IRI Script Reuse Techniques for Fewer and More Flexible…
Designing for reuse is a common cost-saving technique used in the software industry that can be applied to IRI SortCL (Sort Control Language)-compatible job design. Designing for reuse can result in a smaller inventory of scripts; and reduce script development, maintenance and execution costs. This post covers several techniques for applying reuse concepts to IRI scripts.
IRI software product users with structured data define their source and target metadata, and their data manipulations, in scripts that use the fourth generation CoSort SortCL language. These job scripts are used in:
- IRI CoSort for big data sorting, transformation, cleansing, and reporting
- IRI NextForm for data type, file format and database table migration
- IRI FieldShield for structured data discovery and de-ID (masking)
- IRI RowGen for generating safe, realistic flat-file or DB test data
- IRI Voracity for all of the above, plus ETL, CDC, wrangling, etc.
What is Reuse?
One common definition of reuse is building new software from existing software components.
Reuse is like recycling. Materials (components) are reused to create new products.
Usage of Open Source Software (OSS) in the development of other OSS and commercial software is a real world example of reuse. Building software that leverages OSS can result in lower costs and faster delivery of high quality software.
Accomplishing Reuse with SortCL Scripts
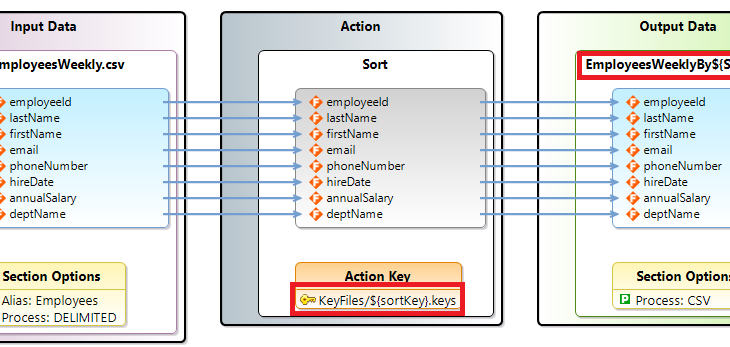
To accomplish reuse, you must look at a requirement and think about how a script can be built to accomplish more than one task. For example, sorting an employee file by multiple attributes (keys) like name, name within a job title, or by some other attributes in the file. In a moment, I will cover how to build a script that provides this type of sort key flexibility, along with other scenarios.
The basic ways to accomplish reuse when developing SortCL scripts are to use environment variables and specification statements (/SPECIFICATION). Environment variables and specification files are resolved at runtime, and can provide a great deal of flexibility for a single script file.
Environment Variables are variable names preceded by a $, and are replaced with the current operating system environment variable value at runtime prior to execution of the job script.
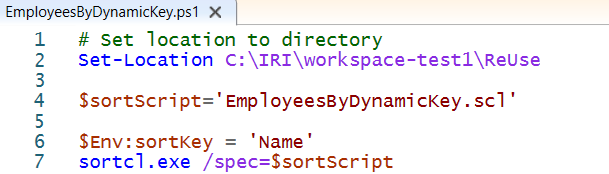
The following depicts a PowerShell script that sets the value of an environment variable named sortKey to the value of Name prior to executing the EmployeesByDynamicKey SortCL job script. As a point of clarification, a $ is used in PowerShell to define variables for use in the PowerShell script. Environment variables are set in PowerShell using $Env:environment variable name=value syntax as shown below for the variable sortKey.
SortCL Specification Statements (/SPECIFICATION) define a named file that contains one or more script statements; and is replaced by the contents of the file prior to execution.
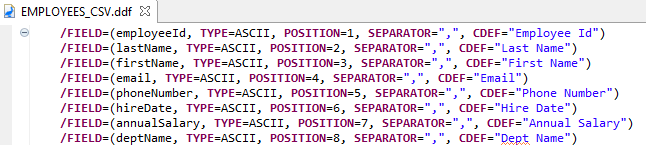
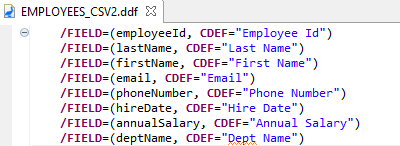
It is a best practice to create Data Definition Files (.ddf) for a set of field definitions and reference them in SortCL scripts. This allows for reuse of the field definitions within and across multiple scripts.
