Filtering Tables in IRI Workbench
IRI Workbench provides a number of features for working across multiple tables in a database. It includes wizards to: profile databases; classify columns; subset, mask and migrate data; generate test data; etc.
Tools in IRI Workbench can help select which tables are available to those wizards, as well as in a particular relationship diagram, or in scanning tables for patterns or collections of sensitive values. With too many tables in a database, it can be overwhelming to visualize, select, and scan all the data and metadata.
One solution to this data overload problem is to filter the tables which are visible at any one particular time. This article covers how you can perform database table filtering in IRI Workbench using a combination of data source explorer techniques in Eclipse and long with SQL table filter techniques.
Filters
It is easier to work with smaller sets of tables at one time. Typically, a few hundred related tables at a time is a reasonable amount. Fortunately, there is a mechanism within IRI Workbench to limit the list of tables shown, using a filter.
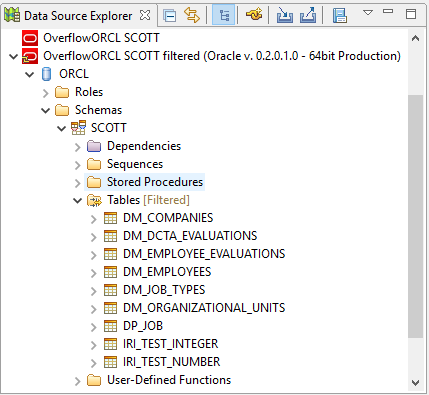
Tables that are filtered out are excluded from the list in the Data Source Explorer, the main view into the database structure. They also do not appear in the selection lists in wizards, and are skipped during schema-wide data scans, speeding up the classification of hard-to-find data. Reducing the number of tables to some logical set, with a manageable amount of data, makes it easier for the user to focus on the task at hand. Multiple connection profiles can be created to show only those tables related to a particular task.
Simple filtering by table name is a built-in feature of the Eclipse Data Tools Platform (DTP) project, which is used for database access in IRI Workbench. However, it can only be used to specify table names that do, or do not, start with, contain, or end with, certain character strings. There are times when a more sophisticated approach is needed.
DTP also allows a list of table names to be selected for either inclusion, or exclusion, on a per schema basis. This involves loading all of the table names into a wizard page, and then applying checkmark selection to all of the table names to be included or excluded. This works well for small numbers of tables, but quickly becomes unmanageable when the list of tables grows into the thousands, or even tens-of-thousands.
There is a relatively easy work-around that allows table selection by name, based on an external list provided by the user. This list could be generated by an outside tool, or as the result of an SQL query. By way of example, this post will show, step-by-step, how this can be accomplished.
Prepare a Table List
Many different query methods can be used to build the table list. One useful method is to filter out all tables that have zero rows of data. However, in this particular example, a SQL query will be used to extract a list of tables to include in the filter based on matching against the table names. The list of tables selected will be short, to make the example easier to follow. The same technique will work to filter tables based on a much longer list.
The tables of interest in this example have two formats, they either start with the letter D, followed by any character, and then an underscore, or they start with the string “IRI_”. Either pattern may then be followed by any number of additional characters.
The underscore was purposely chosen as a character of interest, because in structured query language (SQL) the underscore represents a single wildcard character. Therefore, using an underscore in a DTP filter expression, or an SQL statement, is not straightforward.
This example is based on an Oracle database, and will show how to escape the underscore character so that it can be used literally in the where clause of a query. The query which will produce a table list matching the above criteria:
SELECT TABLE_NAME FROM ALL_TABLES WHERE ( TABLE_NAME LIKE 'D_\_%' ESCAPE '\' OR TABLE_NAME LIKE 'IRI\_%' ESCAPE '\' ) AND OWNER LIKE 'SCOTT' ;
Notice the use of the backslash to escape the underscore character where ever it should be interpreted literally. This query can be executed from a SQL Scrapbook file within IRI Workbench. The results will be displayed in the SQL Results view window. With the cursor in the SQL Scrapbook file editor, right click for the context menu, and select Execute All.
The query will also need to be run separately for any other schema (OWNER) which needs a filtered table list. Query results for different schemas will be kept separate, and processed in similar fashion.
The results will be viewable on the Result 1 tab in the SQL Results view. From the context menu of that view, select Export > Current Result. In the next dialog, export the result to the project folder in the workspace as a CSV formatted file.
