How to Generate DB Test Data
IRI RowGen users can generate structurally and referentially correct synthetic test data for an entire database in a single operation. The test data reflects production characteristics (such as values ranges and frequencies) normally encountered in database or ETL operations, but does not require access to, or the masking of, real data.
End-user job wizards for RowGen in the IRI Workbench GUI (built on Eclipse™) aid in test data generation. One of the most useful is the New RowGen Database Test Data Job wizard, which builds an entire RowGen project to auto-populate multiple tables at once with pre-sorted key values and the opportunity for customization. Though it relies on existing metadata for each test table, you can also customize — and generalize via rules — the generation of column values.
In this article, I will demonstrate how you can use IRI Workbench to create target tables in Oracle and diagram their schema, and then use one of its RowGen wizards to generate and load test data into those tables.
As an aside, I also want RowGen to insert randomly selected real values into certain columns from set file data. A set file is text file with one or more rows, which can have multiple, tab-delimited columns you supply or auto-extract in another Workbench wizard, Set File from Column. In my case, however, I created my set files manually: emp.set, item.set, project.set, quantity.set, salary.set, department.set, and category.set.
Here are the steps I followed, noting that I had my target table information, and that you will need the same:
Step 1. Create Empty Target Tables
- Establish the database (Oracle in this case) connection via JDBC in IRI Workbench’s Data Source Explorer (DSE)
- Specify Dept, Emp, Project, Category, Item, Item_Use, Sale by writing their CREATE TABLE and ALTER TABLE statements into an .sql file edited in DSE’s SQL scrapbook
- Save it in a Project folder and right click on it to Execute the SQL file to build the tables
Step 2. Create & Show their ER Diagram
- From above the toolbar, select New, IRI Project and create a New Folder
- Click on that folder, then highlight the 7 new tables above in the DSE
- Right click on IRI, then select New ER diagram model
- This creates a new schema model and file, schema.sqlschema, in your project folder
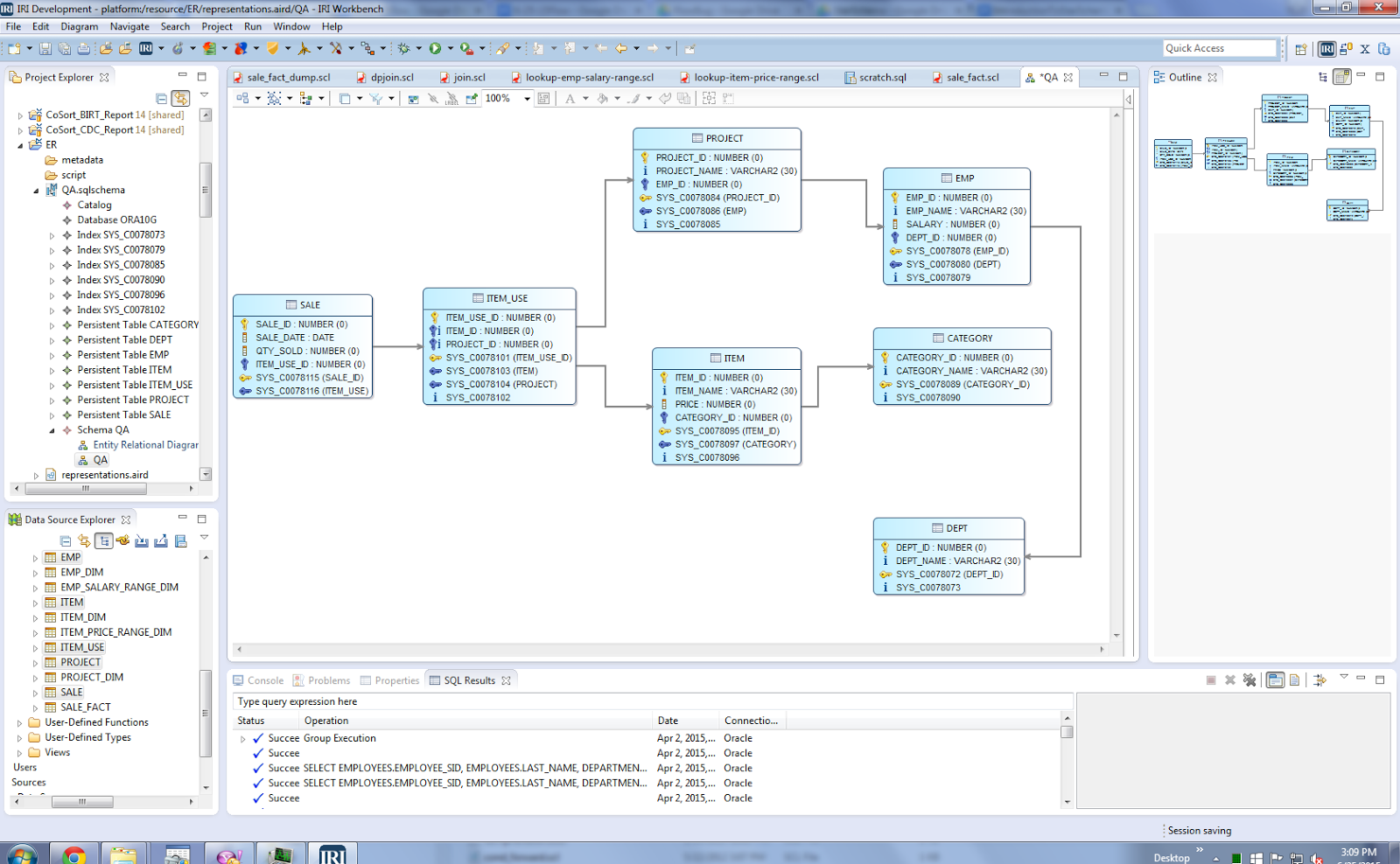
Note that the DSE and the ER Diagramming tool from IRI are both DB-agnostic.
Step 3. Produce Test Data with the RowGen Database Test Data Wizard
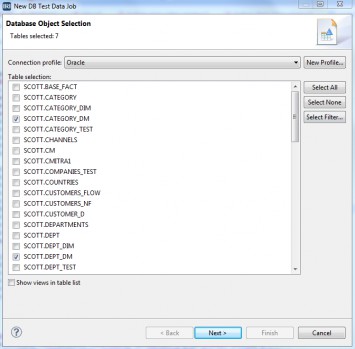
- CTRL-click to select those 7 tables in the DSE again
- Right click and select IRI, New Database Test Data Job
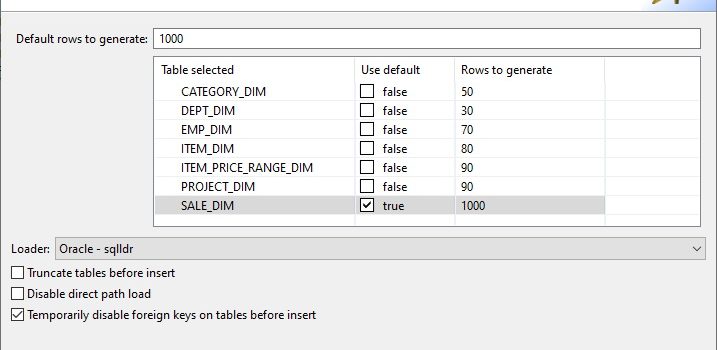
- Click Next when the wizard opens, as you’d already pre-selected the tables to populate:
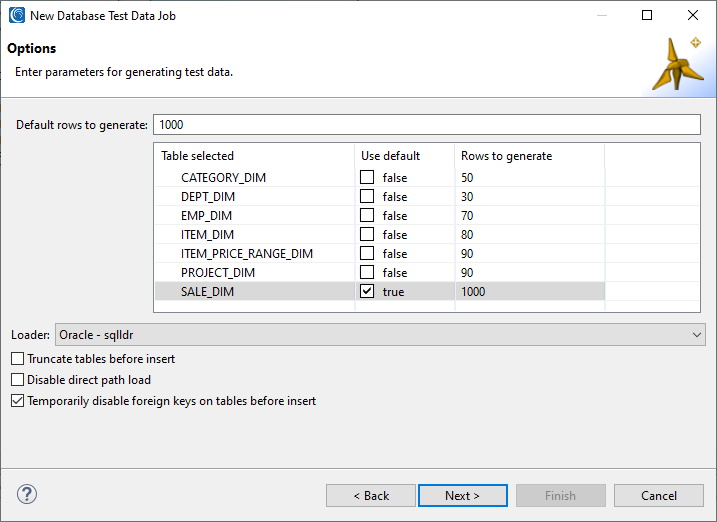
- Click Next to advance to the Rules Configuration dialog, where you can add or modify various field-level generation rules generated graphically in dialogs from the Rule Selector:
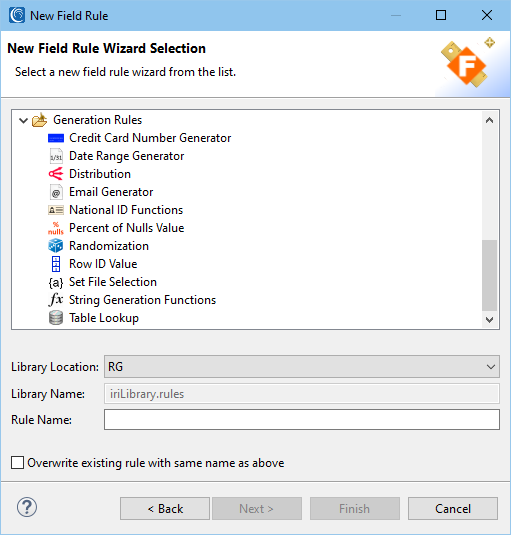
As this is where I will conditionally insert randomly selected real data (from my set files), in like columns across several tables, I will apply the generation as rule whenever the column name conforms to a pattern I specify.
