
Blurring Ages and Dates to Anonymize PHI
Random noise data masking, or blurring, is a common requirement for PII anonymization in healthcare data, particularly for researchers and marketers of protected health information (PHI) seeking to comply with the HIPAA Expert Determination Method security rule. Adding random noise to date, or other integer values is one of several PII data anonymization and de-identification techniques included in the IRI FieldShield and IRI DarkShield HIPAA data masking tools, and the broader IRI Voracity data management platform which includes them.
Moreover, blurring can be used along with other data generalization techniques like bucketing to improve re-ID risk scores by anonymizing direct (key) or demographic (quasi-) identifiers. Specifically, the goal is to change the values of like ages or dates (of birth, admission, treatment, etc.) that will make them less susceptible to re-identification, but still preserve their utility for research or marketing purposes.
It is also possible to use ‘lesser’ masking functions on dates, too, like a mathematical (e.g., add 10 to each age) or date calculation. Either way however, you can also preserve consistent date intervals in HIPAA and related data privacy scenarios like admit-discharge; ask us how if this is a requirement.
More specifically, the IRI blur_age and blur_date functions, along with blur_int and blur_int_pct are related data anonymization techniques designed to read input values and return similar but not identical values. The functions randomly blur a number or date within a certain range of the original number via a “blur factor”, but also keep the new number within a minimum and maximum value.
How the Functions Work
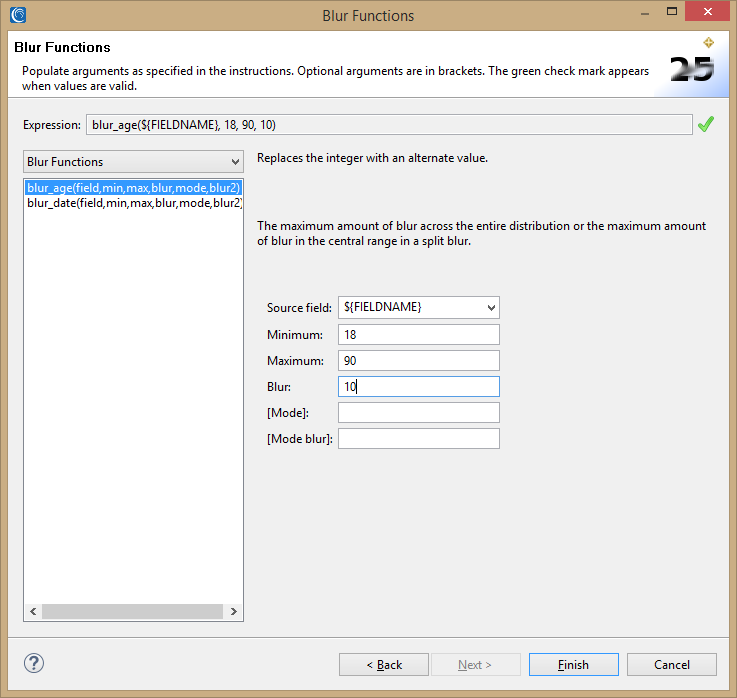
Age blurring uses a function that can take either four or six arguments. The first set of arguments needs an original age, a minimum age, a maximum age, and a blur factor. The blur factor will determine the range that the function will change the original value. A blur factor of 10 will randomly pick a value between -10 and 10 years and then add it to the original value. The random blur will never pick zero unless the blur itself is set to zero.
The second set of arguments ask for two more inputs: a mode age and a second blur factor. The mode age is intended to be the mode of the data or another value that can be interpreted as the middle. Any age found within a certain distance of the mode is blurred by the second blur factor. The distance is the midpoint between the minimum and mode as well as the midpoint between the maximum and mode. This allows the function to adapt if the data distribution is skewed from the center.
