Scoring Datasets for Re-ID Risk
One of the biggest concerns with releasing a dataset is the risk that a potential attacker can identify the owners of particular records. Even though masking or removing unique identifiers, like names and Social Security Numbers, can reduce that risk substantially, it may still not be enough. Harvard professor Latanya Sweeney reported that 87% of the U.S population can be identified using only their gender, date of birth, and a 5-digit zip code1.
To prevent data breaches and comply with the Health Insurance Portability and Accountability Act (HIPAA) and GDPR Recital 26, you should also de-identify such “quasi-identifiers” (along with “key identifiers” like name and SSN) to the point where the risk of re-identification is statistically moot2. IRI data masking software is designed to do that, especially to anonymize healthcare data (PHI) for privacy compliance, but how do you assess the results?
This article shows how to credibly score the HIPAA re-identification risk of structured data de-identified with IRI FieldShield, CellShield or DarkShield using the risk scoring wizard now available as a plugin to IRI Workbench. While it was designed with HIPAA EDM security rule in mind, student data privacy laws like FERPA also indicates the application of such an approach.
Loading Data
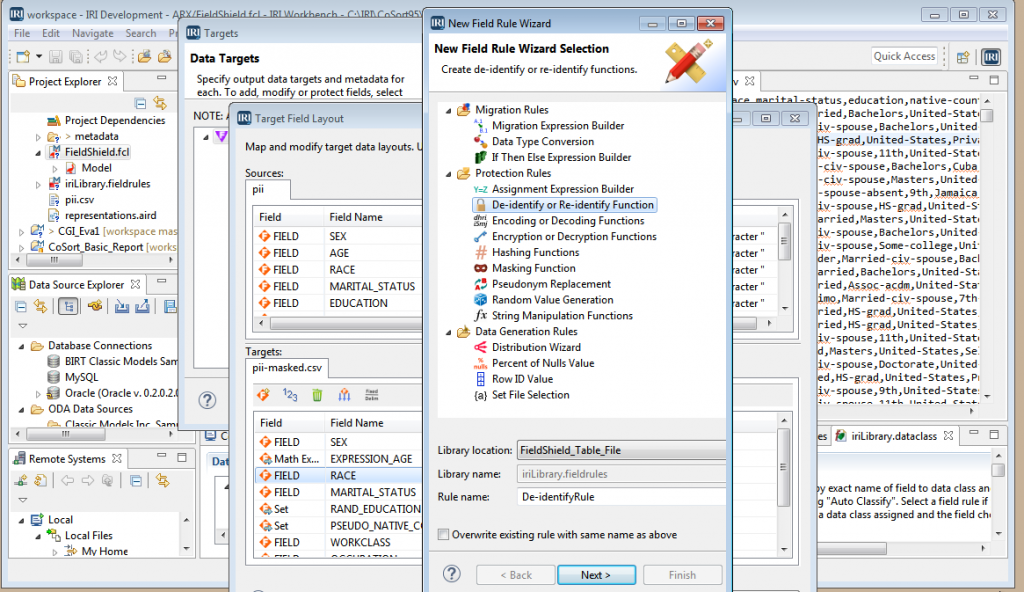
In our example, we are going to analyze the re-ID risk of a delimited file with the unique identifier having already been masked by FieldShield. Our interest is now to ascertain that the dataset cannot be re-identified through its quasi-identifiers alone.
To open the Re-ID Scoring wizard, select New Re-ID Risk Scoring from the FieldShield menu. You may also navigate to the wizard by selecting File -> New -> Other and selecting Re-ID Risk Scoring from the IRI category.
Specifying the Data Source
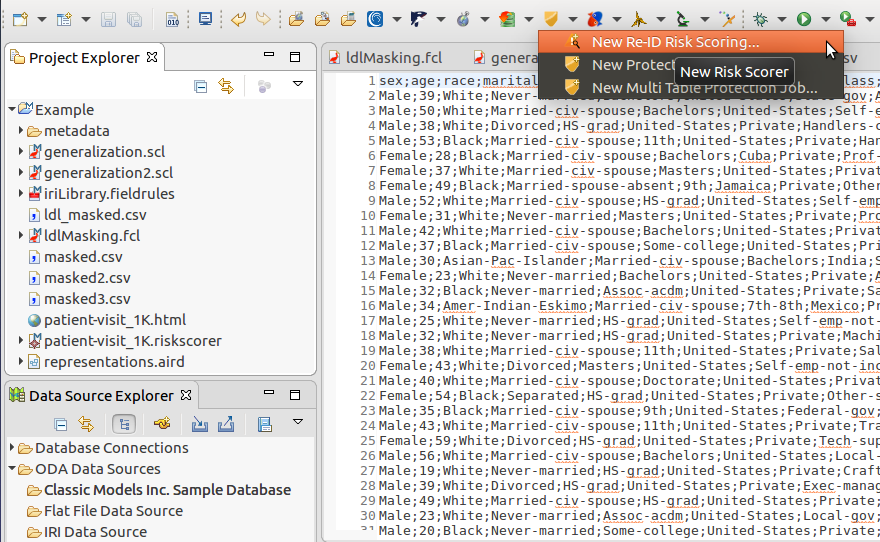
Once you have opened the Re-ID Scoring wizard you are prompted to select the source of the dataset that you wish to score. The wizard can take either flat, character delimited files, like Comma-Separated Values (CSV) or Tab-Separated Values (TSV) files, or a database table connected in Workbench via its Data Tools Platform (DTP) plug-in, as seen in the Data Source Explorer.
Depending on the choice, you will be required to provide specific configuration details on the next page. For flat files, the file path must be provided, along with the character set, delimiter, and frame character used within the dataset. For databases, a Connection Profile from one of the DTP connections and the corresponding Database Table need to be selected from a dropdown list or otherwise created from a dialog in the wizard.
Both file and table scoring require you to specify the Superset Region that will be used to estimate the uniqueness of your dataset against a broader population. The region should match the national background of the most amount of records within your dataset.
Previewing your Data
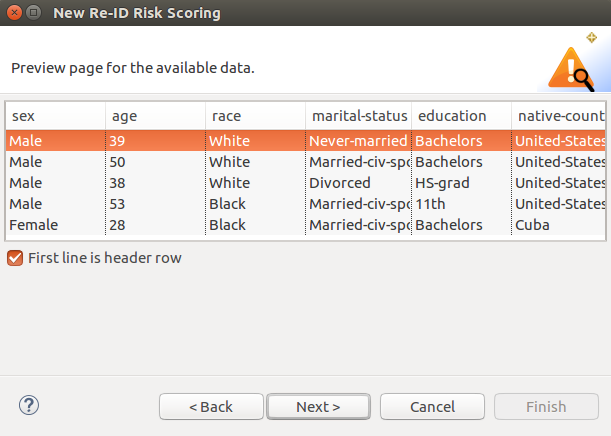
To ensure that you have correctly configured your data source, a preview page shows a subset of your data which the wizard structured based on your configuration. For flat files, the delimiter and frame characters will influence the number of records and how each individual attribute is separated from one another.
If your dataset is incorrectly delimited or shows up with an error in the preview, you may need to go back to the previous step and enter the correct configuration options. For flat files there is an additional option to specify if the first line within the file is a header row. Otherwise, default field names will be provided and used in the risk score.
Labeling Attributes
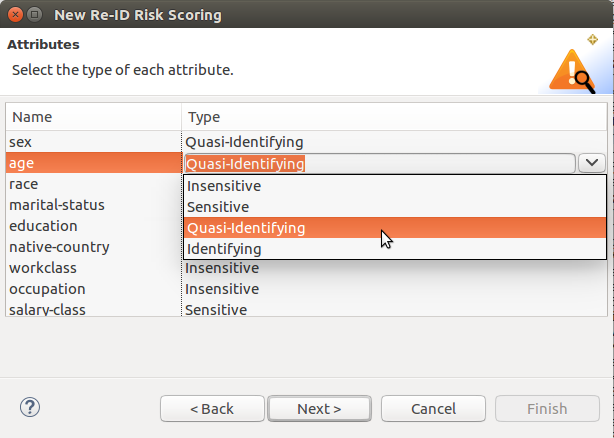
Once you are satisfied with the layout and content of your data, it is time to label each attribute based on the risk associated with exposing these attributes, and how they can be used by a potential attacker. These are, in decreasing order of risk for re-identification:
- Identifying – Attributes that are unique to each record in the dataset. Examples: Name, Social Security Number.
- Quasi-Identifying – Attributes that, in combination with other quasi-identifiers, can be used to re-identify a record. Examples: Age, race, zip code.
- Sensitive – Attributes that are meant to be private information which are at risk of being exposed in re-identification attacks. Examples: Medical conditions, salary.
- Insensitive – Attributes that cannot be used to re-identify a record or reveal sensitive information about a person. Examples: an already redacted or encrypted name or country.
Generating Output
The last page of the wizard allows you to specify your output folder within the Workbench and a name for the output files. From the information that was collected, the wizard will generate a riskscorer model file which can be used to show your risk score, or to make modifications to previous configurations without having to re-create them from scratch in another wizard session.
The output page also provides an option for creating an HTML report based on the generated score. Once you are satisfied with your input, select Finish to generate your results. They will appear in the workbench and optionally in the folder you specified.