- I’m starting my application of set data with ‘item’ from that file, and so now add the pattern field add Item_Name* and click test for matches to verify if (and where) that column name exists
- Next, select a field from the Rule Options menu and select Set File. I browse to my item.set file to specify its use in any column named as or like Item_Name.
- I repeat these steps to apply data from my set files for columns named for Category_Name, Dept_Num, Emp_Name, Item_Name to enhance test data realism:
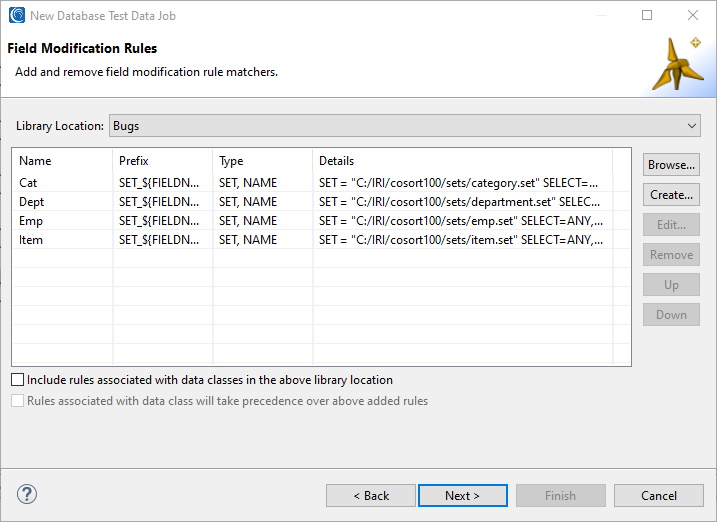
- Click Next to arrive at this job summary screen:
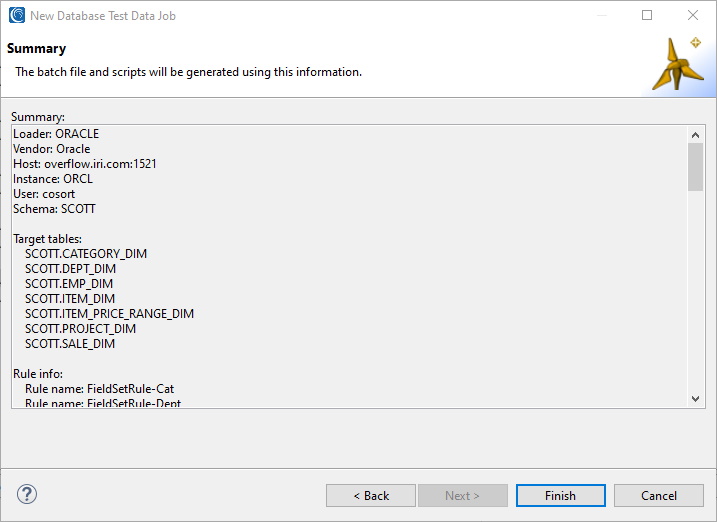
- Click Finish to complete the wizard.
The RowGen wizard automatically created the plain-text (.rcl) control language scripts that specify the generation of test data for each table, as well as dependent set files (for referential integrity), SQL*Loader control files, and a batch file to execute everything at once, in or outside the IRI Workbench.
