
IRI Data Quality and Improvement
It always bears repeating that being able to serve up high-quality data is really important. This is partly because the consequences of poor data quality can be severe – misleading analytics, stymied processes, greater storage costs (due to duplicated data), and so on – but also because historically many organizations have not treated data quality as the priority it should be.
Since it is traditionally a negative sell (on the grounds that bad quality leads to bad outcomes, which is entirely correct but not terribly effective as a sales tactic) this is unsurprising but still disappointing. In turn, this means that data quality issues tend to be addressed reactively, which is to say when they start causing problems that are so significant they can’t be ignored.

Negative sales are generally unappealing…until it’s too late
Of course, by this point data quality is typically so poor that the existing data needs to be improved substantially just to get to a reasonable standard. Then that standard needs to be maintained to avoid history repeating itself. There are, fundamentally, two ways to do this …
First and obviously, you can periodically check the quality of your data and remediate it when that quality dips. Secondly, you can improve your business processes in order to produce higher-quality data as the default. The latter could be through the explicit incorporation of data quality checking and remediation, or it could be a matter of building processes that are more robust and less error-prone. Most effective solutions will incorporate both of these techniques.
IRI provides both data quality and data improvement through its data management platform. The relevant capabilities available in IRI Voracity are shown in the image above and are generally what you would expect from a competent data quality solution, incorporating discovery, remediation, deduplication, and whatnot.
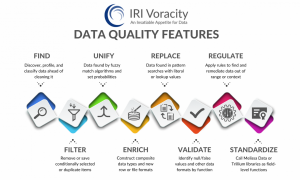
Notably, IRI Workbench – an Eclipse-based IDE and the platform’s GUI – supports a selection of data quality rules, including cleansing, enrichment, and validation, to be used principally as part of IRI CoSort data transformations, which may also be inside Voracity ETL, reporting and data wrangling jobs. This means you can use Voracity to build data quality into your business processes (your workflows, say) as described above.
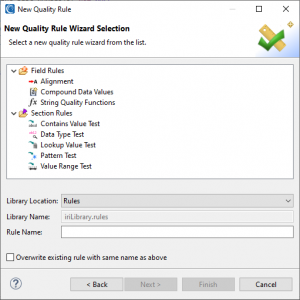
There are rules provided for all sorts of use cases, including both field- and section-level data quality, with the former allowing you to amend field contents when those tests fail, and the latter providing tests that look for values, data types, patterns, and so on within in atomic data sources and targets (e.g., files and tables).
IRI Workbench also offers a wizard for consolidating duplicate, or near-duplicate, data in databases and files. Various methods for identifying the duplicates are provided, including both exact and fuzzy matching methods. Elsewhere in the platform, phonetic matching methods are also offered, meaning that you could figure out – for example – that a phone operator heard and recorded “John” when the customer said their name was “Joan”, then amend accordingly.
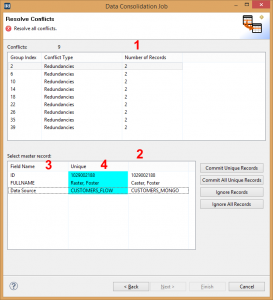
IRI Workbench data consolidation wizard
It’s also important to realize that CoSort (and Voracity by extension) data validation jobs can also run off of template structures that define specific data types and formats, including custom patterns that can be used for reformatting and standardization.
For our purposes this has two major advantages: it means that any new data will rigidly conform to its type’s template, and it makes it very easy for the platform to recognize when a piece of data has broken with its corresponding template and needs to be remediated. Format templates can be constructed in IRI Workbench, or scripted directly if you choose. Moreover, templates are centralized and promote reuse, as the name suggests.
Finally, we should also point out that IRI does not stand alone when it comes to data quality: in fact, it can invoke standardization libraries supported by various third-party solutions – including Melissa Data and Trillium – at the field level within CoSort data transformation and reporting (or Voracity ETL and masking) jobs.
All in all, there are several ways to validate, enrich, and homogenize data in the Voracity ecosystem, either on an ad hoc or rule basis to sanitize data targets, improve the accuracy of analytics, etc. More information about these options can be found (and link) on this page.