![]()
Advantages of Reusable Scripts
Scripts that are reusable eliminate the need to create a new script for every situation. For example, a single script can be built to sort a file using different key fields or applying different filtering criteria.
Creating a reusable script takes a little extra thought, but can result in reduced development, maintenance and execution costs.
Now that we have covered how reuse can reduce costs and the SortCL syntax that facilitates reuse, I will walk through a series of examples that should provide a good foundation for incorporating reuse into your SortCL job scripts.
Achieving Reuse by Example
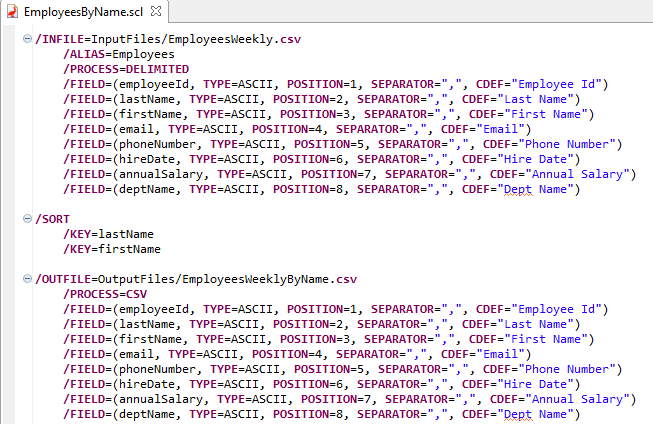
The EmployeesByName script shown below will be used as a basis for the reuse discussions that follow. This script is an example of a non-reusable SortCL job script that sorts a weekly employee file by name (last, first).
Script
Input file sample – Unordered Data
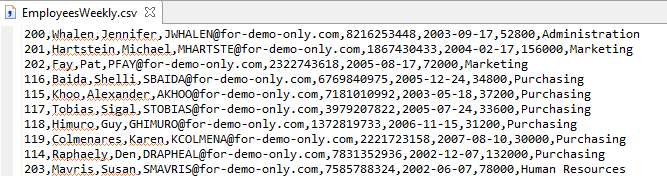
Output File sample – data ordered by last name, first name
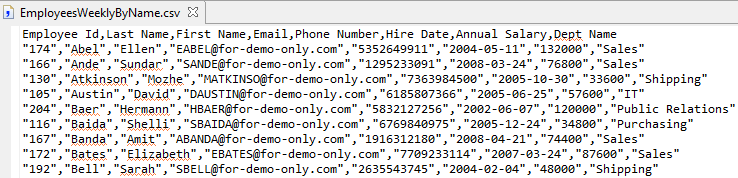
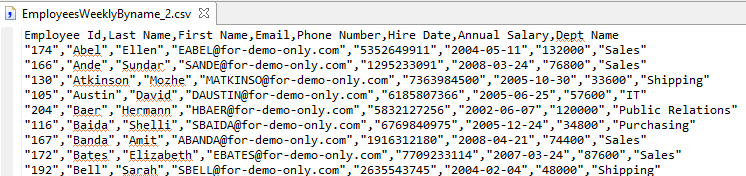
As you can see in the output file above, specifying /PROCESS=CSV resulted in the field names specified by the CDEF attribute to be written to the first record of the output file and all fields surrounded by quotes.
Reuse Example 1 – Field Definitions
As mentioned earlier, it is a best practice to create a Data Definition File (DDF) for a set of field definitions and reference the .ddf file with a /SPECIFICATION statement in the SortCL job script.
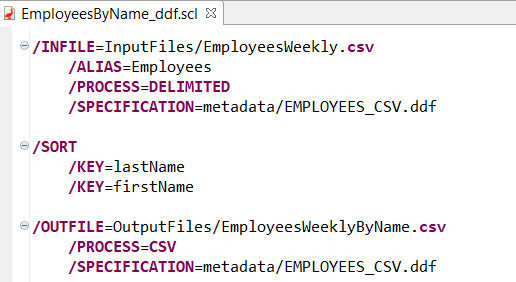
Creating a SortCL job script with a /SPECIFICATION statement referencing a .ddf file instead of the individual /FIELD statements, as shown above, would look like the EmployeesByName_ddf script below. The .ddf file is reusable for the input and output as they both contain the same fields.
