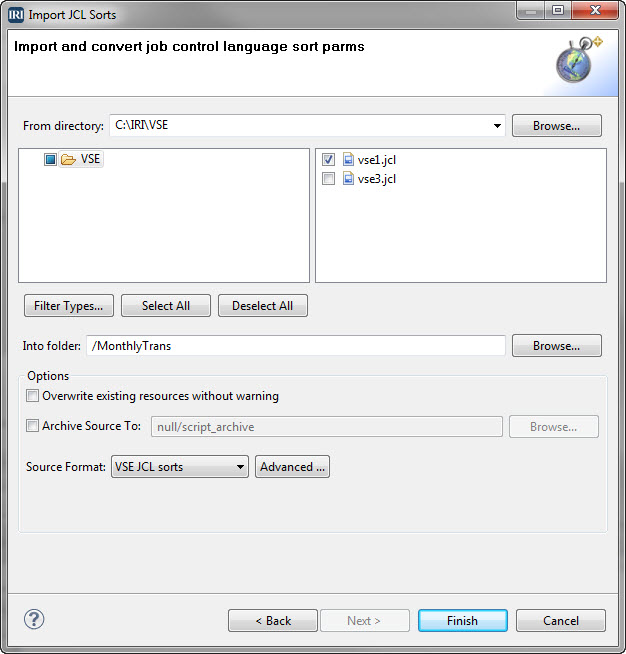
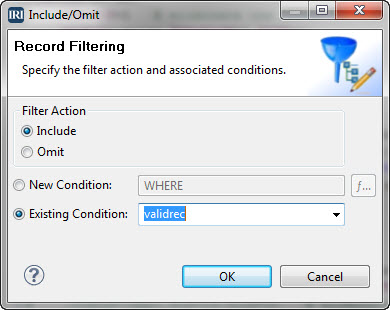
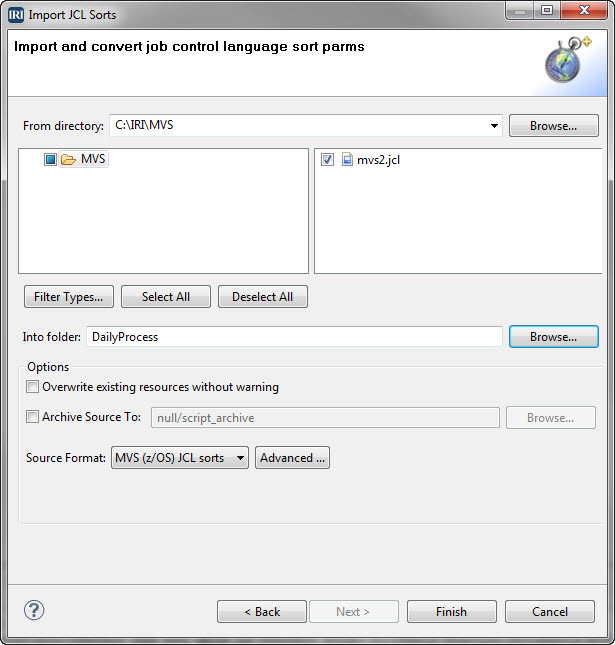
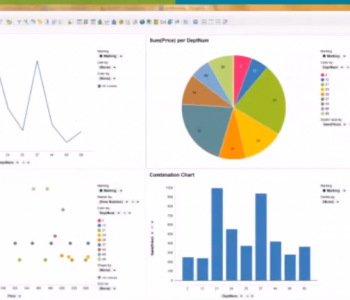
 VLDB
VLDB
VLDBs in the 20-teens: You’re Gonna Need A Bigger…
Time and technology keep accelerating, and the data we save keep on growing exponentially. Thus, the exact definition of a Very Large Database (VLDB) continues to change with new advances in hardware and software. Read More



{kind=link}
{kind=link}