Processing Data in, and for, Excel Spreadsheets
In addition to all the other structured data sources that IRI software already supports, it is now possible to read, process and write data from and to XLS and XLSX files in the SortCL program central to:
- IRI CoSort, for fast sorting, transformation, and reporting
- IRI NextForm, for mapping, migration, and replication
- IRI RowGen, for random selection or generation of realistic test data
- IRI FieldShield, for sensitive data masking
- IRI Voracity, for all the above, plus ETL, data cleansing, and wrangling for analytics
and to write the resulting data back to those or other targets, including one or more Excel sheets.
XLS is the older, but still supported and used, 1997-2003 Excel format. XLSX is the default format for spreadsheets saved with Excel 2007 onwards.
SortCL Syntax for Processing Excel Files
As with other supported file format declarations, the input or output file “process’ type definition for spreadsheets is either /PROCESS=XLS or /PROCESS=XLSX depending on the file format. There are also optional arguments, separated by commas, that can be specified in the /INFILE or /OUTFILE line before the actual file path.
The syntax is:
/[IN/OUT]FILE=“<Sheet info>[,HEADER][,VERTICAL]>;<File>”
Sheet info can be specified with a named range, or the sheet info can be explicitly stated, such as: (‘SheetName’!)(FirstCellInRange:LastCellInRange). Sheet name is the name of the sheet in the workbook to process and FirstCellInRange and LastCellInRange define the outer bounds of the data to process.