Executing the script will create the exact same file that the EmployeeByName script above did.
Reuse Example 2 – Providing Sort Keys at Execution Time
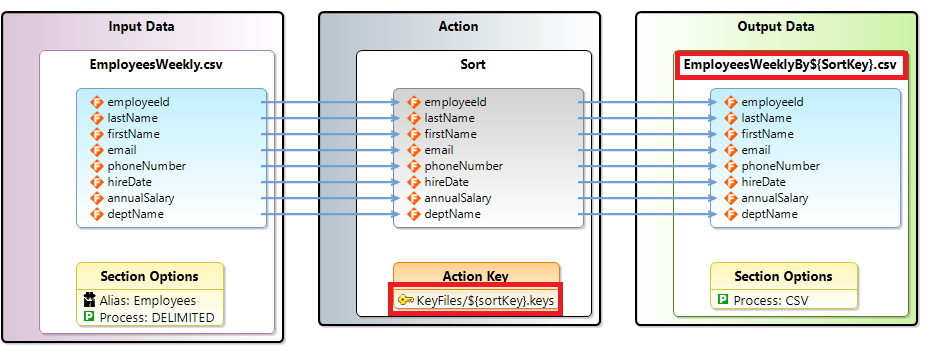
As mentioned earlier, we will now look at creating a script that is reusable for multiple sorting scenarios. Instead of starting from scratch, the EmployeesByName_ddf script can be modified by following these steps.
Step 1
Create files containing /KEY statements for each field you want to sort on and place them in a KeyFiles Directory. For purposes of demonstration, I created five files with a .keys extension, as follows:
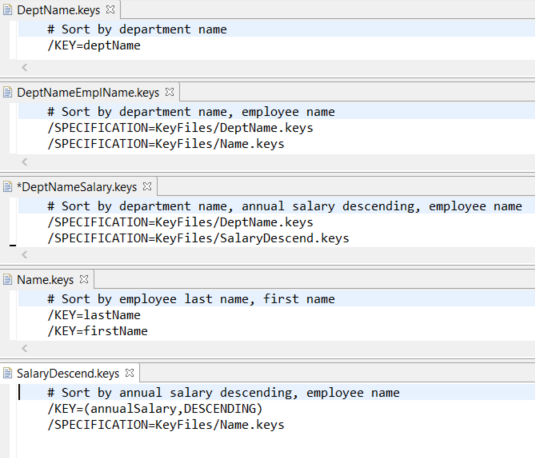
While a requirement to sort the file only by department name is unlikely, I created a file with the department name (DeptName.keys) so it could be reused in the DeptNameSalary and DeptNameEmplName key files by using a /SPECIFICATION statement.
Step 2
Make a copy of the EmployeesByName_ddf.scl file and name it EmployeesByDynamicKey.scl.
Step 3
Change the script /SORT statement by replacing the /KEY statements with a /SPECIFICATION statement as shown here.

A quick test with the IRI Workbench using Run Configuration, setting the value for the sortKey environment variable to Name on the Environment tab, and clicking the Run button validates the changes worked successfully.
As expected the output file is sorted by employee name just like the script above.
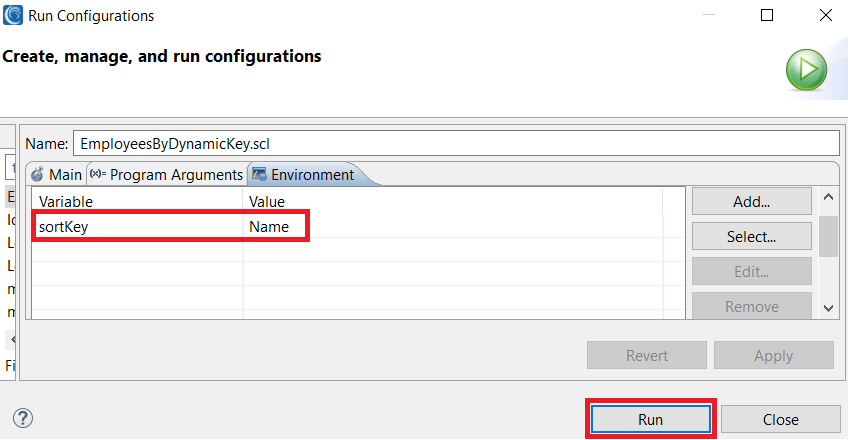
sortKey can now be set to the name of any of the .key files in the SortKeys directory created in step 1. Sorting using any other fields is as easy as creating a new .keys file and specifying it for the value of the sortKey environment value.
