What Is Database Subsetting? How to Subset a Database.
Once a database exceeds a certain size, it becomes expensive — and risky from a security perspective — to provide full-size copies for development, testing, and training. Most teams need smaller copies of the larger database, and often have the PII within masked.
Database subsetting is that process of creating a smaller, referentially-correct copy of a larger database schema from real table extracts. Subsets can be used with, or in lieu of, masking or synthesizing test data to reduce the costs and risks associated with full sets.
The process of creating meaningful subsets manually is complex and laborious. Normally you would have to populate smaller databases with random samples from each production table, and make sure that any relational structure between the tables was still correct in the subset.
This article shows you how to subset a database in the fit-for-purpose, end-to-end database subsetting tool in the IRI Workbench GUI, which simplifies and accelerates this process. The DB subsetting job wizard is available to licensed users of the IRI Voracity data management platform, IRI RowGen for test data generation, or IRI FieldShield for data masking.
By using the wizard, you can create secure database subsets for testing that are structurally and referentially correct. This is because the wizard preserves primary and foreign key relationships, and allows you to simultaneously obfuscate PII with data masking functions like format-preserving encryption.
The wizard for subset creation has the user select the source of the subset, the size, content, and sorting thereof, plus any masking or other functions that should apply to the target parent and child table data. After those options are specified, the wizard builds a series of job scripts (and optional workflow and transform mapping diagrams) which when run will generate and populate either subset tables or flat files.
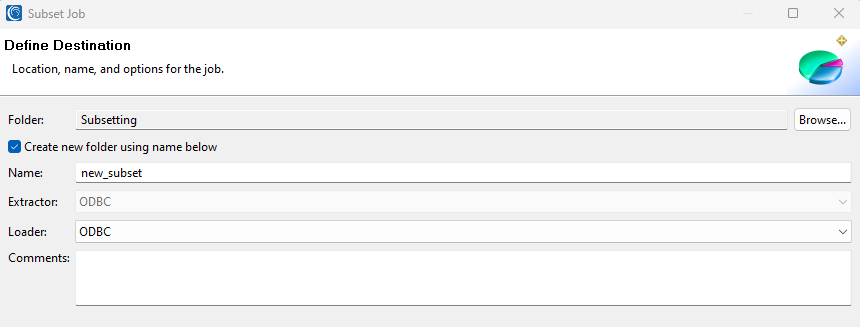
Job Options
This page defines the output type. If the loader is left empty, a flat file with a tab delimiter will be created. For database options, either ODBC or the specific database loader can be selected.
Subset Options
This page is where you specify the details of the subset. Select the connection profile and the table that will “drive” the created subset. Think of the driving table as the main table from where you want the subset to originate.
For example, if you want to subset a table of sales and all tables connected to it, you would select the table with sales info here. Also, select the size of the subset. For example, to get a subset of the 100 highest quantities sold, you would sort on the quantity sold field (as in this example) and enter 100 in the number of rows. A filter can also be added on the driver table.
A qualitative filter can also be added on the driver table to customize the subset based on business criteria. Such as the example below, allowing the filter to omit or include a condition type, that is either manually created to fit all needs, or can use an existing condition.

Sorting
This page is where you specify the sort order of the subset. If you want the rows selected randomly, however, leave the Key Fields list blank.
The Sort page has 3 notable sections:
- The Input Fields list
- The Key Fields list
- Key Options
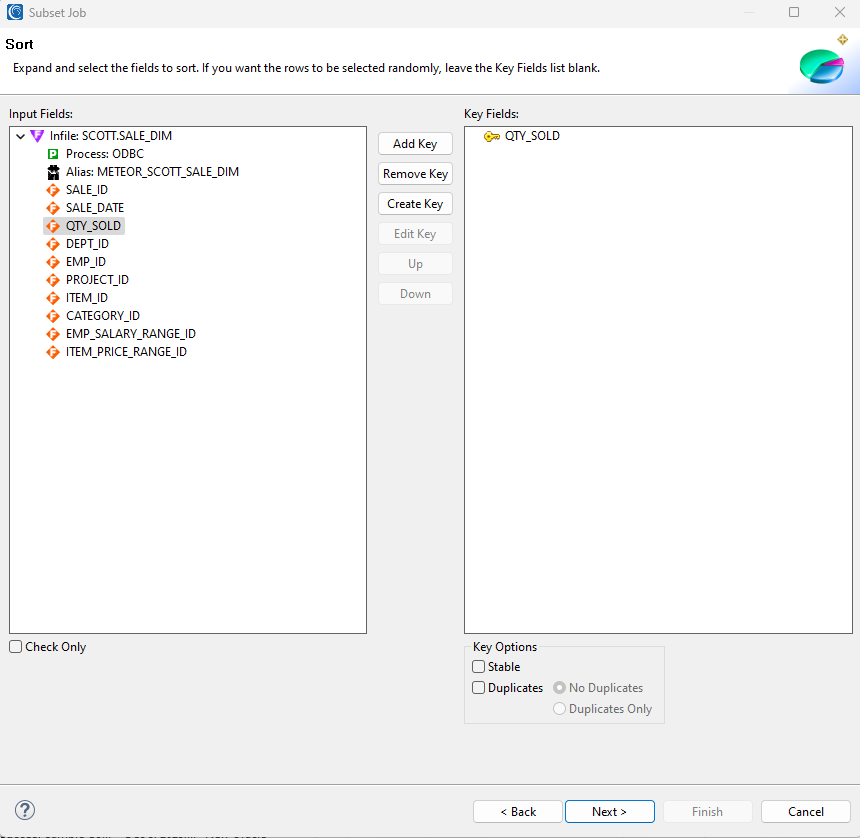
Steps:
- If you want a subset of sorted data, select the column to sort on and click “Add Key.”
- A few options are available in the Key Options box:
- Select the Stable check box to duplicate records to load in the order they are in the production table.
- If you want no duplicates or only duplicates in your subset, select the Duplicates check box and the appropriate radio button.
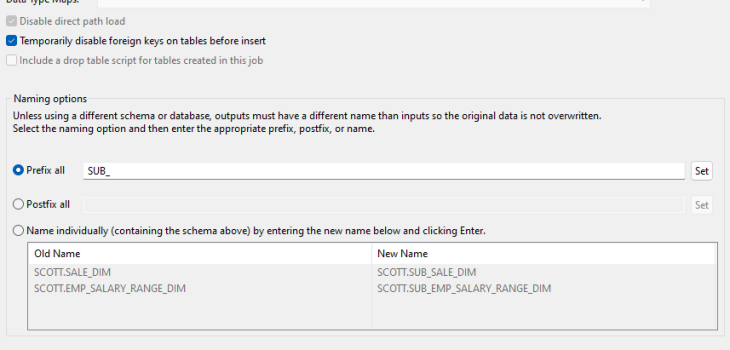
Target Naming
This page is displayed if the output type is a database. It has two functions. The first allows you to view the relations of your driver table. The second is to name the output targets for the subset.
The Target Naming page has 5 notable sections:
- The target profile and schema
- The output mode is always create as this job will truncate any existing tables of the same name
- SQL options for the job
- The naming options
- The references list
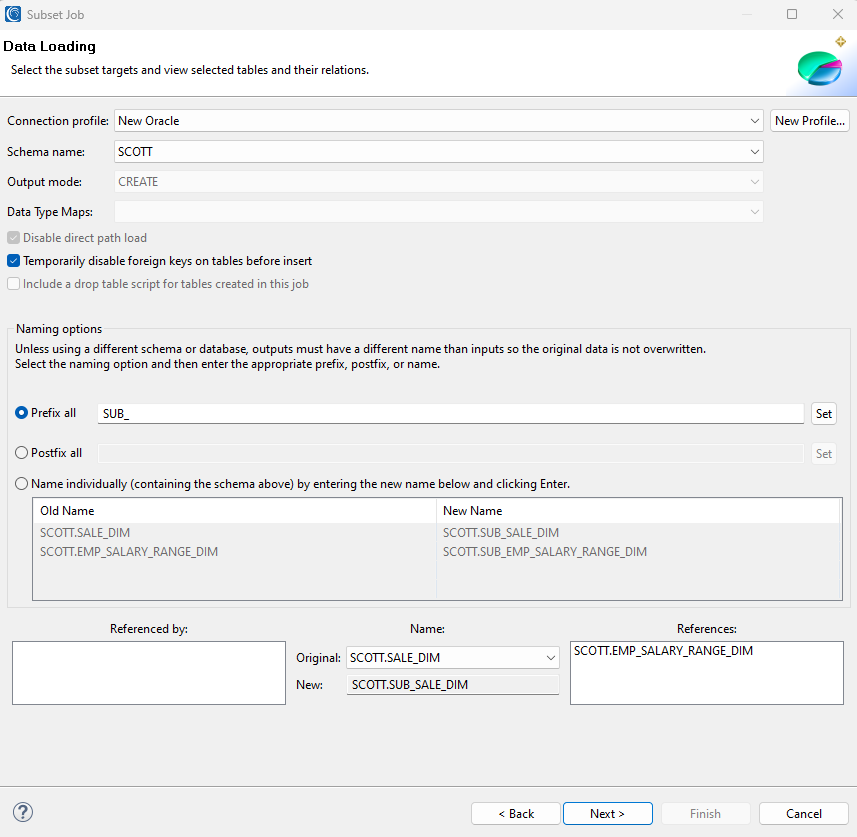
Steps:
- Select the connection profile.
- Select the schema.
- Specify the SQL options.
- Select the naming option to name the subset targets. If a different profile or schema are used, this step is optional:
- Prefix all adds a prefix to every table name and sets it as that table’s target.
- Postfix all adds a postfix to every table name and sets it as that table’s target.
- Name individually allows each subset target to be named independently of the other targets.
- Review the Referenced by and References lists to verify that the table’s relations have been found correctly:
- In the Imported by list, all of the tables that your chosen table is imported by are listed.
- In the Imports list, all of the tables that your chosen table has a relationship with are listed.
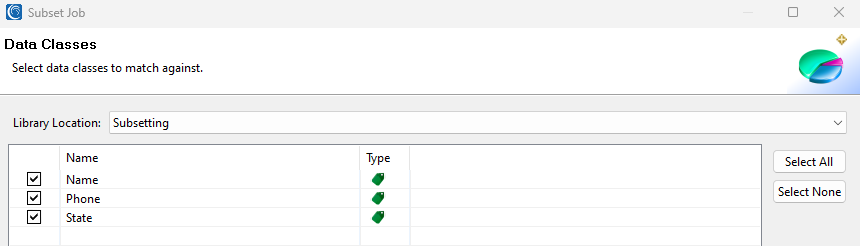
Data Classes & (Masking) Rules
On this page, previously created data classes can be selected and used. Data Masking functions are typically linked to these data classes as data privacy rules, and you can apply those same rules IRI FieldShield, DarkShield, or subsetting jobs.
Data masking in database subsetting also supports referential integrity enterprise wide when you apply deterministic masking functions as rules. So be mindful, and see article on data masking tool functions, regarding the ciphertext results you want to apply.
For a more in depth look at creating a data class and masking-rule pairing, see this article. And to see how all this works in practice, watch the video linked below.
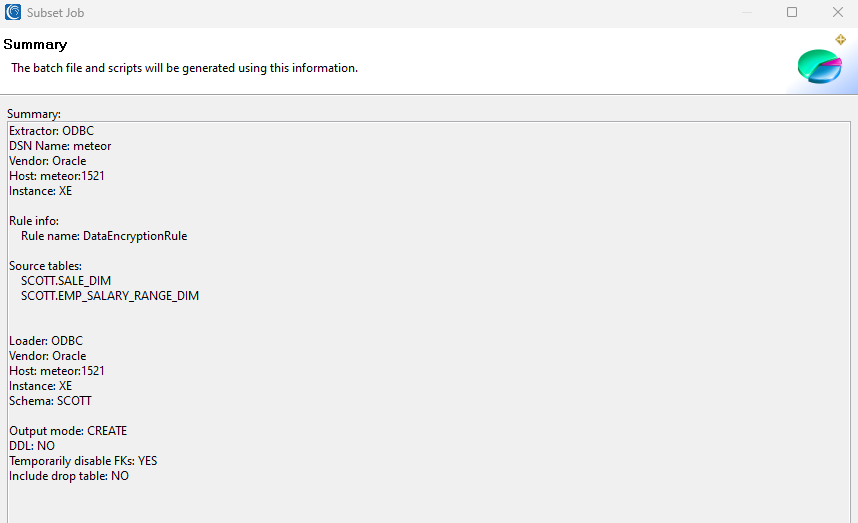
Summary
This page summarizes the DB subsetting job configuration. It clearly displays the columns that matched a rule, and the target tables matching the source tables if they do not exist.
The DDL will also be created for the target tables. You should use that DLL to create tables in Workbench prior to executing your subsetting workflow (batch script) if they do not exist.
Once all of the subsetting wizard pages have been completed, click Finish. The wizard will then create job scripts and an executable batch file for Windows or Unix that you can launch from Workbench or the command line to extract subsets from the driver table and its related tables.
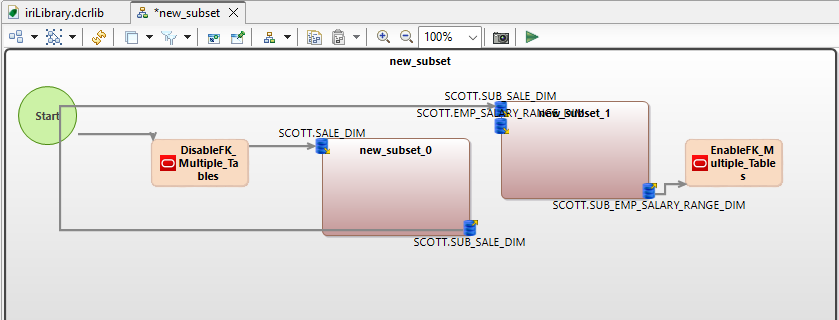
Here is a flow diagram showing the tasks created for this simple job in Voracity:
Follow along with our YouTube video!
Contact info@iri.com if you have any questions.










