Only IRI Voracity® can manipulate and manage a huge range and volume of data in one affordable Eclipse™ pane of glass. Use it to rapidly and reliably discover, integrate, migrate, govern, and analyze data in every source.
"The IRI Voracity platform has caused me to rethink the relative importance of data processing in information-centric systems, such as data warehouses and lakes. With the right features and sufficient power, a data processing platform can complement and, indeed, extend the function of the databases traditionally considered to be at the core of these systems."
-Barry Devlin, 9sight Consulting
Check out Voracity's capabilities, the challenges it addresses in digital transformations, and its components, below. Explore the other tabs in this section, and the solution areas throughout this website to understand just how much your teams can cooperatively accomplish with the state-of-the-art technology in this platform.
Capabilities
Voracity uniquely combines the discovery, integration, migration, governance, and analysis of data in a variety of sources ... all from one place, and often in one pass. Manipulate, map, migrate, mask, munge, and mine structured, semi-structured, and unstructured data, and produce multiple targets at once.
Challenges
Voracity addresses the challenges of data volume, variety, velocity, veracity, and value with a comprehensive data management platform that eliminates multi-tool complexity and bends the cost curve away from megavendor ETL tools and Hadoop distributions.
Components
Voracity is powered by IRI CoSort and front-ended in a familiar graphical IDE, built on Eclipse™, called IRI Workbench. Beyond a plethora of included features, Eclipse plug-ins and proven partner technology can expand what you can do with Voracity.
Capabilities
Voracity's core data management capabilities leverage the functionality of the IRI CoSort SortCL data definition and manipulation program.
As one of the original and few remaining viable fast processing alternatives to Hadoop, SortCL packages, presents, and provisions big data. It combines: data cleansing, extraction, transformation, loading, masking, reporting -- and even synthetic test data generation -- in the same job script and multi-threaded I/O pass in your existing file system.
If however, you still need the scalability and capability of Hadoop, however, you are covered. Voracity supports the execution of many SortCL jobs in MapReduce2, Spark, Spark Stream, Storm, and Tez. Compare that to Hadoop distributions you are considering, or to the disjointed Apache projects you are trying to coordinate.