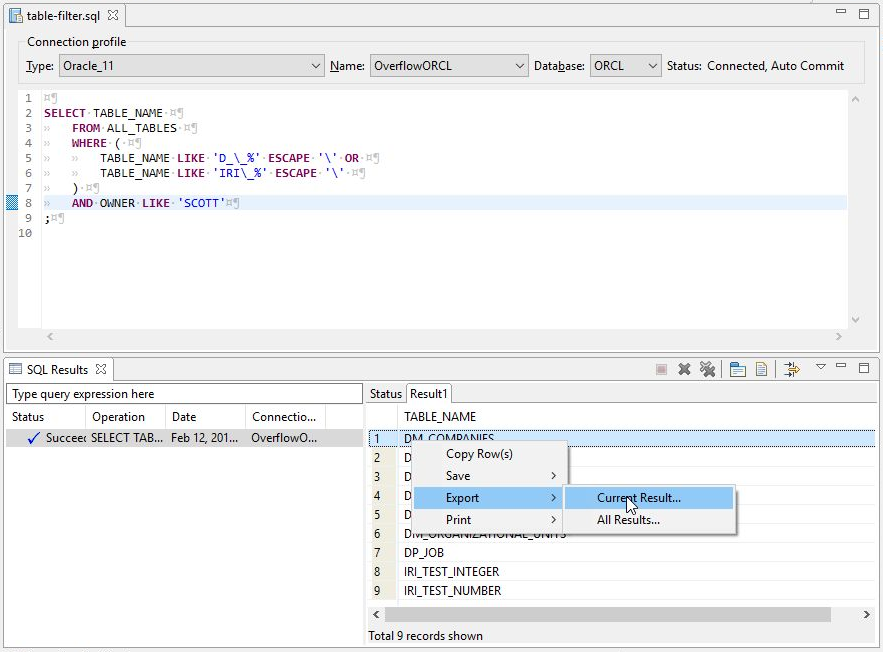
Table List to Connection Profile Import File
Eclipse DTP provides a mechanism for importing and exporting one or more database connection profiles from or to a specially defined XML file. The procedure here will be to first prepare the CSV file for insertion into the import file, then export the connection profile that will be filtered, and finally to modify the export file with the list of table names as a filter condition.
Open the CSV data file in the IRI Workbench text editor. The CSV file will not be formatted exactly how it is needed. First, delete the very first row which has the column heading. Next, the table names need to be framed by single quote marks instead of double quotes, and a comma must separate each name.
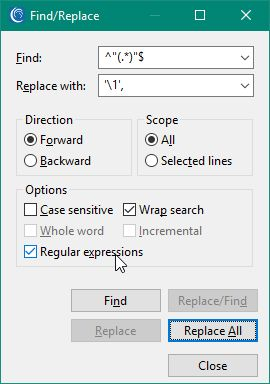
Press Ctrl+F to bring up the Find/Replace dialog. Enter the following patterns for Find: ^”(.*)”$ and Replace with: ‘\1’, and select the Regular expressions option. Press the Replace All button and then save the file. The table list file is now ready for use in the import file.
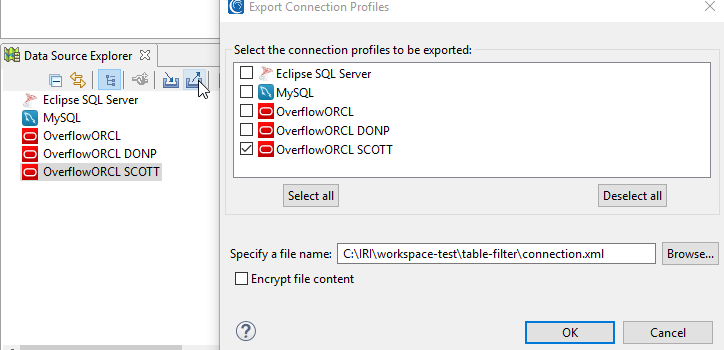
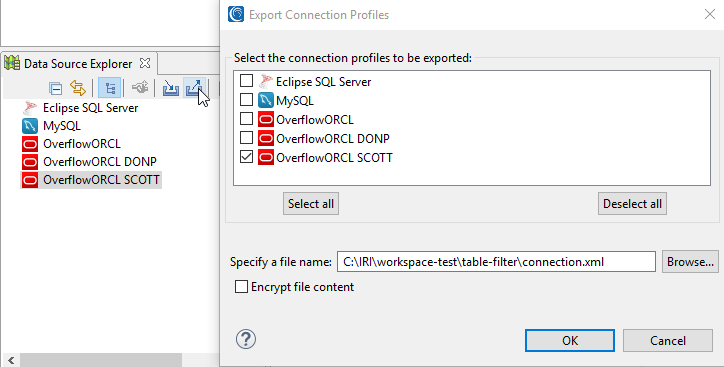
The next step is to prepare an export of the database connection profile without the table name filter applied. The connection profile export button is on the Data Source Explorer view toolbar. It looks like a basket with an arrow pointing up and to the right. Place a checkmark next to the connection profile that needs the filter, and specify a file name with an .xml extension in the project workspace. Also be sure to uncheck the Encrypt file contents box before saving the file.