Each optional argument group should be preceded by a comma, except for the first argument of the sheet info. The sheet name and cell range are put together into one argument group, so there should not be a comma in between the sheet name and cell range.
The arguments end with a semicolon and then the file name should follow. The entire file line with all of this information should be double quoted.
The bounds of the data range and the sheet name need to be specified to ensure that data from the correct cells is retrieved. This is specified in a SortCL script with the argument group:
((‘SheetName’!)(FirstCellInRange:LastCellInRange))
SortCL also supports just specifying the name of the range. When specifying a named range in /PROCESS=XLSX or /PROCESS=XLS, just use its name. For example, a named range could be created in Excel that references the cells B2:E8 and given the name “Bills”. The source line, /INFILE=”Bills;accountInfo.xlsx”, tells SortCL to read data from the cells in the range named Bills.
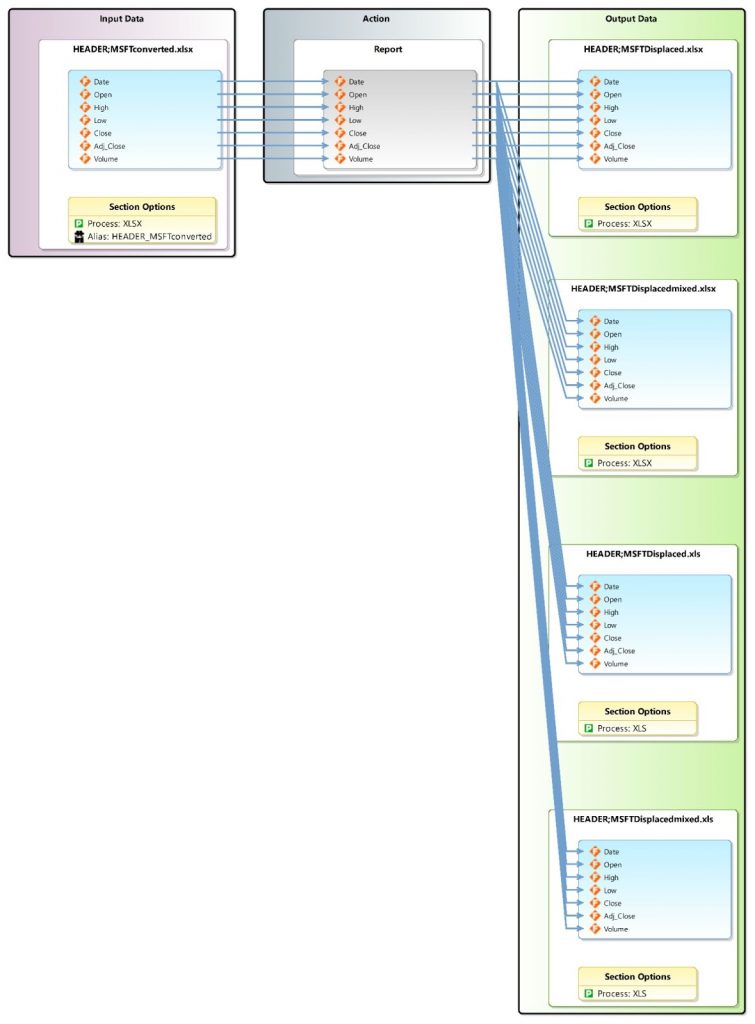
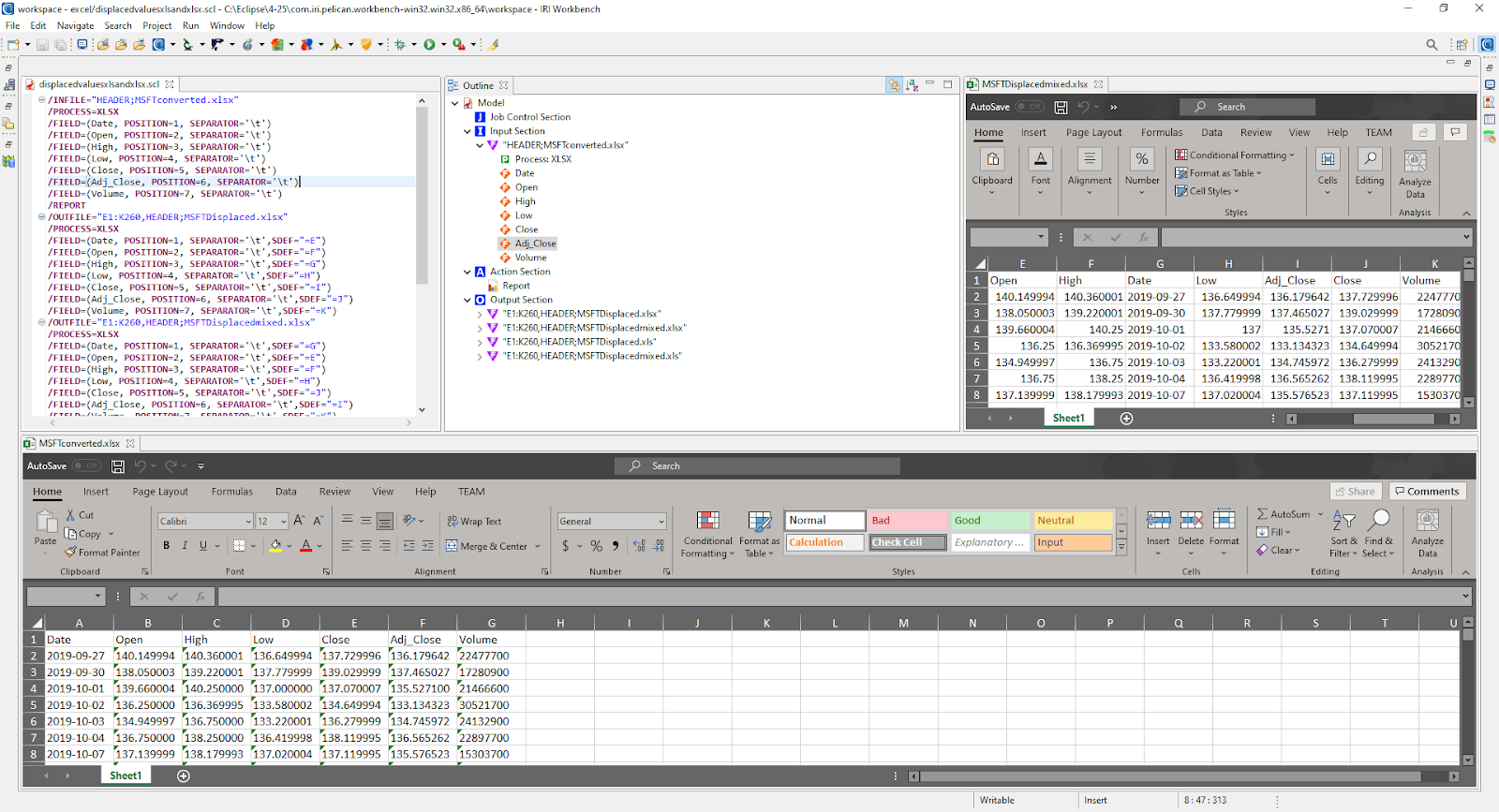 IRI Workbench with a serialized script, outline, plus Excel input and output files.
IRI Workbench with a serialized script, outline, plus Excel input and output files.
Spreadsheet Processing Assumptions
These process types assume several things to make sure the data will be read from/written to the desired locations and formats; i.e.,
- An optional parameter in the file line defines the data range.
- The data range parameter defines the boundaries of the data.
- If no data range is specified, data starts in cell A1 of the first sheet.