All of that work in the middle starts with data discovery. Only Voracity provides at least four data profiling tools. And it ends with analytics, where you have three choices: 1) embedded BI; 2) DataDog, KNIME and Splunk integrations; or, 3) robust data preparation (wrangling) for your chosen data visualization platform.
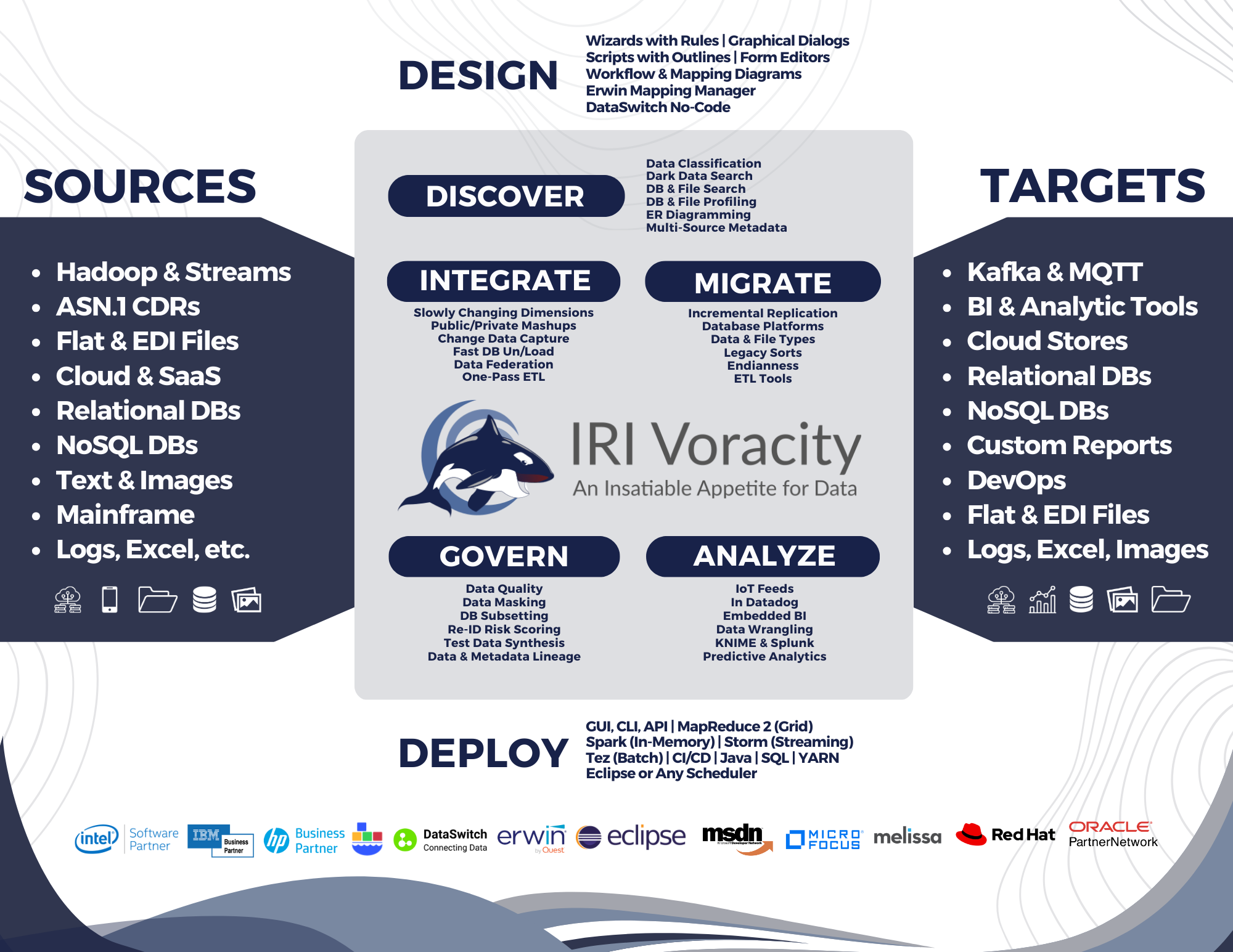
As the above schematic illustrates, Voracity supports the design, deployment and management of all these activities from a single Eclipse pane of glass, IRI Workbench:
- Integrate
- fast DB unload (optional)
- data transformations
- pre-sorted DB loads
- fast, one-pass ETL
- legacy ETLtool speed/leave
- data federation
- data replication
- Migrate
- data types
- file formats
- endian states
- databases
- metadata
- ETL tools
- legacy sorts
- Analyze
- embedded BI
- change data capture
- clickstream
- CDI & segmentation
- slowly changing dimensions
- BIRT, KNIME & Splunk integrations
- data wrangling (blending)
Only Voracity delivers multiple, graphical job design and deployment options in the same Eclipse IDE. And only Voracity uses the latest CoSort engines while also supporting multiple Hadoop engine alternatives from that same GUI which require no additional coding.
So, by embedding mission-critical data integration, migration, and governance capabilities, supporting Hadoop sources and engines, and by front-ending data discovery, EMM, MDM, and workflow in a continually developed Eclipse IDE, Voracity is not only functionally comprehensive, it's uniquely ergonomic, scalable, and future-proofed for new data sources and enterprise information needs.
Challenges
Volume
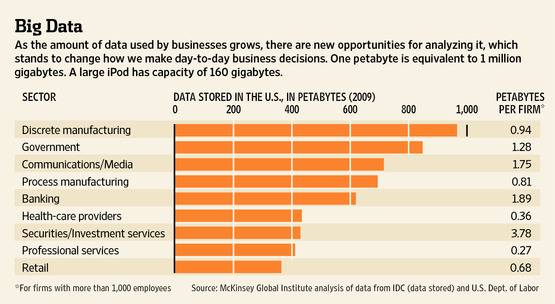
Data sources from internal and public sources is growing exponentially.
Prepare big data subsets for analytics fast by accelerating and combining transforms in your file system -- not in the BI or DB layer. Use Voracity to de-duplicate and filter, sort and join, aggregate and segment, reformat and wrangle data all in one pass. Create reports on the fly as part of the process, too, with embedded BI. Or, send prepared data in memory to BIRT, Datadog, KNIME or Splunk in real-time, or into cubes that your app wants. Otherwise, hand-off wrangled flat-files or RDB view tables for use in those tool, as well as Business Objects, Cognos, Cubeware, iDashboards, Microstrategy, OAC/OBIEE/ODV, PowerBI, QlikView, R, Splunk, Spotfire or Tableau, speeding time-to-display.
The CoSort engine in Voracity processed big data long before it was called big data, running and combining multi-gigabyte transforms in seconds, and besting 3rd-party sort, BI, DB, and ETL tools 2-20X. And when IRI turned 40 in 2018, DW industry guru Dr. Barry Devlin declared Voracity to be a production analytic platform. Learn why here.