Running the batch file that RowGen produced creates all the necessary test data in flat files, and populates all the target tables with that data as you chose in the wizard (via ODBC or your DB load utility), in the order necessary to preserve primary-foreign key relationships. The bulk-loaded tables were pre-sorted on the index key for each table, and the values in the set files were randomly inserted into the right columns.
This IRI Workbench screenshot shows one of the RowGen job scripts and a target table:
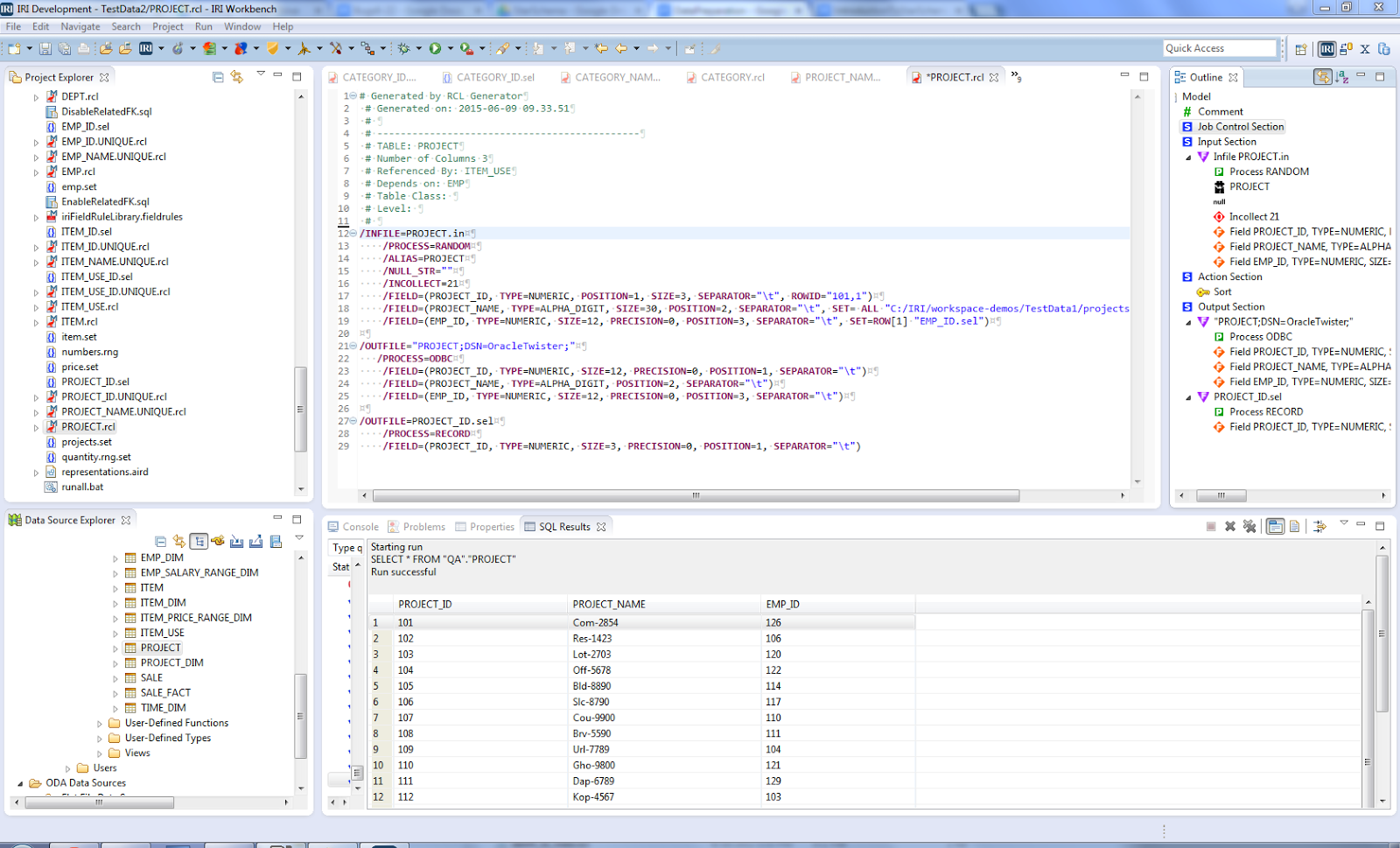
All the RowGen job scripts were saved in the folder I’d selected in the beginning, and are available for modification, reuse, team sharing, version control, etc. The job flow model created for the test data generation can also be diagrammed in the visual workflow editor, with ETL and other IRI data management projects.
Contact rowgen@iri.com if you need help planning for, or using, this wizard.