The Data Vault Test Data Generator Wizard
As of CoSort Version 10.5, the IRI Workbench IDE includes a Data Vault Generator wizard to help IRI Voracity platform users migrate a relational database model to a Data Vault 2.0 (DV) architecture. The wizard has three output options depending on the needs of the user.
All options create the Entity Relationship Diagram (ERD) for the outputs. The first option only generates the full DDL and ERD. The second option will create a DDL for tables that do not exist and also create job scripts to load the data in the source tables into the new target tables. The third option will create a DDL for tables that do not exist and load the new tables with randomly generated test data. This article covers option three.
According to Dan Lindstedt, the inventor of Data Vault, “The Data Vault is a detail oriented, historical tracking and uniquely linked set of normalized tables that support one or more functional areas of business.
Data Vault is a hybrid approach encompassing the best of breed between 3rd normal form (3NF) and star schema … [it] is a data integration architecture; a series of standards, and definitional elements or methods [for how] information is connected within an RDBMS data store in order to make sense of it.”
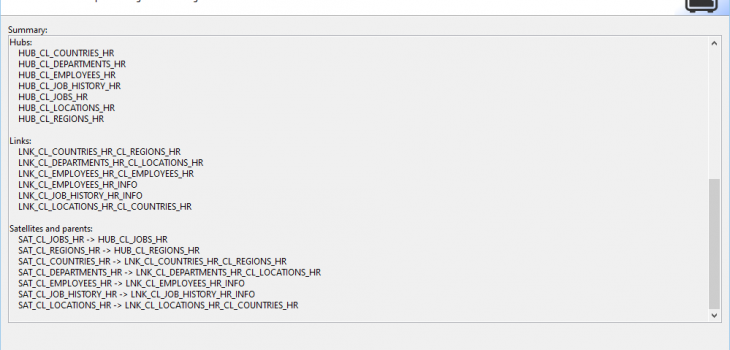
There are three types of tables in the DV2 standard. A Hub contains the unique business keys. A Link defines the relationships between the business keys. A Satellite contains the context (attributes) of the table. A satellite can be a child of either a hub or link table.
In each of these tables, a hash of the key’s raw data is used as the primary key of the new table. Each table also includes the source of the original data and a load timestamp for historical tracking. A Satellite also contains an end timestamp and an optional hash difference for tracking changes to the records.
