Managing and Masking SharePoint Data with Voracity
This article explains how to connect with, and use data from, SharePoint sites — using the file system via OneDrive — for operations in IRI Workbench-supported data management software. Read More
This article explains how to connect with, and use data from, SharePoint sites — using the file system via OneDrive — for operations in IRI Workbench-supported data management software. Read More
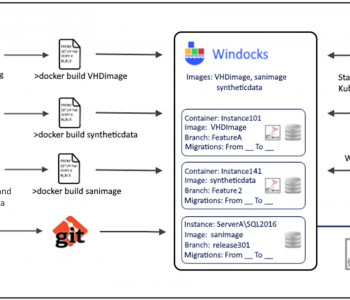
Abstract: IRI has partnered with Windocks to provide an on-demand, test-ready virtualized repository that delivers masked, subsetted or synthesized databases in seconds for Docker containers, conventional instances, or workstations. Read More
IRI DarkShield can search for, and mask, personally identifiable information (PII) and other sensitive data in many different file types, documents and databases on-premise or in the cloud. Read More
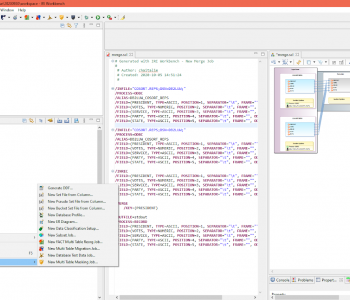
Like previous articles in this blog on the connection and configuration of other relational databases with the IRI Voracity data management platform — and its ecosystem products: CoSort, NextForm, FieldShield, DarkShield and RowGen — this article details how to reach DB2 sources. Read More
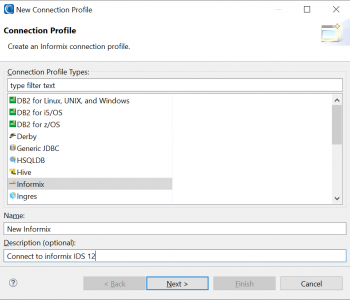
This article documents the database connectivity tools and configurations necessary in IRI Workbench and 64-bit CoSort-compatible runtime environments to work with 64-bit Informix Dynamic Server (IDS) v12 table sources and targets. Read More
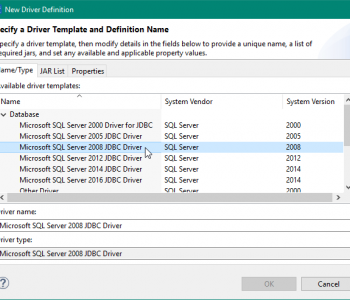
Whether your SQL Server database is on-premise or in a cloud enviroment like Azure, its data is accessible for movement and manipulation in IRI Workbench-supported products like CoSort, FieldShield, DarkShield, NextForm and RowGen, or the IRI Voracity platform which includes them all. Read More
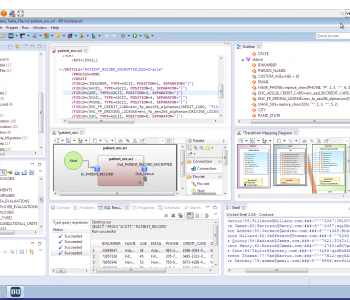
Usually static data masking is performed on production data at rest so it is stored safely, or when replicated to non-production environments for testing or development purposes. Read More
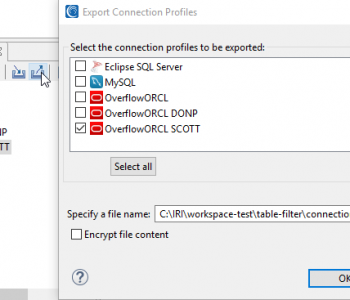
IRI Workbench provides a number of features for working across multiple tables in a database. It includes wizards to: profile databases; classify columns; subset, mask and migrate data; generate test data; etc. Read More
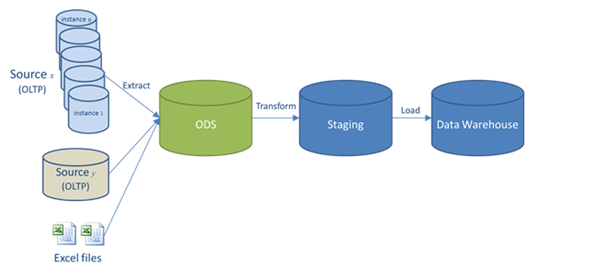
An operational data store (or “ODS”) is another paradigm for integrating enterprise data that is relatively simpler than a data warehouse (DW). Read More
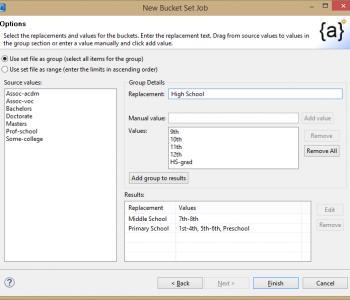
Editors Note: This articles covers data anonymization as a form of data masking for privacy protection. In particular, it covers the concepts of quasi-identifiers and re-identification risk and the use of HIPAA data de-identification standards for protecting sensitive data in research through the use of anonymizing techniques like age blurring and demographic attribute blurring in conjunction with re-ID risk scoring. Read More

Random noise data masking, or blurring, is a common requirement for PII anonymization in healthcare data, particularly for researchers and marketers of protected health information (PHI) seeking to comply with the HIPAA Expert Determination Method security rule. Read More