The blur library contains the function blur_age. Its forms are:
blur_age(AGE, MIN_AGE, MAX_AGE, BLUR_FACTOR)
blur_age(AGE, MIN_AGE, MAX_AGE, BLUR_FACTOR, MODE_AGE, MODE_BLUR_FACTOR)

Date blurring follows a format similar to age blurring but uses the a date as its input and output. The function supports ISO, American, and European date formats. Respectively, their forms are yyyy-mm-dd, mm/dd/yyyy, and dd.mm.yyyy. The random blur factors for these functions is in days and will change month and year if the new date is past the last day of the month or before the first.
To blur dates for data privacy, use he blur_date function. This function is contained within the IRI dates library and exposed as one of four Blurring Functions in the Data Masking rule dialog in IRI Workbench (see below). Its forms are:
blur_date (DATE, MIN_DATE, MAX_DATE, BLUR_FACTOR)
blur_date (DATE, MIN_DATE, MAX_DATE, BLUR_FACTOR, MODE_DATE, MODE_BLUR_FACTOR)
The blur_int function for standard integers with a relatively limited range between low (min) and high (max) values takes the form:
blur_int(FIELD, MIN, MAX, BLUR, MODE, BLUR2)
while the blur_int_pct function form only contemplates a percentage of blurring, which is better for values that may span a very large range:
blur_int_pct(FIELD, PERCENT_AMOUNT)
Examples
Function Calls
/FIELD=(EXPRESSION_AGE=blur_age(AGE, 18, 90, 10), TYPE=NUMERIC, PRECISION=0, POSITION=1, PRECISION=0, SEPARATOR="|")
/FIELD=(EXPRESSION_DATE=blur_date(DATE, "1982-12-31", 30), TYPE=ISO_DATE ...
| Input | Ouput |
|---|---|
| 61|1982-01-12 | 62|1982-02-01 |
| 81|1982-12-16 | 72|1982-11-17 |
| 58|1982-11-29 | 66|1982-11-24 |
| 23|1982-03-05 | 19|1982-02-13 |
| 24|1982-11-18 | 21|1982-12-09 |
| 42|1982-05-26 | 43|1982-06-14 |
| 28|1982-09-21 | 26|1982-09-10 |
| 63|1982-06-13 | 60|1982-07-07 |
| 83|1982-03-08 | 87|1982-03-02 |
| 30|1982-05-27 | 33|1982-06-23 |
| 37|1982-04-20 | 30|1982-03-21 |
| 90|1982-10-15 | 81|1982-10-23 |
| 63|1982-06-21 | 66|1982-07-03 |
| 72|1982-04-19 | 76|1982-05-03 |
Graphical specification of blur function parameters into data masking jobs is available in IRI Workbench. The Blur Functions dialog described below is launched from the list of available protection rules that can apply in data classification or FieldShield job design:
Additionally, the functions can be saved as rules so that they can be reused.
Choosing Blur Functions open this dialog:
For numbers which may fall into a large range, the function blur_int_pct blurs an integer by a percentage of its value. This handles uses cases where blurring a number by up to 200, for example, is insignificant if the original value is 20,000, and inappropriate if the original value is 20. A 10 percent blur might blur 20 by up to plus or minus 2, while blurring 20,000 by 10% will vary the result up to plus or minus 2,000.
For each and every field value passed to the function, the percentage is applied to the value, and that becomes the blurring factor. Assuming a specified blur percentage of 25. A value of 20 would be blurred by a random amount between -5 and +5, a value of 2,000 would be blurred by a random amount between -500 and +500.
Behaviors for Bad Data
In case the value of the first argument is less than the minimum or greater than the maximum, the new value will default to the minimum or maximum value. This applies to all the blurring functions.
Blur factors that are larger than the actual distance between the minimum and maximum will be ignored. Instead, it will create a value between the minimum and maximum. A similar behavior will occur for the mode blur factor.
The blur_age function will return a bad value error if the first argument read in is not an integer. This function will also accept negative values as long as they are integers.
If blur_date encounters a value that is not an ISO_DATE, AMERICAN_DATE, EUROPEAN_DATE, it will return “not-a-date-time”. This is the default value for the Boost library variables IRI uses, and will return it if the variable is not set correctly or not set at all.
If you are interested these functions or PII anonymization in healthcare data specifically, please contact info@iri.com.