And now there are Hadoop options in Voracity too, distributing and scaling huge workloads across commodity hardware via MapReduce2, Spark, Spark Stream, Storm, and Tez.
Variety
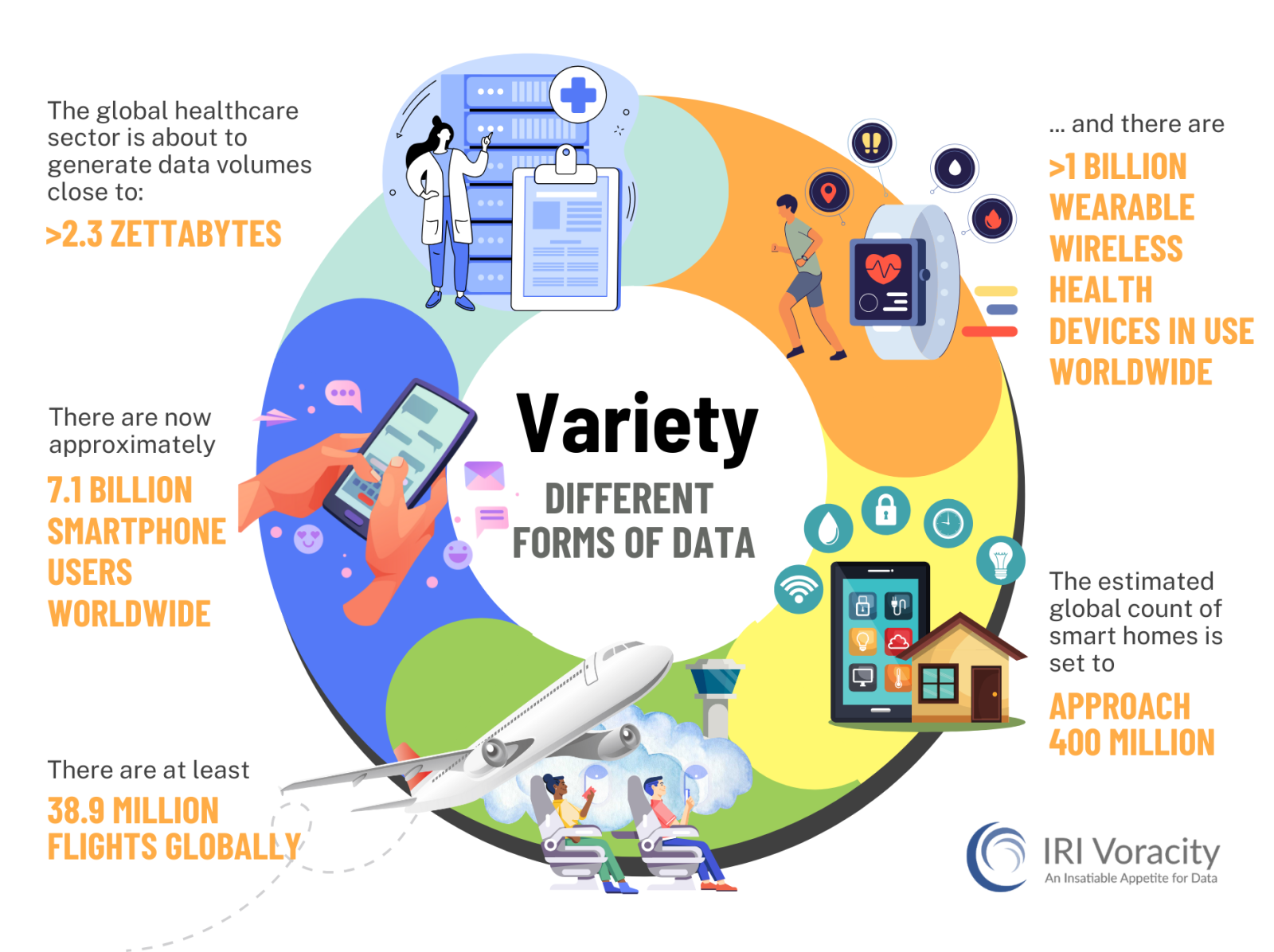
The myriad of structured. sem-structured and unstructured data sources is beyond most tools.
What tools are you using now to discover, extract, process, and analyze all the data you gather or buy? Can you reach and process it all in one pane of glass? Can you quality-control and manage its metadata and master data in that same place? Can you analyze the data there too, or at least rapidly integrate and prepare it for external applications? If you use multiple tools, can you manage the expertise they require? Or if you use a legacy ETL platform, can you bear its cost?