The Voracity Data Vault Generator wizard uses the existing primary (PK) and foreign (FK) keys as a starting point for organizing the new tables. The defaults per table are as follows:
- A hub for each PK key (including compound keys).
- A link for each self-referencing FK.
- A link for each group of FKs (minus the self-referencing keys).
- A satellite on the hub if the table contains zero FKs.
- A satellite on the link if at least one FK exists.
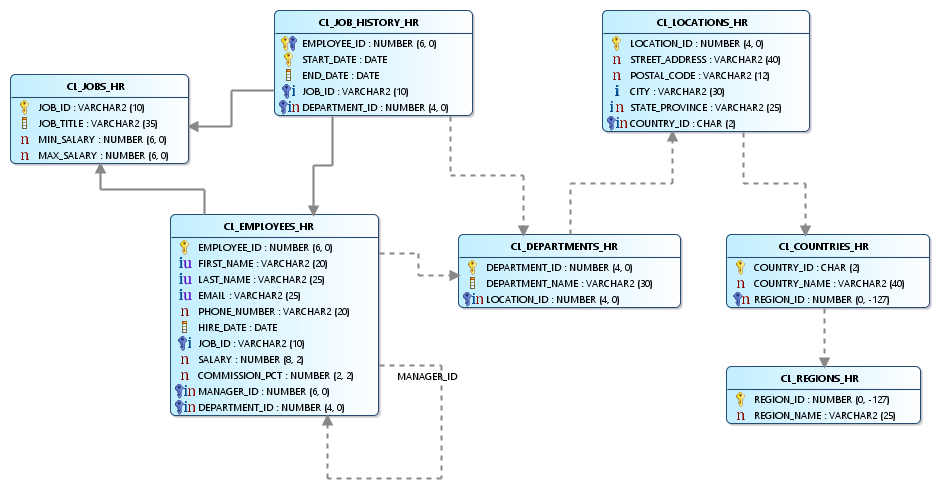
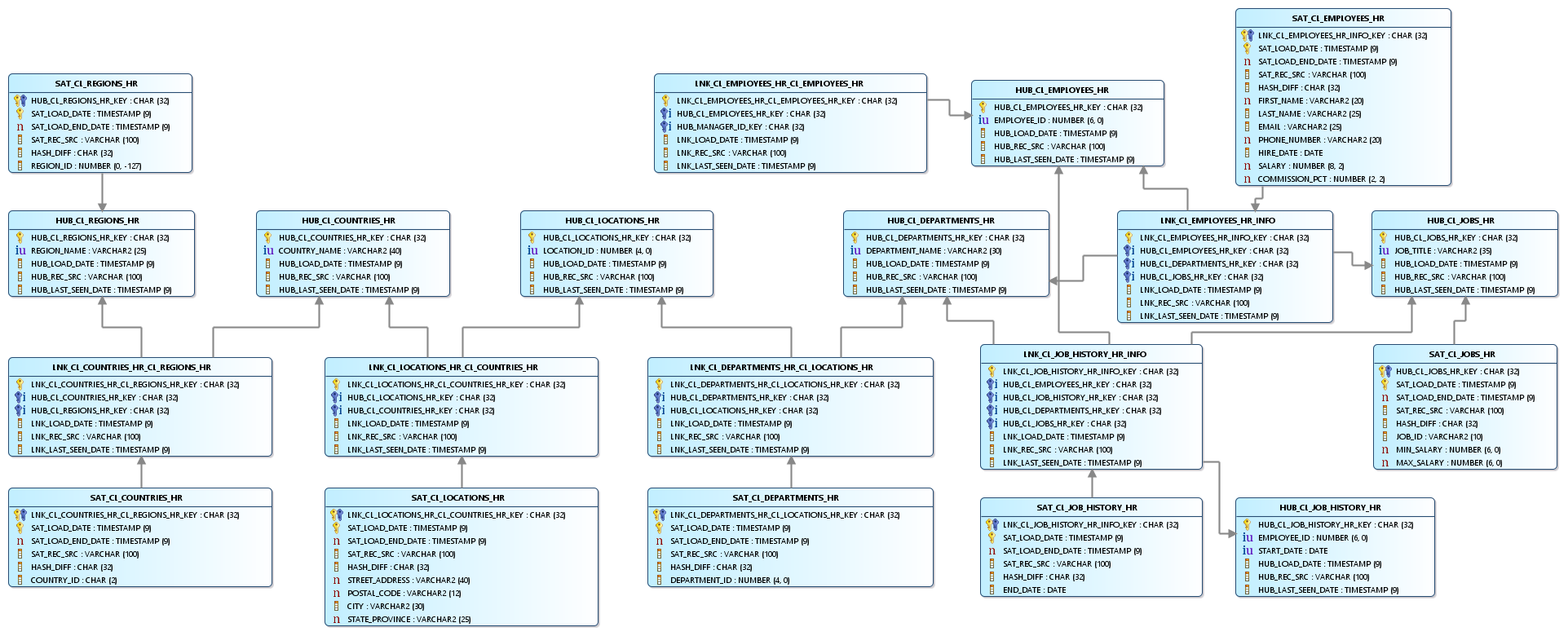
In this example, seven related tables will be used representing human resource data. Below is the ERD for the source tables.
The random data can be truly random based on the data type or can be controlled by the use of rules. If a rule is not assigned to a field, random data is generated. A rule can be used to populate a field from a set file, from data in another table, from data in another field, a sequencer, or an expression.
Setup
The wizard starts with the setup page where the details of the job are defined. There are two hashing type options: MD5 and SHA-256. As stated earlier, the output for this example is Load randomly generated data.
Snowflake is selected as the loader. Leaving the loader blank will create delimited file outputs.
The number of rows to be generated can also be specified.
Check the Include last seen date to include this type of column in the hubs and links. This is needed if the source system does not provide auditing or CDC.
Check the Include hash diff to include this type of column in the satellites. The hash difference column records a hash of the data. This is recorded so that when any changes are made to the data and a new record is loaded, there is a way to determine that the new record is indeed different.
Check the Show summary page to display the details of the job at the end of the wizard. Because the wizard examines the table dependencies, the display of this page may take a while to load if there are a large number of related tables.