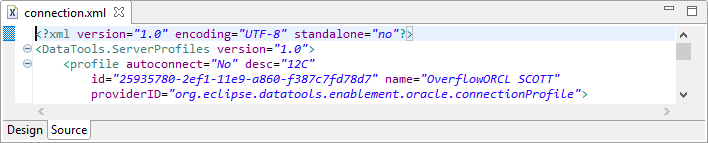
Open the XML export file in the IRI Workbench. Click on the Source tab at bottom of the XML editor window. Press Shift+Ctrl+F to format the XML onto multiple lines, to make it easier to edit. Near the top, just inside of the profile tag, is a line with the attributes id and name.
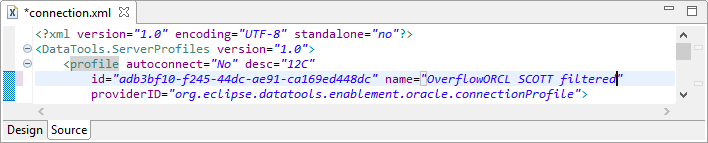
Go to a website like https://www.guidgen.com/ and generate a new GUID to replace the value in the id attribute. Edit the name attribute to add the word “filtered”, or some other indicator that will identify the new connection profile.
Below is a before and after view of the example connection profile:
Before:
After:
Next, find the line that has:
<org.eclipse.datatools.connectivity.sqm.filterSettings />
If there are additional elements already inside of the tag, that means there are already filters applied to schemas in the connection profile. They may be left in place, and new table filters inserted for additional schemas.
Otherwise, the connection profile properties can be edited to remove them before exporting again. The line above must be replaced with the following:
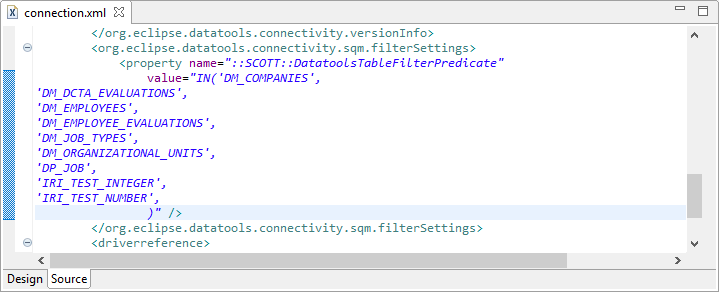
<org.eclipse.datatools.connectivity.sqm.filterSettings> <property name="::SCOTT::DatatoolsTableFilterPredicate" value="IN()" /> </org.eclipse.datatools.connectivity.sqm.filterSettings>
Go back to the edited CSV data file with the list of tables. Select all of the text, and copy it to the clipboard. Return to the XML file, and paste the clipboard contents directly in between the parentheses in the text immediately above. Note that if the schema (OWNER) name is in the property tag, it must be changed to match the name of the schema being filtered.
If there are additional schemas with table lists, repeat the steps to add additional property tags. If a table list should be excluded rather than included, insert the keyword NOT in front of the word IN. The resulting XML in this simple example is shown below. In a more complicated database, there may be thousands of lines of table names. When all editing in done, select File > Save As… and save the file under a new name.
Import the Filtered Connection Profile
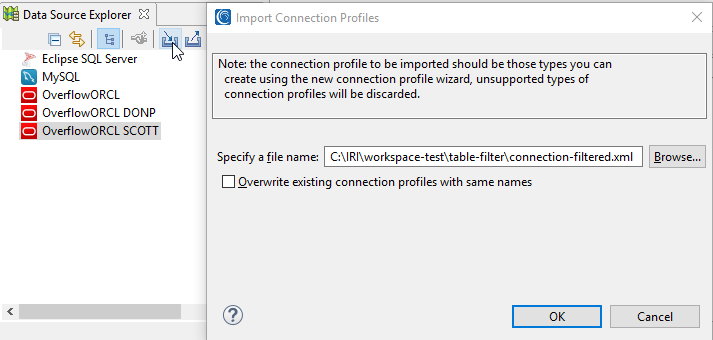
The newly created filtered connection profile XML file can be imported, creating a new copy of the exported profile, with filtering applied. The connection profile import button is on the Data Source Explorer view toolbar, just to the left of the export button. It looks like a basket with an arrow pointing down and to the right. Browse to the XML file that was modified with the table list. If a profile with the same name already exists, check the box to overwrite it.
Finally, opening the connection profile, and navigating to the schema that was filtered results in only those tables that are in the list being shown: