
The Use of Data Lakes
Has your organization considered using a data lake? This article explains what a data lake is, and how you can fish its murky depths for value in an architecture optimized for your needs. Read More
Has your organization considered using a data lake? This article explains what a data lake is, and how you can fish its murky depths for value in an architecture optimized for your needs. Read More

Update Q3’2019: Subsequent to the development of the IRI Voracity Add-On for Splunk described below, there is now also a Splunkbase-registered IRI Voracity App for Splunk available for Seamless Data Preparation, Indexing, and Visualization…
After our first examples of external unstructured data preparation and PII data masking for Splunk generated interest in these capabilities, IRI wanted to develop a direct integration from the Splunk user interface (UI). Read More
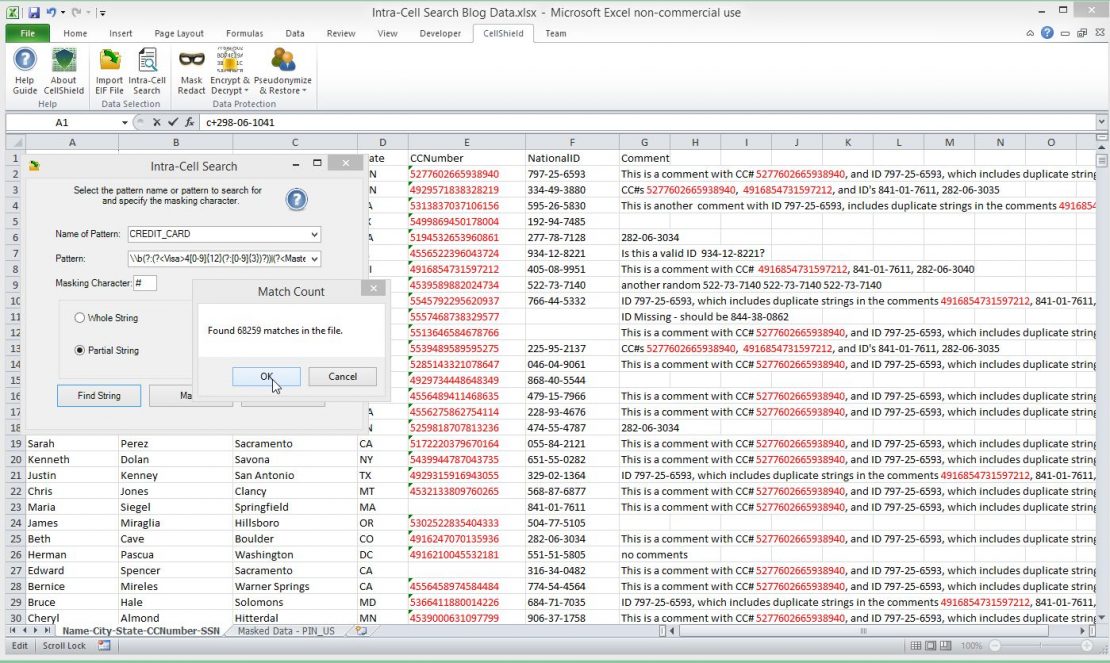
IRI CellShield™ Enterprise Edition now offers an Intra-Cell Search feature that finds and protects sensitive data in unstructured cell contents with masking, encryption, or pseudonymization. Just as with full-cell values, you can now identify and mask the ‘floating’ sensitive data in Microsoft Excel® spreadsheets with only a few mouse clicks. Read More
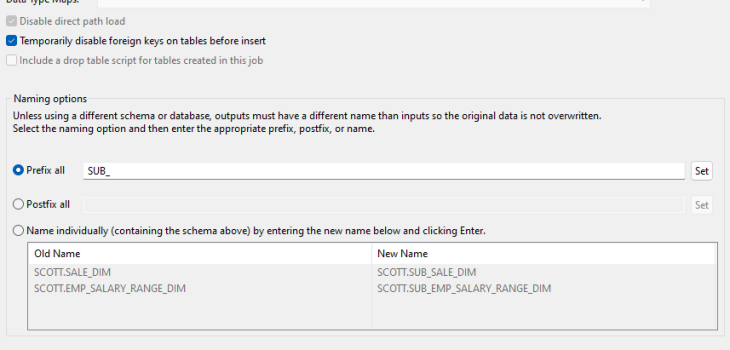
Once a database exceeds a certain size, it becomes expensive — and risky from a security perspective — to provide full-size copies for development, testing, and training. Read More

A dimension is a structure that categorizes a collection of information so that meaningful answers to questions regarding that information may be obtained. Dimensions in data management and data warehouses contain relatively static data; however, this dimensional data can change slowly over time and at unpredictable intervals. Read More

IRI provides a software development kit (SDK) to help FieldShield users apply column-level encryption, decryption, hashing, and redaction algorithms in Java and .NET projects for more in-situ or dynamic data masking requirements. Read More
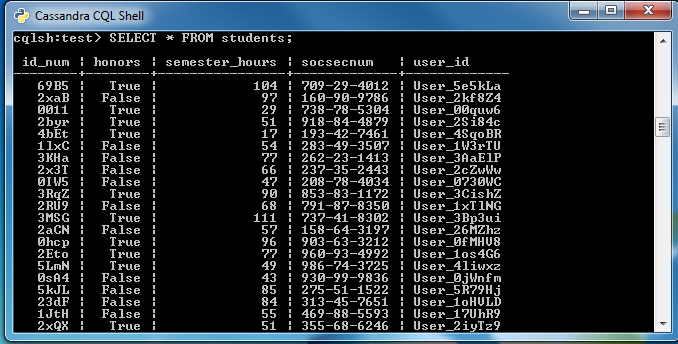
UPDATE: Q2’17: Included JDBC and ODBC drivers, and pending native JSON handling can make the connections faster and more seamless than the approach shown below. You can also use the Hadoop edition of IRI Voracity to mask data in HDFS directly. Read More
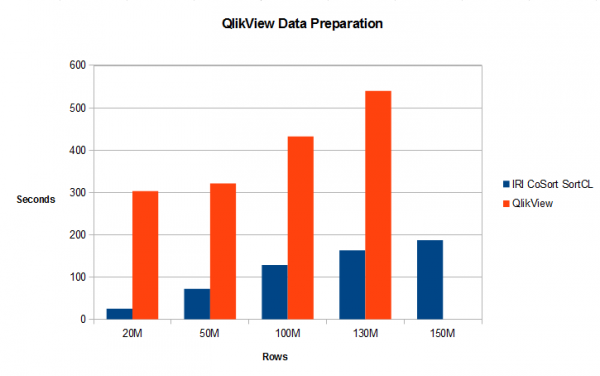
Introduction: As with multiple BI platforms discussed throughout this section of the IRI blog site, this article analyzes the relative data preparation performance (and benefit) of using its external data wrangling engine – via the IRI CoSort product or Voracity platform — with QlikView when ‘big data’ sources are involved. Read More

In the course of legacy platform and/or application migration, COBOL users often need to convert their binary and index files into a human-readable, ASCII-numeric target. One of these older formats is the ACUCOBOL Vision1 file, which we discussed previously in this article. Read More

Introduction: As with multiple BI platforms discussed throughout this section of the IRI blog site, this article analyzes the relative data preparation performance (and benefit) of IRI CoSort with Tibco Spotfire when ‘big data’ sources are involved. Read More