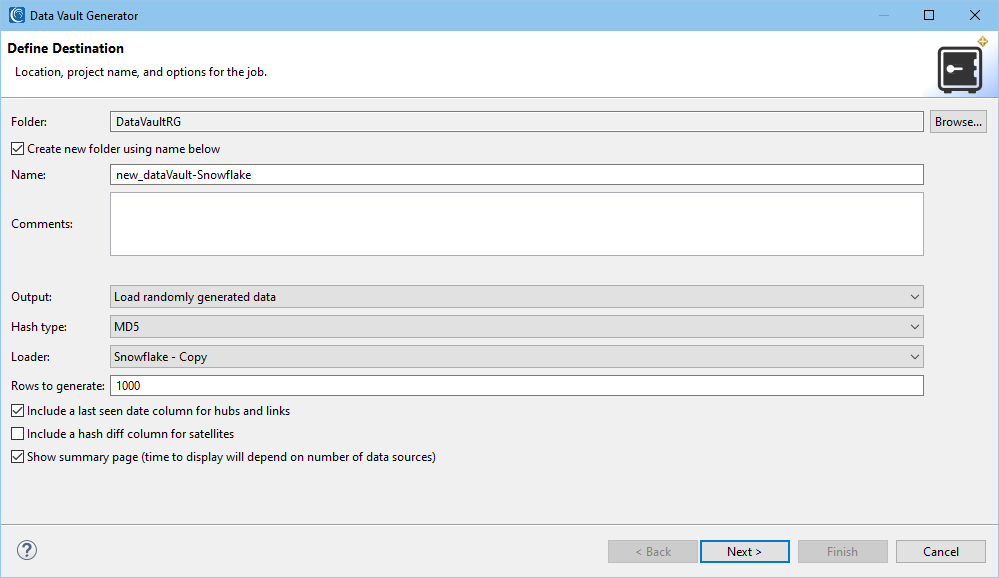
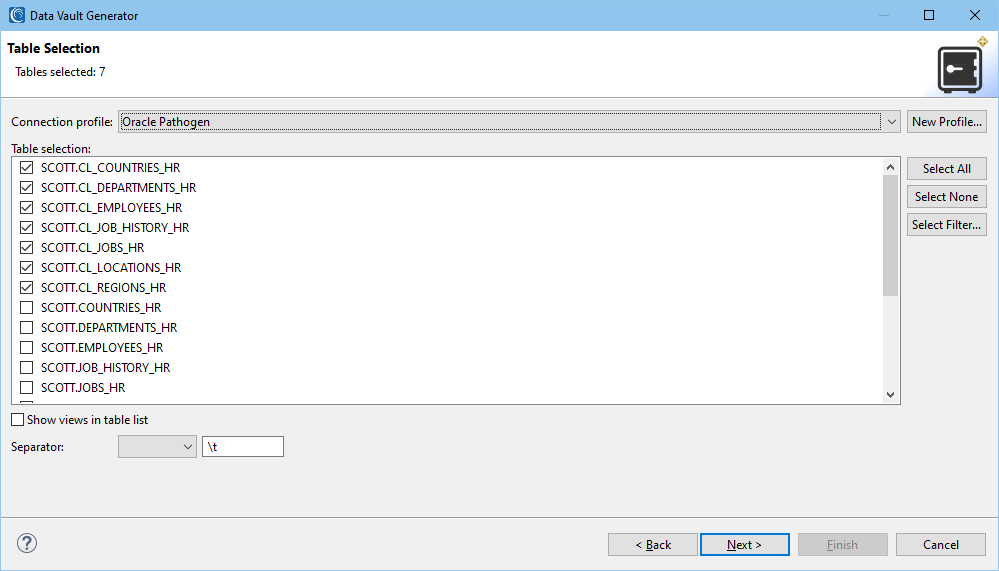
Table Selection
This page is where the source tables are selected. In this example, the seven source tables are in an Oracle database.
Hub Options
The hub options page opens with a list of the existing primary keys, the proposed new table name and the business key columns populated by the existing primary key. The table name and columns can be edited. This is helpful when the business key is not the primary key.