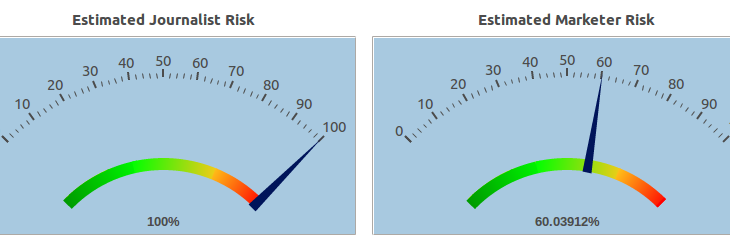
Results: Risk Score
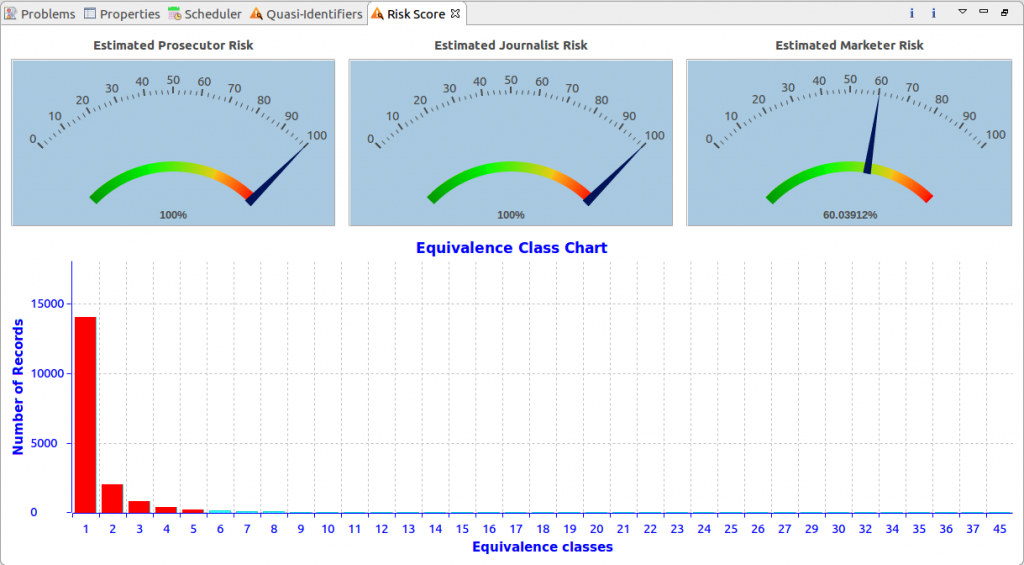
The score view allows you to quantify the risk of re-identification based on the quasi-identifiers in the dataset. The risk is calculated for 3 different attacker models:
- Prosecutor – an attacker targeting a specific record based on their background knowledge of the target.
- Journalist – an attacker with no background knowledge on anyone in the dataset, but is is trying to randomly re-identify a record.
- Marketer – an attacker only interested in re-identifying as many records as possible
The score for your dataset is influenced by 3 factors: the number of records at risk, the highest risk that a record will be re-identified, and the success rate for re-identifying a randomly selected record.
Below the dials is the “Equivalence Class Chart” showing how many records are currently at risk of being re-identified. An equivalence class represents the number of records that share the same set of quasi-identifiers, thus making the records in the class indistinguishable from one another without any background knowledge.
Higher equivalence classes correspond to records that are more protected from re-identification attacks. Although no standard exists for what the lowest equivalence class in a dataset should be, peer-reviewed research suggests that all records should belong to an equivalence class greater than or equal to 5 (that is, a 20% or lower risk of re-identification by chance)3. This is reflected by the red and green bars, which show the amount of records that are at risk or safe, respectively.
Results: Quasi-Identifier Risks
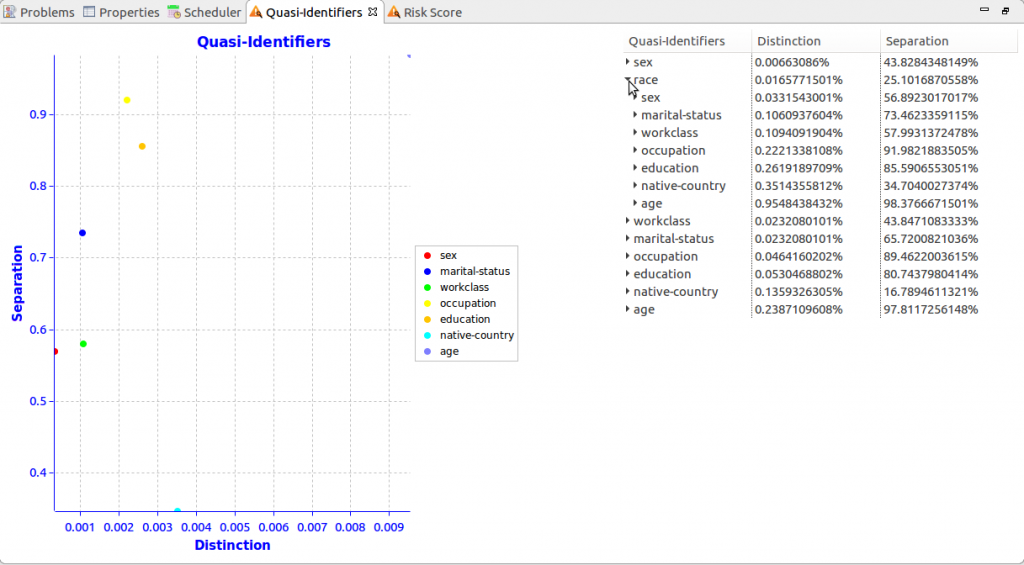
Remember that quasi-identifiers are subset attributes which can be used to identify a record in a dataset, especially when combined with other quasi-identifiers. For example, age alone is a powerful indicator of a person’s identity, but age and race could narrow down the possible identity even more.
