Real-Time, Incremental Data Masking
Abstract: The previous article in this series of 4 demonstrated real-time database replication with IRI Ripcurrent, an IRI-developed command-line Java application that utilizes the Debezium embedded engine and the streaming features of the IRI (CoSort) SortCL program. Together they react in real-time to database change events.
The capability demonstrated in the previous article can also be augmented with the classification and masking of sensitive data in transit to file or database targets. When data in the source table is inserted or updated, it is moved and masked in real-time to the designated target table using rules defined in the IRI FieldShield data masking tool. When data in the source table is deleted, the same row(s) will be deleted in the (different) target table.
Prerequisites
Assuming the prerequisites detailed in the first article have been met, for this case an IRI Data Class & Rule Library are also required.
For Ripcurrent, a default rule is required to be assigned for each data class. The default rule is used by Ripcurrent to apply a chosen masking function to data or a column name matching the specified data class search parameters.
Generating a Ripcurrent Properties File
Before running Ripcurrent, a property file should be created to define configuration options that are required for Ripcurrent to run.
After installing the Ripcurrent feature in IRI Workbench, the Ripcurrent Properties Generator wizard is available from the Voracity menu to assist in generating a properties file for Ripcurrent.
On the first page of the wizard, options can be specified pertaining to the database to be monitored. In this image, an Oracle connection was selected and a filter was specified to narrow down the tables to be monitored to only those in the SCOTT schema.
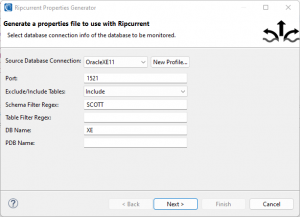
In this case, the DB name (required to set up a configuration to monitor an Oracle database) was also entered, XE in this case.
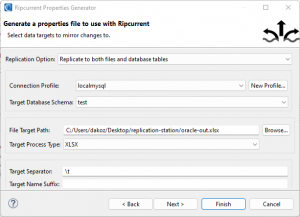
On the second page of the wizard, there are options to replicate to database tables, files, or both files and database tables. The image shows the choice of replicating data changes from the source Oracle database to a MySQL database with existing tables of the same name and structure as the source database, as well as to Excel files.
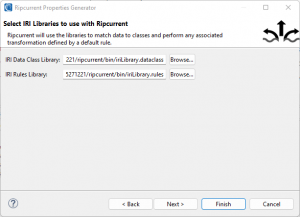
On the third page, locations of an IRI data class library and rule library can be specified. The image shows the selection of the library files created earlier in the article:
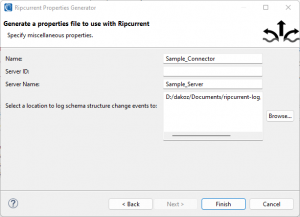
On the final page, the image shows the selection of a log location for structural change event information from the source database. Names for the connector and server connection used by Debezium are also specified.
After the properties file was successfully generated for my configurations, I began the execution of Ripcurrent by running the ripcurrent.bat script. After completion of an initial snapshot of the source database (if running for the first time), Ripcurrent will be monitoring for changes from the source database.
Adding Test Data to Source Tables with IRI RowGen
Next, I will run a batch file generated by the New Database Test Data wizard, accessible from the IRI RowGen menu to synthesize and simulate new data coming into the source tables. The New Database Test Data wizard synthesizes data consistently by classifying database columns and pairing them with generation rules.
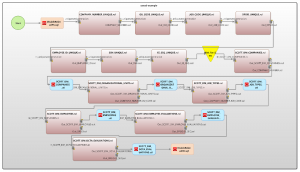
The image below shows an entity-relationship mapping diagram of the test data batch operation, produced in the IRI Workbench GUI for all IRI software.
Replication of Data from Source Tables to Multiple Targets, with Consistent Masking Rules Applied to Classified Data
After running the batch file to generate data for 5 tables in the source database, Ripcurrent recognized the new data inserted and triggered a replication and masking operation to the targets.
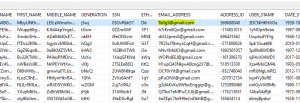
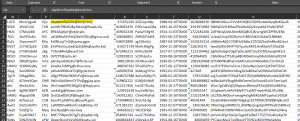
This is a sample of the data that was generated in one of the source Oracle database tables (named DM_EMPLOYEES):
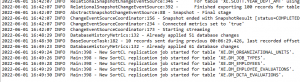
Ripcurrent was silently triggered by this insertion event, and automatically masked and moved the new data into its defined targets, per this event log:
See that a series of Excel files have also been created in the target directory:
In the Excel file associated with the DM_EMPLOYEES table in the source database, notice that the email values have been modified from the original value.
Additionally, in the target MySQL database, data was replicated to a table with the same name and structure as the source table, with the email address column encrypted to the same values as in the Excel file.
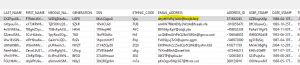
This column was classified as containing email addresses based on the regular expression pattern to match emails defined in the data class library. The original email values were encrypted with format-preserving encryption, defined by the default rule that was mapped to the EMAIL data class.
Conclusion
This article demonstrated another use case of Ripcurrent that builds on the database data replication process demonstrated in the previous article – that is, consistent data classification, data masking and data replication as rows are inserted, updated or deleted in source tables and refresh into target tables (usually in a lower environment).
This approach ensures that data can be dynamically replicated to test schema, with sensitive data classified appropriately and consistently masked according to data classes and rules that can be flexibly defined.
The next and final article in this series deals with real-time notifications of structural changes to the database which can impact the layout of the source or target tables. This would indicate the need to re-run data class search operations on your tables.
Frequently Asked Questions (FAQs)