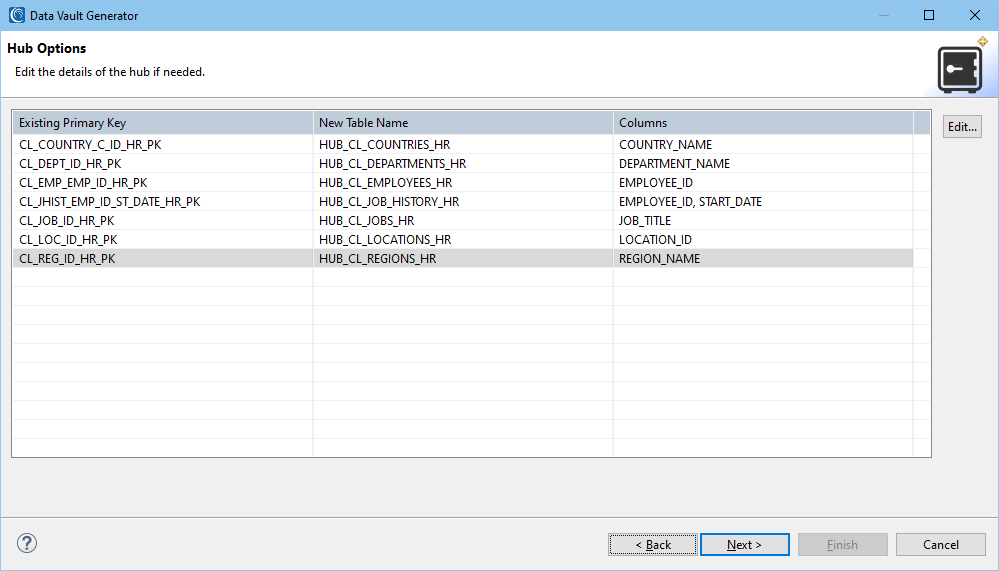
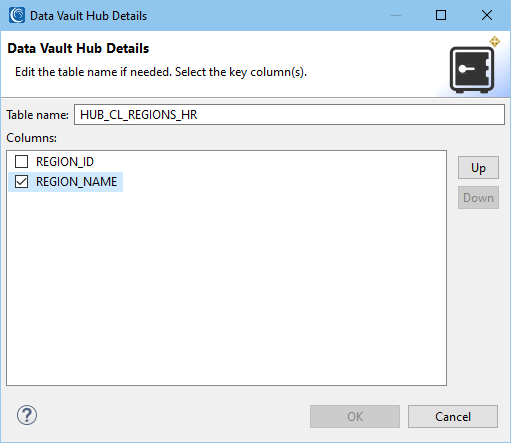
For instance, the REGION_NAME is a more descriptive business key than REGION_ID which is what the PK uses. Additionally, the order of the columns can be modified. This is important during the hashing phase.
Link Options
This page is populated from the existing foreign keys; however, it is updated with the business keys selected on the previous page. Each entry can be edited.
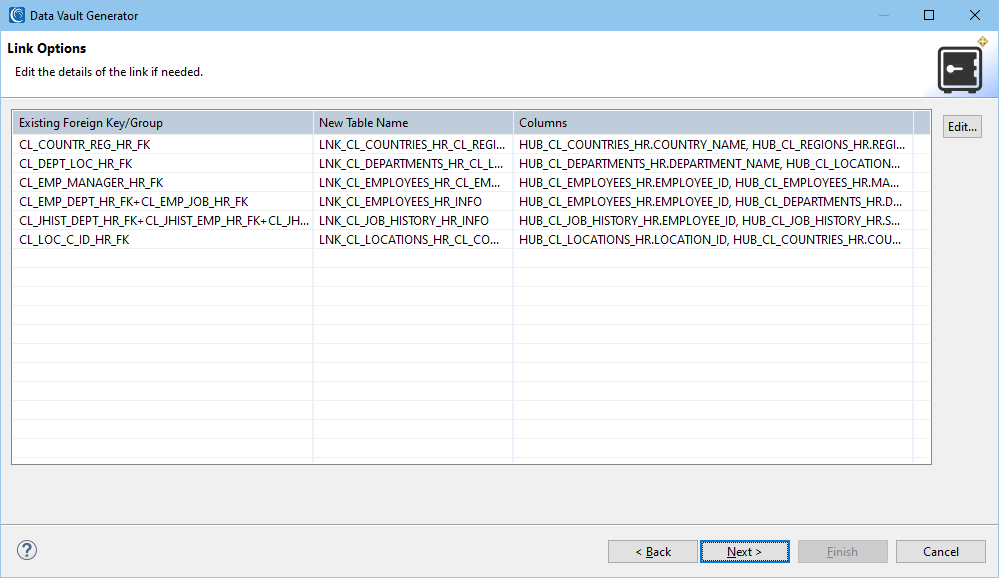
In the case of a self-referencing key, the type of link can be selected. While the structure remains the same, the table name changes depending on the type.