Voracity analyzes, integrates, migrates, governs, profiles, and connects to some 150 different data sources and targets ... structured, semi-structured, and unstructured.
That includes legacy files, data and endian types, as well as popular flat and document file formats, every RDBMS, and newer big data and cloud/SaaS sources.
Velocity
CDR, IOT, social, and other data come fast, and at different intervals.
The biggest data volumes are still processed in regular batch cycles, something Voracity's native CoSort or Hadoop Map Reduce
and Tez options can optimize. But what about the need to process (transform, mask, reformat) and analyze data in real-time for instant promotional campaigns (think mobile devices), or alerts (like traffic and weather notices) that can help drivers or event-goers?
Voracity includes CoSort to integrate data in memory and files, so you can process big data 6X faster than ETL tools, 10X faster than SQL, and 20X faster than BI/analytic tools. Its typical mode, including CDC, is batch.
Voracity can process real-time, near-real-time, and streaming data through Kafka or MQTT brokers, in memory via pipes or input procedures to CoSort, or in Hadoop Spark or Storm engines ... all from the same Eclipse GUI, IRI Workbench. Other options include using the built-in job launcher to spawn Voracity jobs in near-real-time intervals, or using specialized BAM or CEP tools for managing event-driven activity.
Veracity
Low quality data jeopardizes apps and analytic value. PII is another data risk.
Garbage in = garbage out, and thus data in doubt. Data quality suffers from inconsistent, inaccurate, or incomplete values. Social media data can be deceptive, unstructured data imprecise, and data ambiguity plagues MDM. Survey data can be biased, noisy or abnormal. Meanwhile, PII and secrets contained in all that data mean you have to mask it prior to shared use. Do you have a central point of control for cleaning data and making it safe?
Voracity's data discovery, fuzzy matching, value validation, scrubbing, enrichment, and unification features all improve data quality.
Voracity's comprehensive data masking functions and synthetic test data generation capabilities remove the risk of data breaches and poor prototypes.
Value
And the point of it all ... getting analytic value from big data.
Consider your information and decision needs from data. For example, are you tracking consumer behavior, weather patterns, device or web log activity so that you can change promotions, make predictions, or diagnose problems? Do you see the value in an IDE easy enough for self-service data preparation and presentation, but powerful enough for IT and business user collaboration in data lifecycle management? And if you use BIRT, KNIME or Splunk, can you get data into those structures as it's being wrangled?
Components
The default Voracity stack uses IRI Workbench for client-side design of data-driven jobs defined in portable scripts represented in multiple graphical UIs.
Structured data processing performed in Voracity components is powered by the proven IRI CoSort engine, and its SortCLdata definition and manipulation program in particular. In addition, some of the same jobs coded for SortCL can run interchangeably in Hadoop MR2, Spark, Spark Stream, Storm or Tez.