Step 4
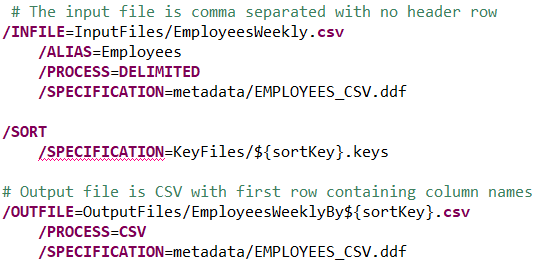
Change the /OUTFILE file name to use the sortKey environment variable. This will result in the output file name reflecting the sort sequence of the file.
![]()
For example, specifying DeptNameEmplName as the value for sortKey will result in the execution of the script creating file EmployeesWeeklyByDeptNameEmplName.csv.
The complete modified script is as follows:
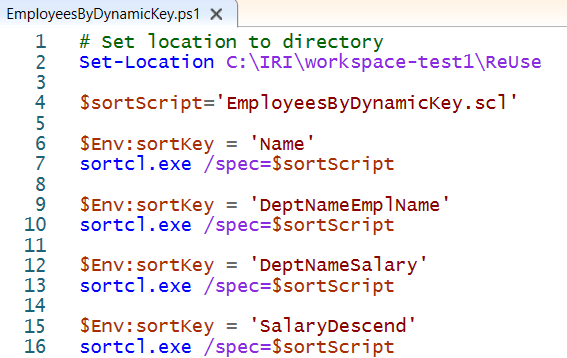
With this single SortCL job script multiple files can be created as shown in the following PowerShell script.
Reuse Example 3 – Field Predicates
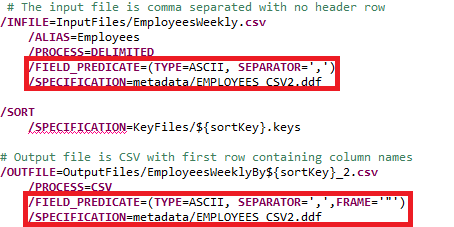
This example demonstrates how to streamline manual creations of the script above and provide additional reuse capabilities by leveraging the /FIELD_PREDICATE statement.
A field predicate allows you to set default attributes like POSITION and SEPARATOR for the /FIELD statements that follow it. Another benefit of removing the position parameter is that it allows you to remove or reorder fields without needing to update position numbers.
Before continuing with the example, note that field predicate statements are incompatible with IRI Workbench operations and third-party tools. Those interfaces seed and/or need verbose field statements for mapping and lineage uses with which predicate interferes.
Converting the prior example to use field predicates can be done in three easy steps as follows:
Step 1
Create a copy of the EMPLOYEES_CSV.ddf used in the earlier examples. Then, streamline the file by removing the TYPE and SEPARATOR parameters from the /FIELD statements.
Step 2
Modify the script from above to use the .ddf file from Step1 and add a predicate statement prior to the specification statement for the input and output files.
Running a quick test validates the output matches the earlier runs.
Step 3
Modify the SEPARATOR parameter of the output file to be an environment variable. This will allow the same SortCL script to be used to produce output files with different separators.
![]()
Testing the modified script specifying a vertical bar (|) and tilde (~) for the environment variable will result in the outputs below.