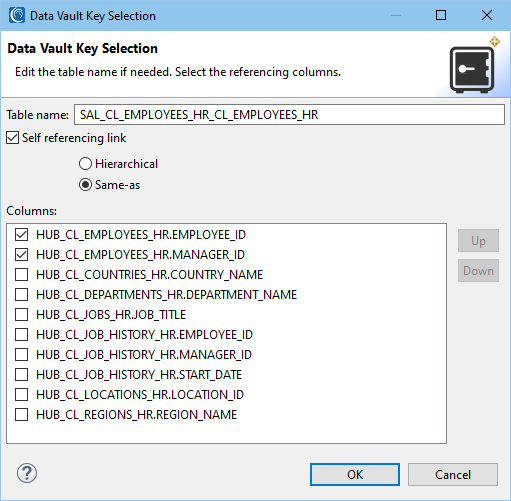
Satellite Options
As stated previously, the satellites connect to either a hub or link. This page loads with the Data Vault standard that states the satellite is attached to a hub if there are no foreign keys, and is attached to a link if there is at least one foreign key.
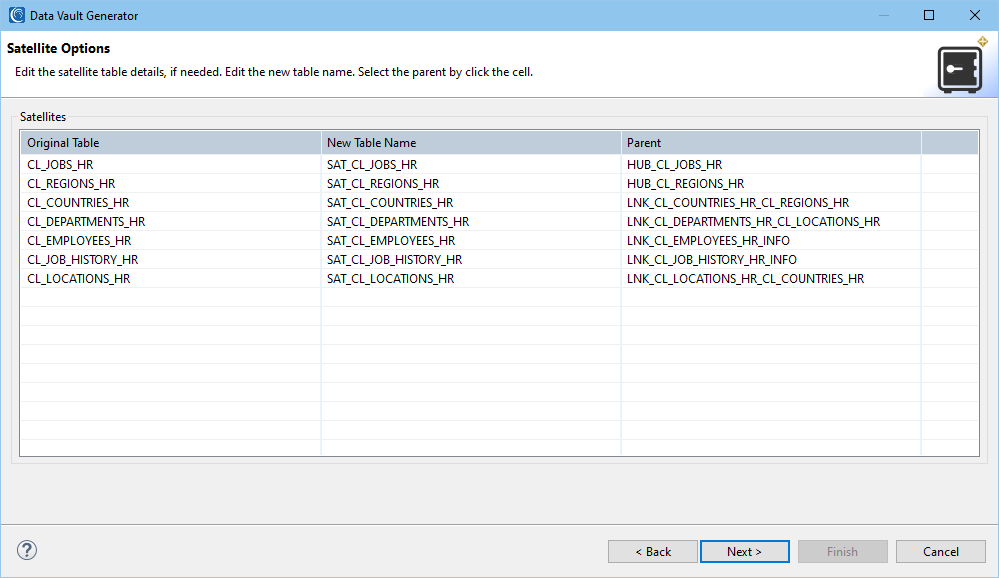
Loading
On this page, the details for the load are selected. This page is not shown if there is no loader selected on the setup page. It is possible to choose the same or a different location for the target tables.
If the tables already exist in a different target, the output mode can be either Create for truncate first or Append. In this example, the tables do not exist. There is also an option to create a drop script which is helpful during testing.