Voracity metadata and related job script parameters are fully supported in the Workbench data model and optionally in Erwin (Quest) Mapping Manager, for graphical creation, modification, and management.
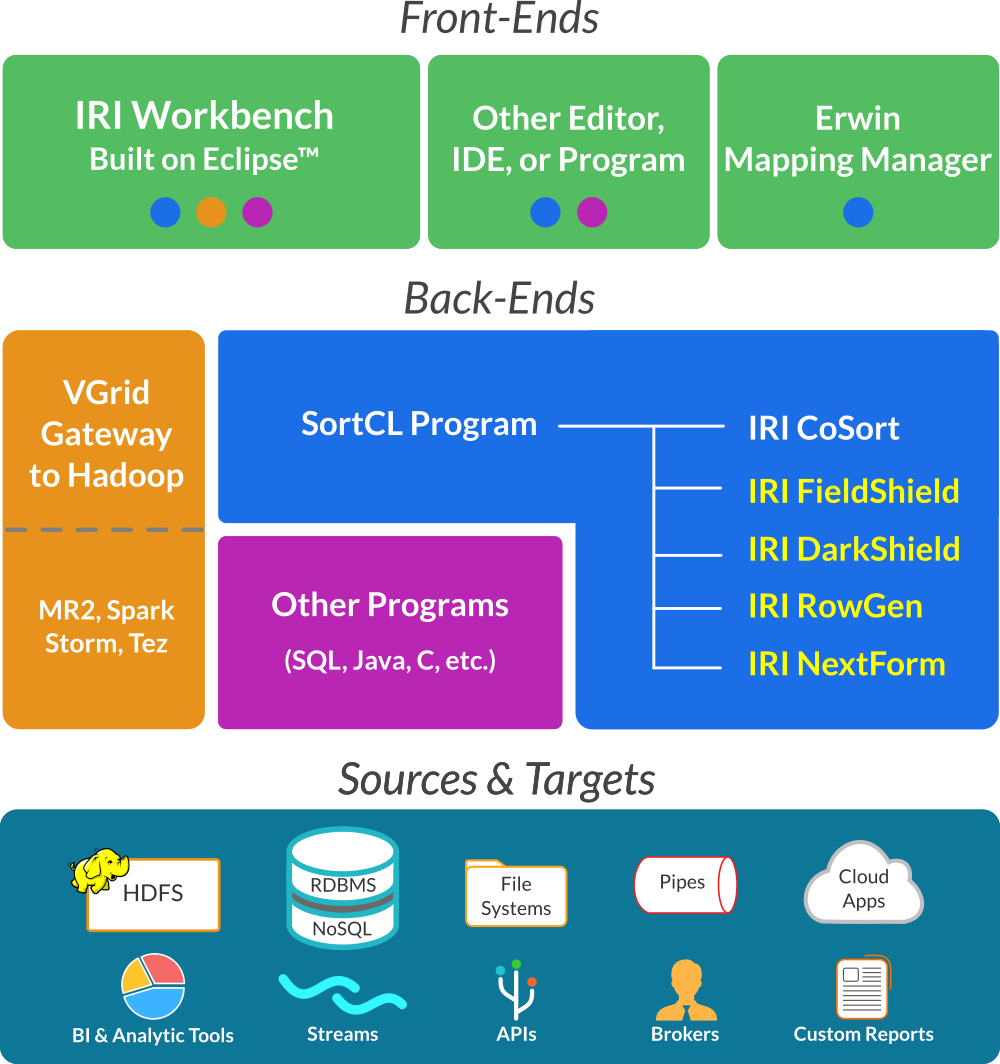
Within the base Voracity package are:
- DB, flat-file, and dark data profiling, ERD, and metadata definition wizards
- key data processing features of constituent IRI Data Manager products
- key data security features of constituent IRI Data Protector products
- multiple, re-entrant job design options and execution paradigms
- runtime and metadata SDKs for application development
- robust GUI help content and CLI reference manuals

More specifically, Voracity includes free use of a rich, familiar front-end job design and management environment called IRI Workbench, built on Eclipse™. Together with Voracity's back-end production engine you can run anywhere, IRI Workbench supports the capabilities of:
- IRI CoSort for big data manipulation and movement, including EDW integration (ETL) and data preparation for DBs and analytic tools, embedded BI, data quality, metadata and master data management, legacy sort migration, and data governance
- IRI NextForm for data and DB migration, data replication, remapping, and federation
- IRI FieldShield for masking PII in flat files and relational databases, IRI CellShieldEE for Excel®, and IRI DarkShield for structured, semi-structured, and unstructured sources.
- IRI Ripcurrent for real-time, incremental DB refresh (replication and masking) of Oracle, MS SQL, MySQL, and PostgreSQL
- IRI RowGen for generating synthetic but realistic file, database, and report test data
Additional capabilities of IRI Workbench include:
- default and plug-in shell UIsfor command line execution and interaction
- multiple data profiling and metadata discovery and definition wizards
- metadata management and master data management (MDM)
- ODA-integrationfor BIRT (visual analytics) and native source node for KNIME
- Sirius workflow, transform mapping, and E-R diagrams
Beyond the base edition, premium options include:
- DataSwitch | no-code IRI-enabled ETL job migration, data engineering and self-service BI/democratization
- Erwin ETL conversion | automated job/metadata migration from other ETL tools
- Erwin Mapping Manager | code-free source-target ETL mapping/flow generation
- CONNX drivers | move/manipulate mainframe and other proprietary data
- DataDirect drivers | move/manipulate big data and cloud/SaaS data
- DW Digest | cloud dashboard for interactive BI
- IRI FACT | parallel unload of Oracle and 6 other VLDB tables to files
- Hadoop runtimes | MapReduce2, Spark, Spark Stream, Storm, and Tez options
- OSS Nokalva runtime | move/manipulate ASN.1-compatible CDR files
- Value Labs Test Data Hub | on-demand IRI-enabled test data management portal
- Windocks | database virtualization and IRI-enabled test image provisioning
Whether included with the base Voracity package, or installed as partner technology, everything runs in IRI Workbench and leverages the same, open data and manipulation metadata infrastructure for job management and deployment ... inside or outside that GUI.
See the product information matrix to see what's provided at a glance, and review the feature-benefit charts for more details.