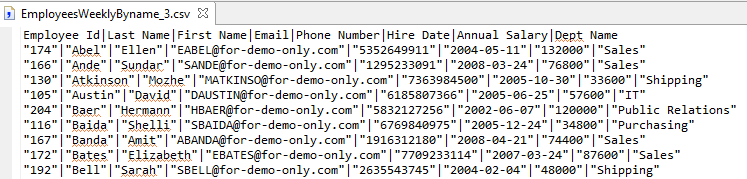
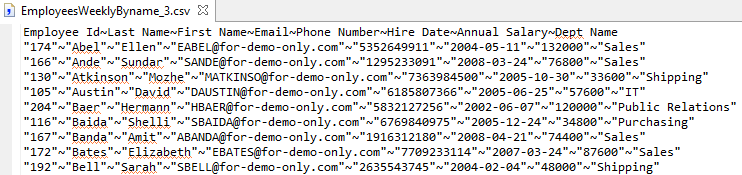
Reuse Example 4 – Extending Capabilities
The examples covered above demonstrate methods for creating SortCL job scripts that are reusable by using environment variables and specification statements within the context of the script. In this example, I cover two basic methods that can be used to add an additional output file to an existing job script.
Producing more than one output in a single job script eliminates the need for multiple scripts. Creating multiple files in a single script results in reduced execution times and computing resource consumption, as the input file and sorting is only executed once.
Method 1 – Modify Existing Script
As shown below, the existing script from Example 2 was modified to add a new output file that contains only the employee Id and name. While the field choices I made were arbitrary, having to create a file without salary is a likely business scenario.
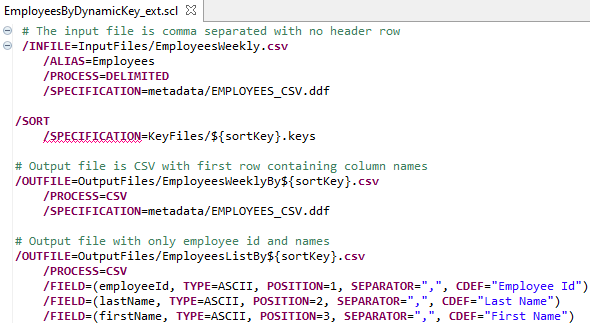
Method 2 – Include Existing Script
Method 1 above always creates the Employee List file. By creating and executing a separate script, like the EmployeesByDynamicKey_incl script shown below, you can control when the Employee List file gets created.
Having a second script gives the flexibility of meeting an ad-hoc business need. For example, the Salary Administration department could run the EmployeesByDynamicKey job script whenever they need to, and the EmployeesByDynamicKey_incl below can be a regularly scheduled weekly job.
As further explanation, using the specification statement in the script below allows the EmployeesByDynamicKey script to be reused.
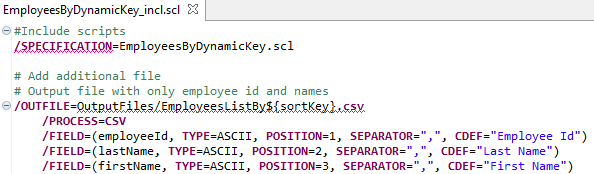
Summary
In this post, we discussed ways to potentially reduce costs through the creation and execution of reusable scripts, mainly through SortCL’s support for environment variables and specification statements that are replaced prior to execution.
These examples showed just a subset of things that can be accomplished by building reusable SortCL script files. The next time you create a new IRI job script, think about how you might make it more flexible, so that it can be reused in the future for a different scenario.
Additional reuse ideas could involve specifying:
- an encryption key value or file name
- conditions for /INCLUDE and /OMIT statements
- the name of a file containing keys to be used in a join to select records
- the encryption (or other PII masking) routine name to be used
- a file containing the SQL for a /QUERY statement
- the WHERE condition for a SQL statement specified by a /QUERY statement
- a value for a mathematical expression
Reusability Final Thoughts
Looking beyond the technical methods of reuse discussed above, an organization can realize significant value by:
- Standardizing on a single enterprise field name to represent a unique business term across the enterprise, instead of using application specific names. A single field name will reduce confusion when collaborating with others across the organization.
In Example 2, I created a file that contained /KEY statements to sort the employee data by lastName and firstName. Standardizing these names across the enterprise allows any data to be sorted by name irrespective of the type of person the name represents (e.g. employees, applicants, student, patients, customers)
- Using single field names for SortCL job scripts; and reporting and analytic tools.
- Documenting field metadata to include items like definition, data type and valid values.
- Providing an easy to use metadata search facility.
- Leveraging data virtualization or data catalog tools to provide an enterprise view of data that is independent of which application manages the data or how it is stored.