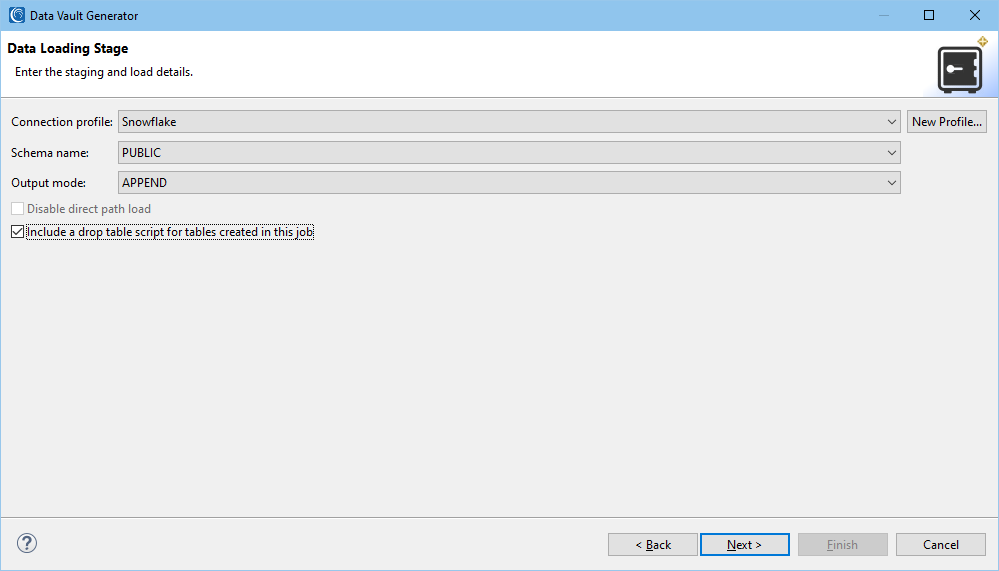
Rules
This page is where test data generation rules can be added. The rules can be retrieved from the rule library by clicking Browse or added on-the-fly by clicking Create.
Additionally, rules already defined and associated with data classes can be used by checking the box at the bottom of the page. In this example, 23 rules have been previously created, and will be applied automatically to 25 fields in the source tables via data classes.
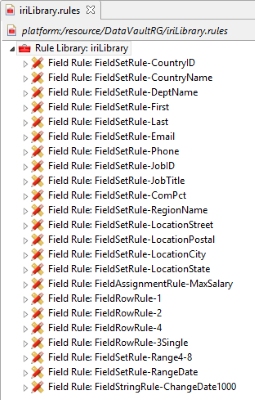
Job Summary
If activated, the summary page lists the details for the job:
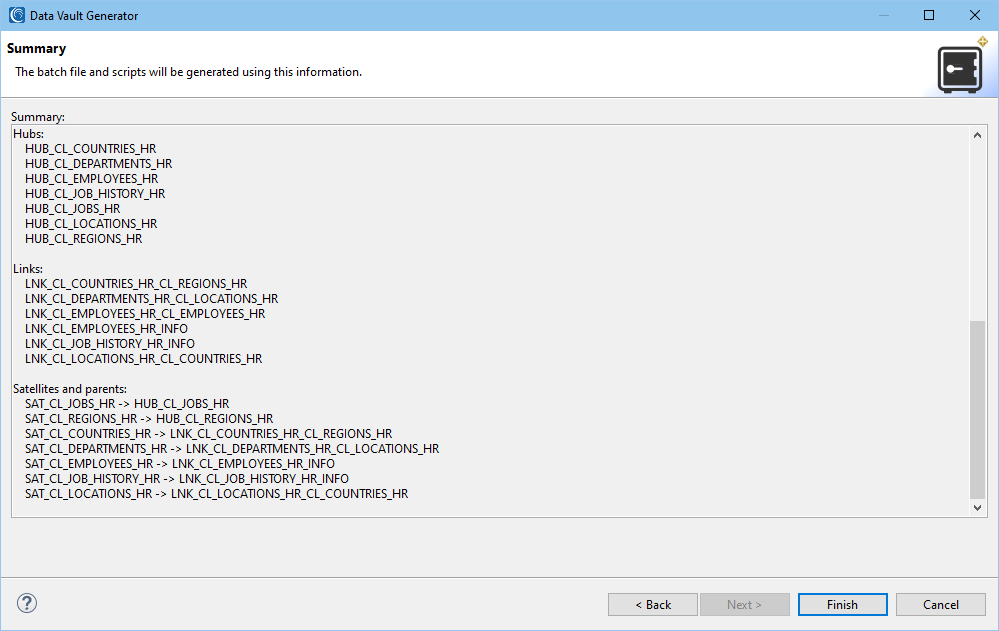
Output
When the wizard finishes, it produces multiple files to run the job and opens the ERD. What was 7 source tables, turns into 20 target tables – 7 hubs, 6 links, and 7 satellites.
The flow diagram shown below represents all the pieces that comprise the test data generation and population job. They include: an SQL file to create the new tables, a script to record the timestamp of the job, 8 IRI RowGen task scripts to create unique values for source fields defined as unique, 7 scripts to generate and reformat the data, and 20 loader files.
