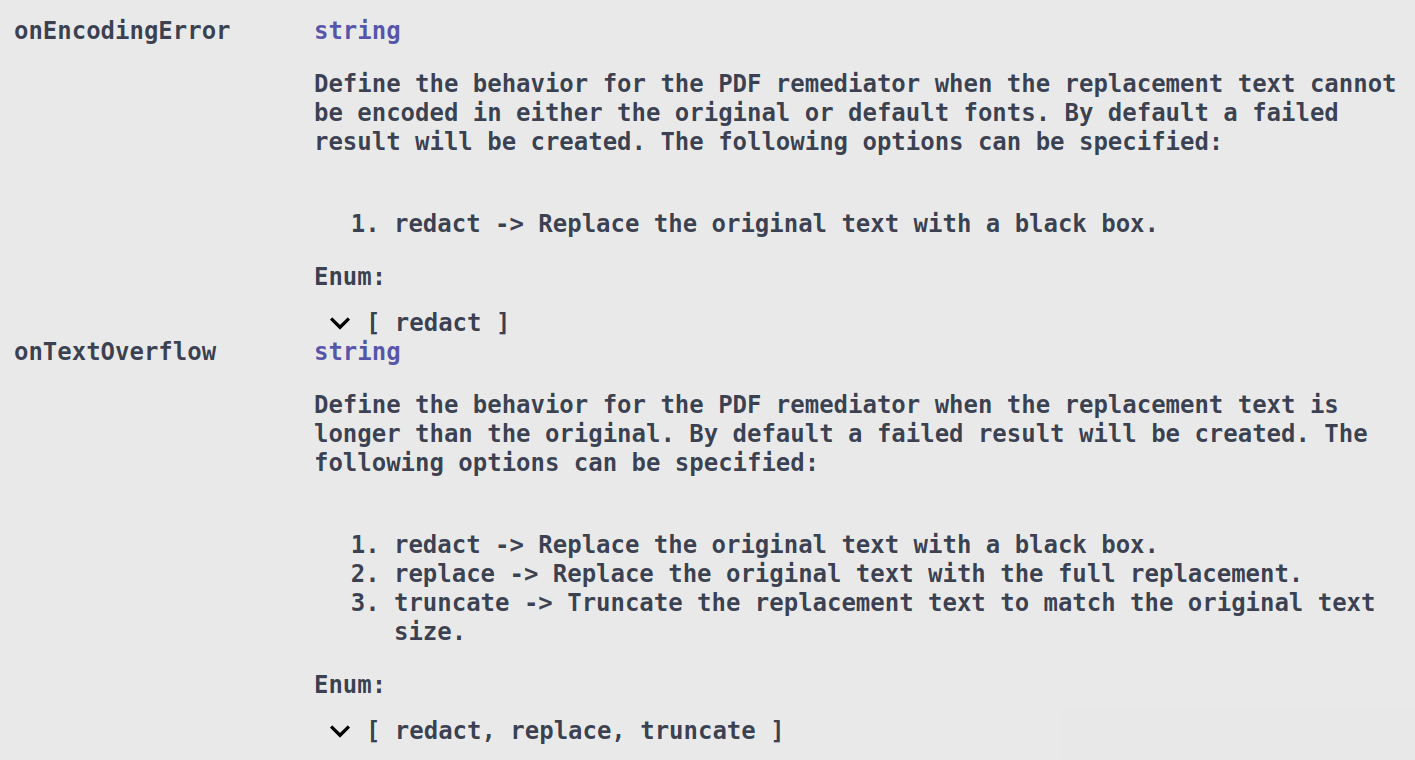
By default, if either condition fails, DarkShield will generate a failed masking result and leave the original annotation unredacted. The File Mask Context also provides options for how to handle these issues by specifying the onEncodingError and/or onTextOverflow options:
An alternative for random pseudonym replacement for PDF and images is a length preserve pseudonym replacement rule. This rule is specific to DarkShield and allows for random replacement of values while preserving the length of the text.
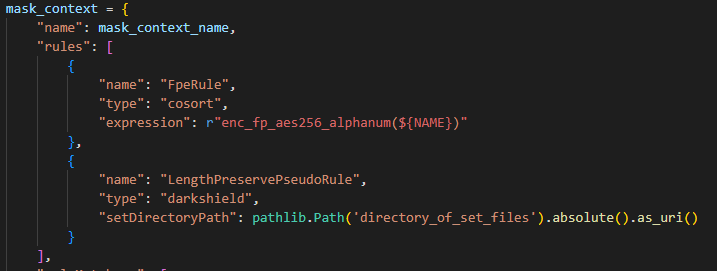
The length preserving pseudonym replacement operation requires either a set file or a directory containing set files sorted by length of text values.
Syntax for providing a directory:
Syntax for providing a single set file:
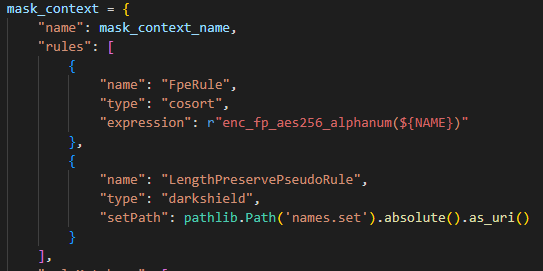
It may be recommended that in combination with this length preserve pseudonym replacement masking operation, the “prettyTextReplacement” configuration in FileMaskContext, be enabled. In doing so DarkShield will attempt to shift the words following after the replacement text to the right according to the differences in total character widths between original and replacement text. This scenario can occur when two words possess the same number of letters but the individual character widths may affect the overall length of each word and may result in a replacement word spilling over and overlapping with adjacent words.
Example:
Text 1: Hello -> 5 letters.
Text 2: MMMMM -> 5 letters.

FileMaskContext – prettyTextReplacement
Extra documentation on masking rule parameters.
A demo for PDFs can be found under the pdf-image folder. Both the PDF and image are a form containing a name and two social security numbers. In this example, DarkShield will redact the first five digits of the social security numbers and format-preserving-encrypt the name. Note that for the image masking, a black box redaction is applied instead.
Here is a snippet of the original PDF file along with the masked result:
Original:

Masked:

And here is a snippet of the original image file along with the masked result:
Original:

Masked:

If you have any questions, please feel free to email darkshield@iri.com.










