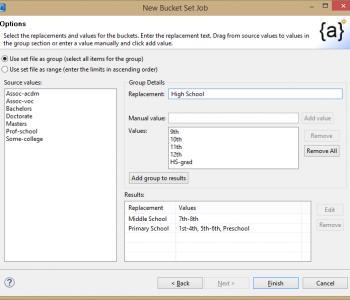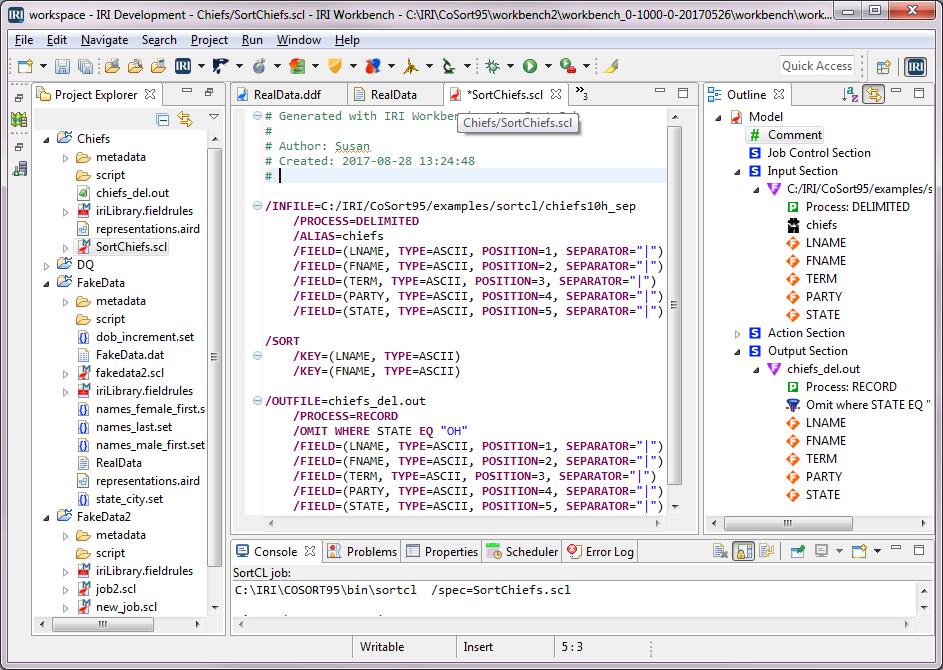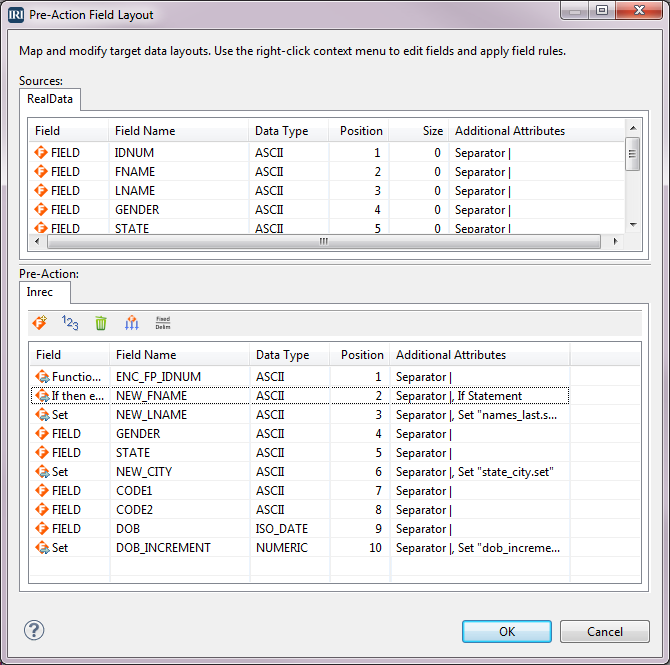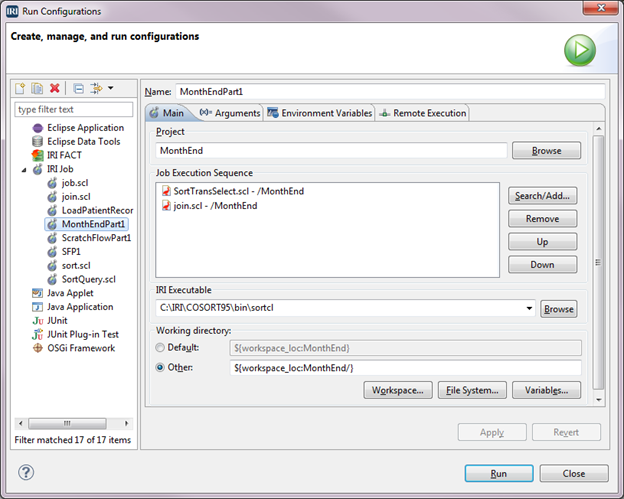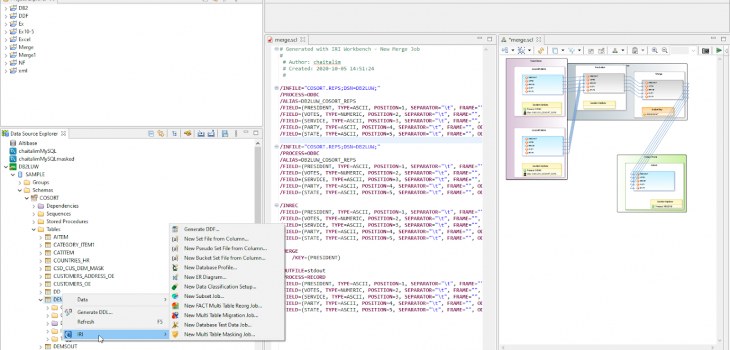
Connecting IBM DB2 with IRI Software
Like previous articles in this blog on the connection and configuration of other relational databases with the IRI Voracity data management platform — and its ecosystem products: CoSort, NextForm, FieldShield, DarkShield and RowGen — this article details how to reach DB2 sources. Read More