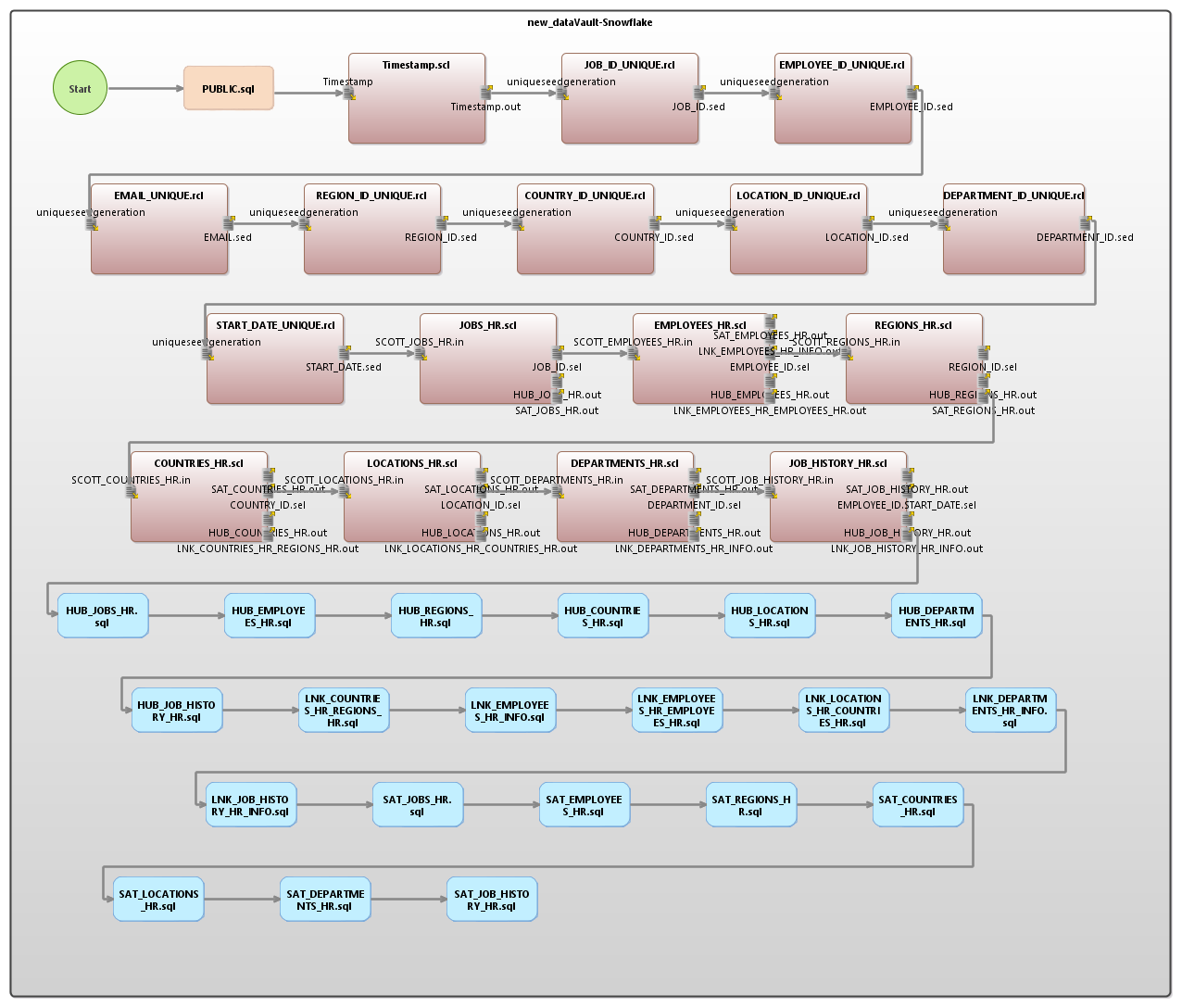
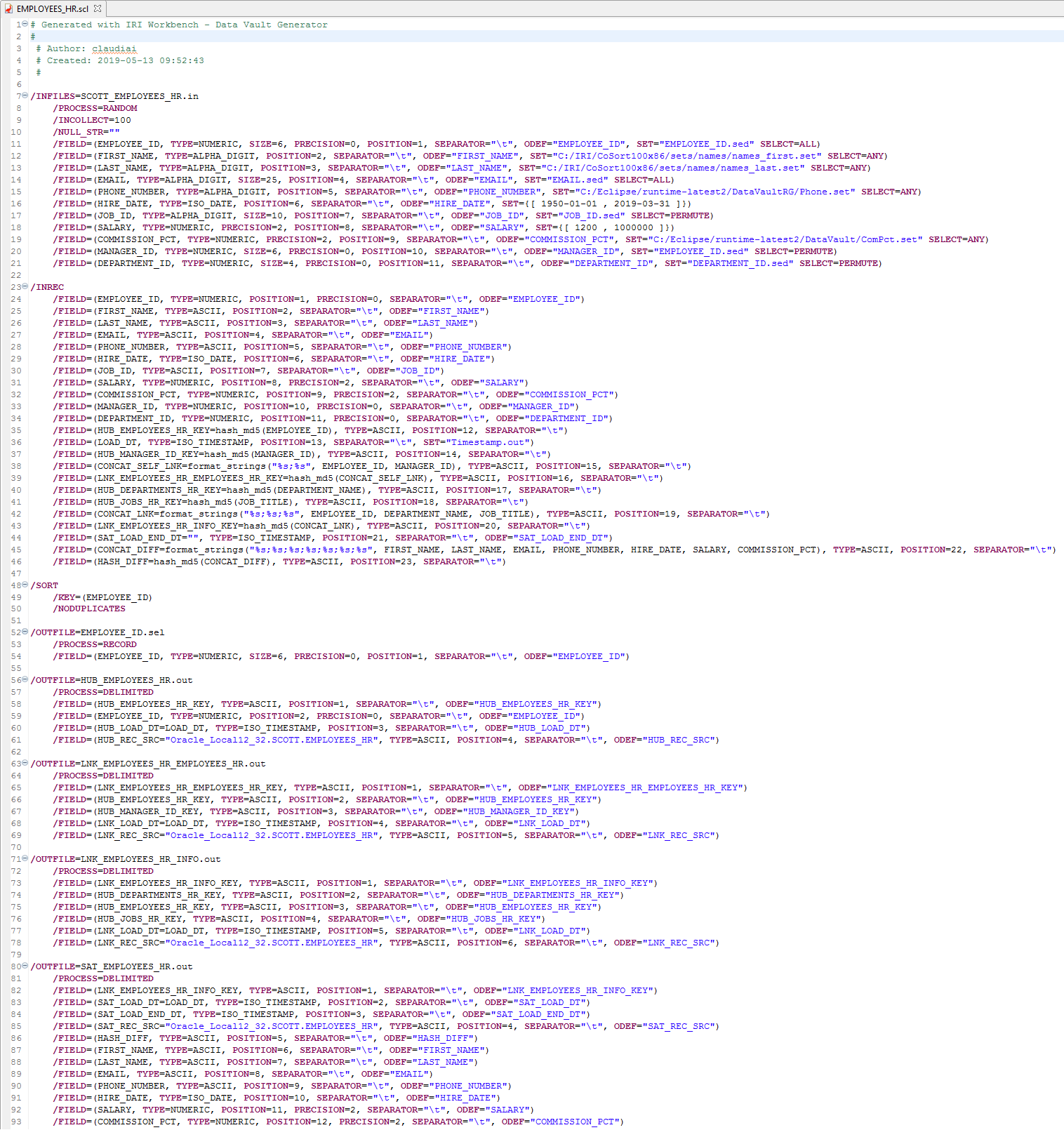
The EMPLOYEES_HR script below reveals the generation (“input”) phase of the job, where various set (lookup) files are used to populate the data needed for the rest of the script. In the Inrec section, the concatenations and hashes needed for DV are created.
Because these calculations are performed by the CoSort-powered SortCL engine for RowGen and not in the database, there is no need for a separate staging step. However, this step can be added if desired.
This job sorts the data on the business key of the table while discarding duplicates. In the output sections, flat files for the loader are created for the new tables using the appropriate fields for each of those tables.
Conclusion
The Data Vault Generator in IRI Workbench makes the process of prototyping a new Data Vault project more automated. By using rules, randomly generated, but realistic and referentially correct test data can be refined.
After loading the table defaults, edits can be made to choose the business keys and their order. Furthermore, the job creates the new resources, creates the timestamp, concatenates and hashes the key fields, and loads the new resources.
For more information, please contact voracity@iri.com.