What is Hadoop?
 Hadoop is an increasingly popular computing environment for distributed processing that business can use to analyze and store huge amounts of data. Some of the world’s largest and most data-intensive corporate users deploy Hadoop to consolidate, combine and analyze big data in both structured and complex sources.
Hadoop is an increasingly popular computing environment for distributed processing that business can use to analyze and store huge amounts of data. Some of the world’s largest and most data-intensive corporate users deploy Hadoop to consolidate, combine and analyze big data in both structured and complex sources.
With Hadoop, and its MapReduce programming language (and later variations like Spark, Storm, and Tez), high-volume data processing operations can scale up from running on one server to several thousand machines at once, harnessing the computing power on a managed grid.
Today, companies like Google, Yahoo, Facebook, Ebay and Linkedin use Hadoop. It’s for that reason major industry vendors IBM, Oracle, Informatica and Microsoft are positioning themselves on Hadoop, and long-time competing innovators like IRI (The CoSort Company), have as well. Both sides recognize that Hadoop is becoming a cost effective way to work with petabytes of data.
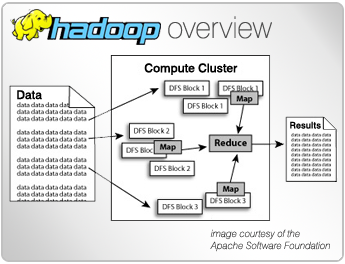
What makes Hadoop more powerful than previous distributed processing technologies is that it can run on a large number of machines that don not share memory or disks. Hadoop breaks the data into smaller pieces, distributes those pieces across the grid, and merges the results automatically on the desired target platform. In addition, it has the intelligence to balance workloads, and recover from individual node failures through redundancy.
IRI has always been a big data vendor, processing data outside databases to improve performance and leverage standard file systems. The Hadoop File System (HDFS) is the applicable equivalent in this case. IRI began working with Hadoop innovators in S.E. Asia (Solusi247) in 2014 to distribute and optimize CoSort-compatible transformations and FieldShield data masking functions across large grids. RowGen-compatible test data generation is next.
By 2017, IRI’s modern platform for “total data management” — called Voracity — began running the above jobs either via the default SortCL engine, or seamlessly in Map Reduce 2, Spark, Spark Stream, Spark Stream, and Tez. Support is also available for data streaming through Kafka, etc., compressed formats like Parque, and both SQL and NoSQL databases compatible with Hadoop.
The results of IRI’s map-once-deploy-anywhere options are significant price-performance gains for big data integration (ETL) architects and data scientists, as well as data governance officers dealing with PII in JSON and other sources. That is not only because of the relatively low cost of Voracity subscriptions, but because there is no need to learn to program in any language to get work done. The free IRI Workbench GUI, built on Eclipse, makes job design a graphical affair, and coding in Hadoop moot.
Check out this article to help you decide when Hadoop should be used, and this article for how to connect to HDFS and run jobs seamlessly in Voracity.