- Named ranges cannot contain a colon or a dollar sign.
- Sheet names are single quoted and followed by an exclamation point.
- If there is a missing sheet name in an unnamed range, the data is assumed to be on the first sheet.
- Dollar signs in absolute cell references are not required.
- If there is a header row (specified by HEADER, or H for short) in the arguments preceding the file name, a horizontal header row is assumed, unless VERTICAL (or V, for short) is also specified. In that case, the header row is interpreted as a vertical header row.
- If there is no HEADER specified in the arguments, no header row is assumed
- Data is extracted or processed from/to Excel files based on this information in the script
1. SDEF: Short for Spreadsheet (location) Definition, this field attribute gives the location of the column (or row, if vertical) to use in each input or output /FIELD declaration. SDEFs can optionally contain a row range of the data, but in that case all SDEFs must specify a row range. The number of rows need to match up, so if there is one SDEF with a row range of data that only consists of 30 rows, but another SDEF has 35 rows, then the row range of the first SDEF will be extended automatically by 5 rows.
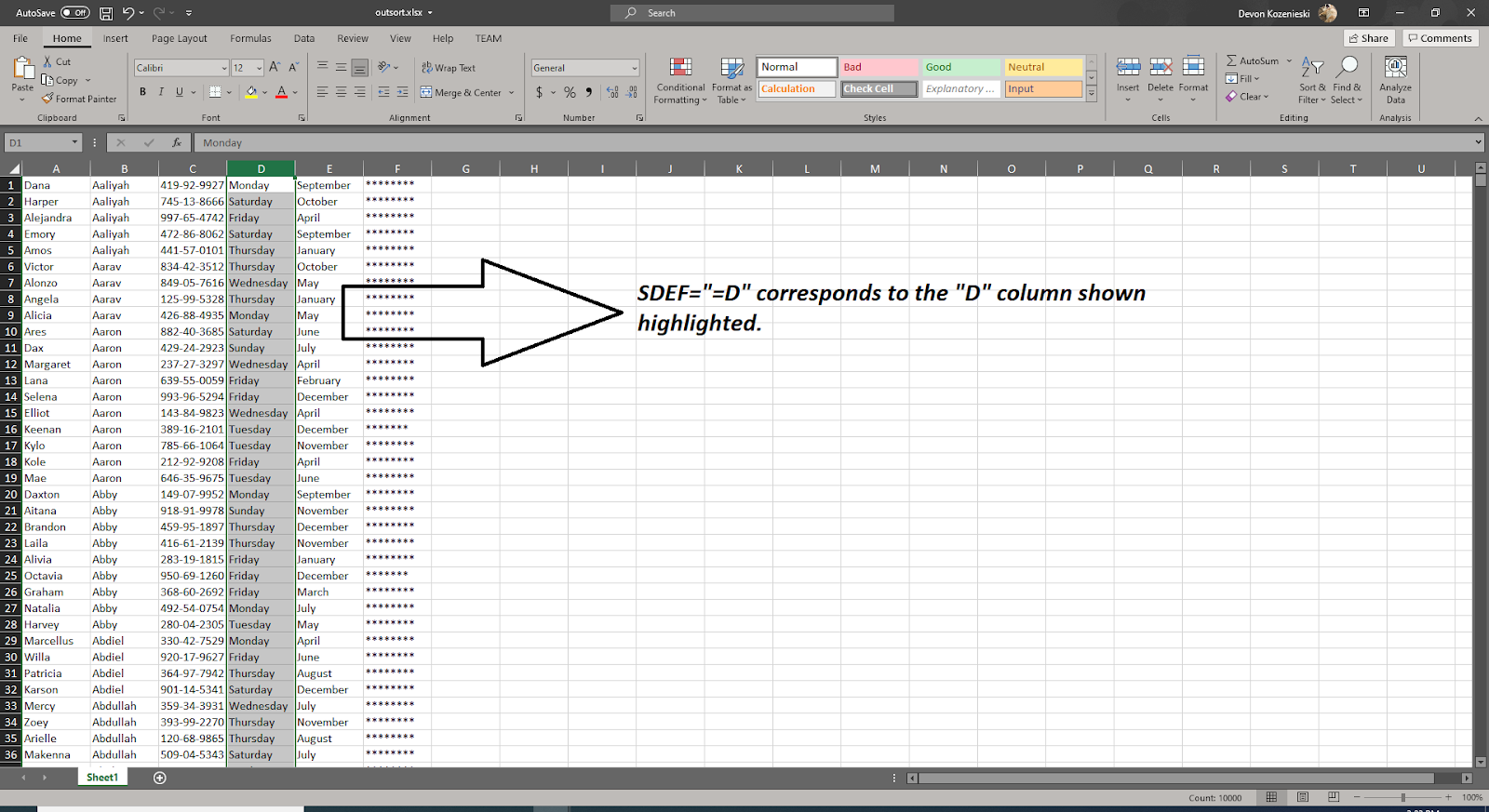
2. Sheet Name: If given in the file arguments, the specified sheet name will be processed. Otherwise, the first sheet in the workbook is used. When writing to a new file, this names the sheet to write to. If no sheet name is specified on output, “Sheet1” is used.
3. Data Range: This file argument defines the bounds of the data to be read or written. If there is a data range but no SDEFs, then the fields are read in order from the first column of the range. This can also be left empty, and instead the bounds of the data will be the outer bounds of the used part of the worksheet. For example, if there are 30 rows of data from columns A to F, starting from the third row, with no other data present in the worksheet, then the bounds of the data will automatically be parsed from A3:F32.
4. Vertical: If this argument is specified, the data is interpreted as being present in a vertical or inverse layout (think this: rows reflect vertically instead of across horizontally).
5. Header: Specifying HEADER when reading from an Excel file will skip the first row in the data range. Specifying HEADER when writing to an Excel file will write a header into the target range that was derived from either the field name, or the first half of the SDEF (before the equal sign), if present. Keep this in mind when specifying data ranges on output, as that is an additional row to account for.
6. Separator: Fields used in the XLS and XLSX processes must be delimited (rather than fixed position), and if there is a delimiter present in the data itself, specify a “FRAME” character in the /FIELD statement so the column data gets properly parsed.
- The maximum column letter in XLSX is XFD (column number 16,384), and in XLS is IV
(column number 256). The maximum row number is 1,048,576 in XLSX, and 65,536 in XLS. Absolute ranges specified beyond these points will not work.
Known limitations of /PROCESS=XLS
XLS is the older of the two main spreadsheet formats, although it is still fully supported in newer versions of Excel. However, there are some limitations of this older format. XLSX is highly recommended over XLS for large data sets since there is a limit of 65,536 rows in an XLS sheet. Unrelated to the technical limitations of XLS, but notable for SortCL, is that /PROCESS=XLS cannot append data to XLS sheets.
Behavior when appending with /PROCESS=XLSX
When appending to an XLSX spreadsheet (by using /APPEND below the /OUTFILE), if the range specified is too small to hold the number of output records, then the data will be truncated to fit the range (so as to not unintentionally overwrite any existing data in the sheet). This is in contrast to writing without /APPEND (i.e., where default /CREATE behavior occurs), where a specified target sheet range that is too small to hold all the input records will be added on to sequentially (to accommodate all those records).
Note that /OUTCOLLECT can be used to limit the number of output records if necessary. Also, when appending to an XLSX sheet without a range specified, the first record will be written one row below the last used row of the existing spreadsheet, and continue as long as needed, so long as it does not exceed the maximum row limit (1,048,576 rows) of an XLSX spreadsheet.
Limitations of both /PROCESS=XLS and XLSX
XLS(X)-specific formatting is not preserved when transferring between XLS(X) input and XLS(X) output. SortCL functions as a data processor, not a data formatter. Thus while SortCL can map data between sources and targets, it would not be able to preserve attributes like fonts, colors, highlights, text wrapping, cell merging, etc. The same file cannot be written to multiple times in the same script with these two process types.
