Blurring and Bucketing
Indirect identifiers, or "quasi-identifying values" like age and date of birth, as well as descriptors like occupation and marital status, can all be used to re-identify people if there are enough of these attributes in the data set and/or they can be joined to a supersetpopulation with similar values.
For this reason, your jobs in the IRI FieldShield or IRI DarkShield data masking tool (or both within the IRI Voracity data management platform) can apply one or more techniques to anonymize these values while still keeping them realistic and accurate enough for research or marketing purposes. This is also akin to differential privacy because you are replacing individual (direct) identifiers with more general anonymizing demographic information or approximate values (indirect identifiers).
By way of specific IRI-supported techniques, you can perform:
- Numeric blurring functions to create random noise for specified age and date ranges.
- Bucketing functions that generalize the values into broader categories also anonymize quasi-identifiers.
In the example job specification shown below, specific ages are bucketed into decade groups, multiple marital status attributes are combined into two broader categories in a defined condition, educational attainments are simplified through a new set lookup file, and all occupations were explicitly redacted in place.
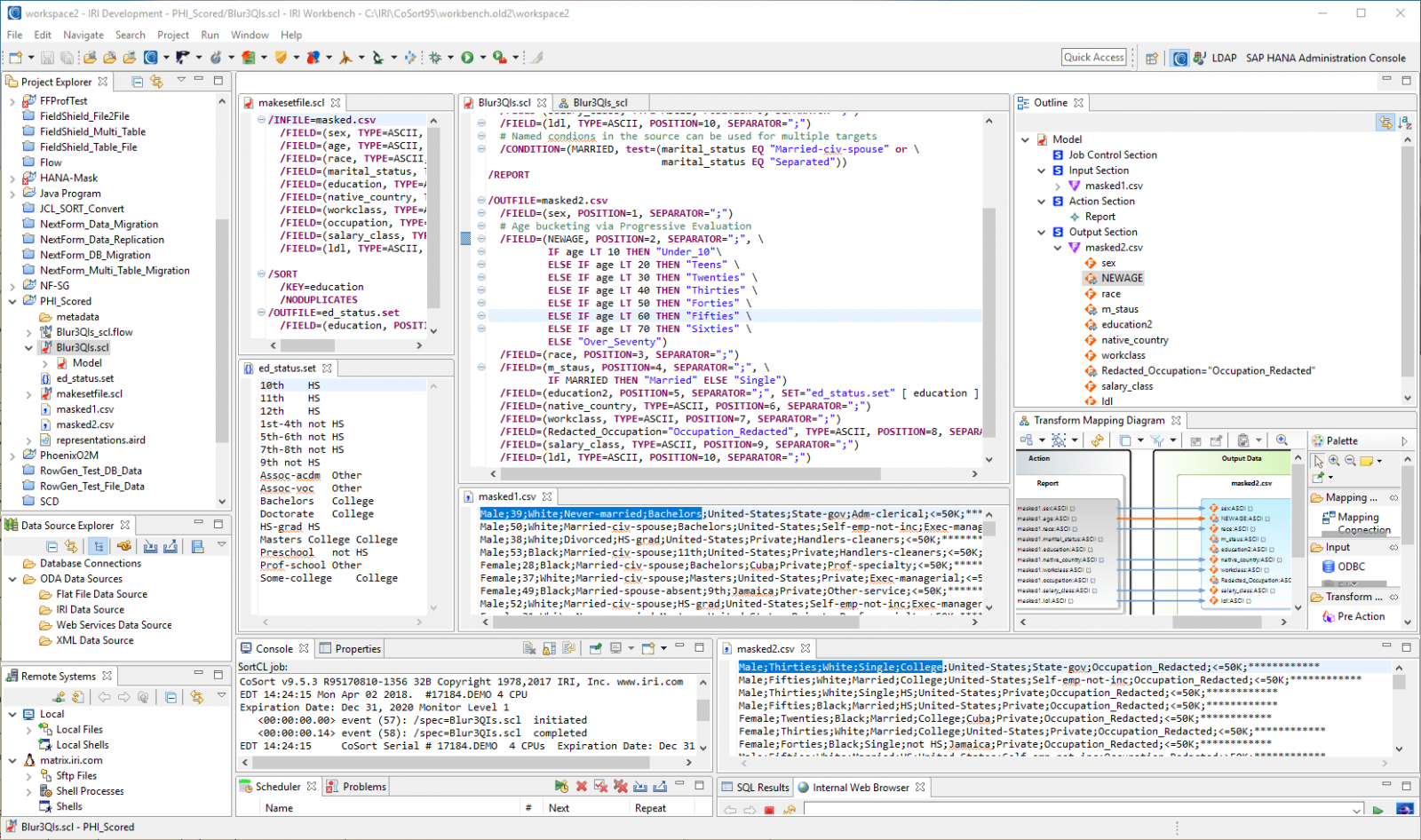
These job specifications can be generated automatically in fit-for-purpose graphical wizards and function-specific dialogs. The new result set can now be re-run through the risk scoring wizard to produce another determination of re-identification risk based on now less distinct quasi-identifying attributes.