To represent the risk associated with the different quasi-identifier combination, IRI provides a view to show how different combinations of quasi-identifiers affect the re-identification risk. It is based on quasi-identifier metrics, distinction and separation.
Distinction represents the ratio between the unique values for the quasi-identifiers and the total number of records. Separation represents the ratio between pairs of records with at least one different value for their quasi-identifiers, and the total number of ways that two different records can be paired4. In general, a higher distinction and separation are indicators that the quasi-identifiers are more likely to re-identify a record.
To figure out the distinction and separation values of different combinations of quasi-identifiers, select the dropdown tab to show those values when that quasi-identifier is used in combination with the remaining quasi-identifiers.
The graph on the left updates its data points to reflect the distinction and separation values of the new quasi-identifier combinations you select in the dropdown tree on right right, which chains several quasi-identifiers together. The last level in the tree represents the distinction and separation values for using every quasi-identifier within your dataset to re-identify the dataset.
Results: Report

The wizard can also generate an html report which saves into the project folder that you specified. The report provides a more formal and verbose representation of the results. Along with the tabs for the different attacker risks, quasi-identifiers, and equivalence classes, the report has additional information on the dataset’s uniqueness that is not displayed in the two views discussed above.
Re-Scoring Dataset and Showing Views
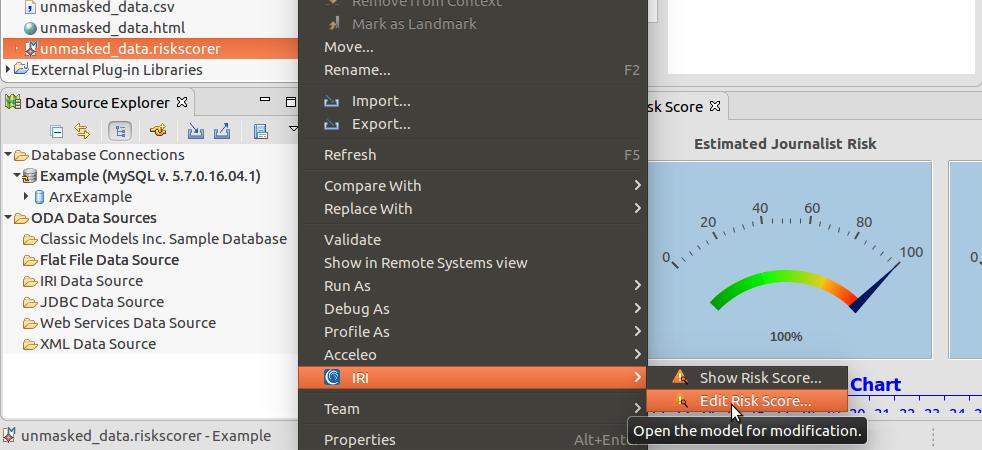
To view or modify the risk score model’s quasi-identifier attributes outside the wizard where you first labeled them, right-click on the .riskscorer file within your project. Click into the IRI options to either show your risk score again — which displays the risk score and quasi-identifiers views for that model — or edit your risk score model so that you can re-use it in the wizard without having to re-label all the attributes again.
Next Steps
Having scored the risk of re-identification for the dataset, it may or may not be necessary to have FieldShield perform further de-identification; i.e., masking missed key-identifiers, or generalizing / blurring quasi-identifiers. IRI can help you with these processes, and also refer you to the services of a certified HIPAA statistician and legal counsel to help you assess and use the results, as well as prepare certification and breach defense paperwork.
IRI provides a course in all of the above, described here. If you need help using the technologies together for HIPAA compliance or another application in which re-identifiability risk is at issue, please contact your IRI representative or expert partner.
- https://epic.org/privacy/reidentification/Sweeney_Article.pdf
- The HIPAA Expert Determination Method (EDM) requires a very low risk of re-identification.
- https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2826964/
- https://ieeexplore.ieee.org/abstract/document/9652545