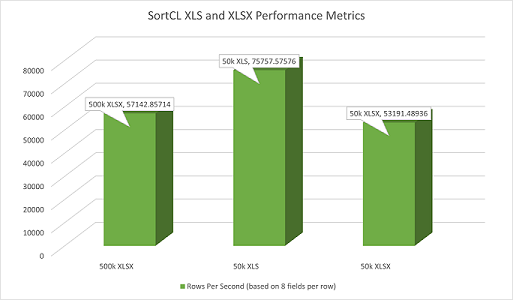
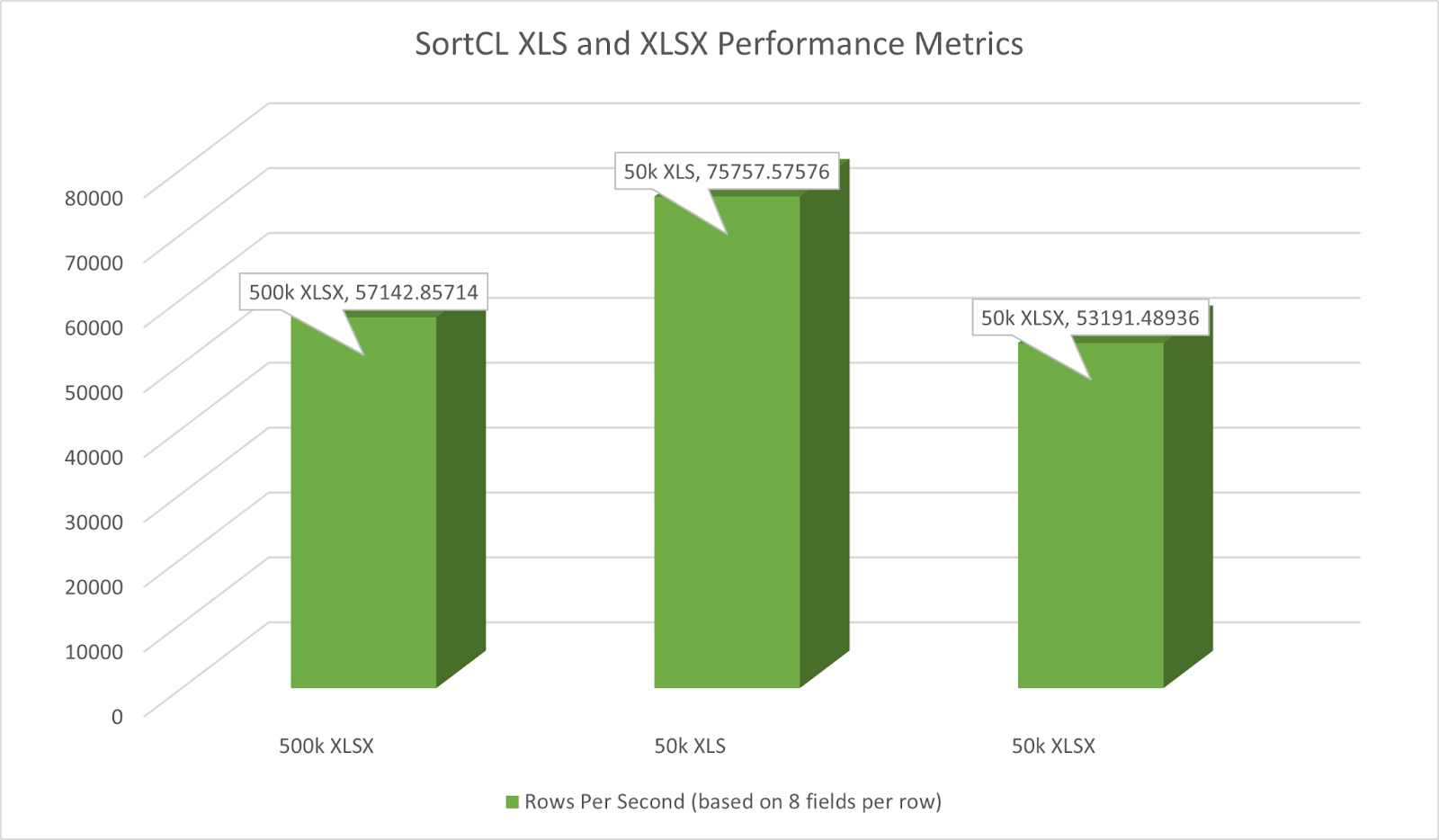
Performance Metrics
To get an idea of the general performance characteristics of XLS and XLSX file processing, a batch file ran three 64-bit SortCL jobs to measure performance. The first script sorted a 500K-row .XLSX file. The second did the same on a .XLS file with 50,000 rows. The third job sorted and encrypted a 50,000-row .XLSX file. All three wrote their results to a delimited text file.
Each row of data in each file consisted of 8 fields: a first name, last name, an integer, Social Security number, a decimal, month of the year, day of the week, and a PIN.
The first job script ran in 8.75 seconds, the second in 0.66 seconds, and the third in 0.94 seconds. Note that the XLS format has a limit of 65,536 rows, while the XLSX format has a limit of 1,048,576 rows.
The first script processed an average of roughly 57,142 rows per second.
Here are the specs of the Windows 10 computer used to perform this test:
Conclusion
This article provided an overview of SortCL program operations and syntax — introduced as of IRI CoSort Version 10.5 to directly process Excel data in both the old and new Microsoft spreadsheet file formats.
In the next article of this four-part series, we’ll look into using these job scripts to process XLS and XLSX files, and feature examples demonstrating various use cases, types and locations of data, and the syntax options for different scenarios.










