
Data Masking in Healthcare
Healthcare providers, medical researchers, and other “business associates” collect and process sensitive data on patients, which HIPAA law classifies as protected health information (PHI). Because PHI is stored and shared in databases, clinical notes, imaging studies, treatment forms, and EDI (claim) formats – both on-premise and in the cloud – safeguarding it by finding and de-identifying it can be a complex, time-consuming challenge.
Data masking or anonymization techniques, when properly applied, enable PHI data collectors to use unique healthcare details for billing, research, marketing, or application development without exposing the identity of actual patient details. The following are some practical use cases where data masking plays a key role in the healthcare sector.
1. Production and Test Data De-Identification
The 1996 US Health Insurance Portability and Accountability Act (HIPAA) requires the de-identification of 18 unique patient attributes, called key identifiers. This is a requirement of the HIPAA Safe Harbour Security Rule, which does not distinguish between data in production or test environments.
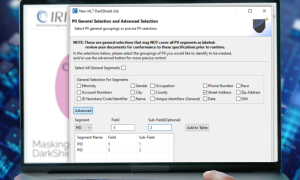
Healthcare organizations rely on analytics to improve patient care, reduce costs, and streamline operations. However, when database application developers need a realistic test schema or data scientists need to build dashboards or run machine learning models, the PHI in their sources must first be masked. Using unmasked patient data in these environments can lead to data breaches and privacy law violations.
Data masking tools like FieldShield, DarkShield, and CellShield from IRI allow healthcare entities and business associates to classify, discover, and de-identify PHI in on-premise and cloud databases and file stores. By using deterministic masking functions like format-preserving encryption or unique, consistent pseudonym replacement values, these tools can also preserve referential integrity in masked environments across structured, semi-structured, and unstructured targets.
2. Research, Analytics and Marketing Data Anonymization
Data masking also allows medical researchers and marketers to work with realistic, but not uniquely identifying. PHI such as names, dates of birth, medical record numbers, and diagnosis codes can be replaced with dummy values that maintain the correct format and distribution, ensuring software behaves as expected, without compromising patient privacy.
More specifically, the HIPAA Expert Determination Method security rule, as an alternative to the Safe Harbour security rule above, specifies that datasets may not be more than 20% likely to re-identify a particular individual. To comply with this rule, re-ID risk determination must be statistically measured using approved algorithms like l-diversity or k-anonymity.
To score the likelihood of re-identification based on records before or after masking, IRI provides a risk scoring wizard in its graphical Workbench IDE for the FieldShield product, IRI Workbench.
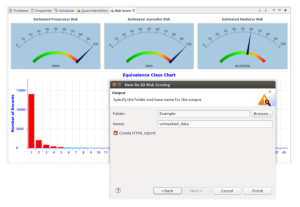
For demographic traits that should be further anonymized, IRI provides anonymization functions like blurring (random noise) for dates of birth or treatment, and binning to put quasi-identifiers like diagnosis, drug, profession, location, or marital/education status into a broader bucket. For example, a 42-year-old divorced melanoma patient from Milan admitted December 27, 2025, could be anonymized to a single Italian 44-year-old with skin cancer admitted January 3, 2026.
This new record would still be useful for research or marketing purposes, but far less likely to allow an ‘attacker’ of the data to identify the actual patient.
3. Outsourced Services and Vendor Collaboration
Many healthcare providers work with third-party vendors for billing, transcription, claims processing, and analytic services. Granting them access to unmasked patient data—even with NDAs and access controls—introduces significant risk.
Masking data before it’s handed off ensures that external teams can perform their functions without accessing real patient identities. It adds an extra line of defense in scenarios where breaches or vendor mishandling could otherwise lead to major consequences.
In addition to the data sources mentioned for traditional transaction and development purposes above, third-party data processors – known in HIPAA parlance as Business Associates – routinely take in patient data that’s in semi-structured or unstructured formats. For example, healthcare providers transmit EDI files, DICOM studies, PDFs, and clinical text notes for billing, diagnostic, and transcription services.

More sophisticated data masking tools like IRI DarkShield are needed to address the many challenges of finding and redacting PHI in such specialized sources. From leveraging AI-based content matchers to mask names inside sentences or signatures to calling its search/mask APIs into DevOps pipelines, DarkShield secures PHI in many ways … allowing its users to share healthcare data for cutting-edge solutions outside their firewall.
4. Healthcare Staff and AI Model Training
Medical schools, training centers, and hospitals frequently use case studies, patient histories, and sample datasets for teaching purposes. While data about actual patients is valuable for learning lessons, exposing patient identities is unethical and often illegal.

Masking PHI allows educational institutions to provide realistic datasets that reflect actual case complexity and variability without violating privacy laws. By anonymizing quasi-identifying demographic attributes (as discussed in Section 2 above), trainers can share practical examples without risking a data breach or HIPAA violation.
Data masking also aligns naturally with a HIPAA‑compliant AI training pipeline because it de‑identifies PHI at the source, ensuring only safely transformed data enters model development. This preserves analytical utility while enforcing the “minimum necessary” standard, reducing compliance risk across every stage of AI training.
5. Cloud Migrations and Hybrid Environments
As healthcare industry infrastructure now involves multiple storage and compute resources, PHI can be moving through or sitting in unmasked file and database silos on-premise and in the cloud. Thus, if you are uploading patient records to the cloud or syncing them across environments, mask the key-identifiers (reversibly with encryption if needed) so they are protected in transit and at rest.
Masked data can also be used to test cloud deployment strategies or run validation checks, avoiding the exposure risks of using live production data in non-secure or shared environments.
A Strategic Layer in Healthcare Data Protection
Data masking can help healthcare providers, researchers, and business associates who collect PHI protect it from improper use and disclosure. Using the right data masking or anonymization tools and techniques can enable secure, compliant access to data in a wide range of formats for a wide range of operational needs—from development to analytics to training.
While data masking technology and implementation strategies vary, their goal remains the same: protect patient confidentiality without disrupting workflows or data utility. IRI provides healthcare organizations and HIPAA-defined business associates with fit-for-purpose data classification (PHI discovery) and de-identification software for structured, semi-structured, and unstructured data sources, including:
- relational and NoSQL databases
- fixed, delimited, raw text, and Parquet files
- semi-structured files (JSON, XML, LDIF)
- EDI files (HL7, X12 and FHIR)
- PDF and Microsoft documents
- images and DICOM studies
See also:
- https://www.iri.com/ftp9/pdf/Voracity/Bloor-Spotlight-Managing-Healthcare-Info-July-2025-.pdf
- https://www.iri.com/solutions/data-masking/hipaa
Frequently Asked Questions (FAQs)










