
Indexing Splunk with Voracity Add-On
Update Q3’2019: Subsequent to the development of the IRI Voracity Add-On for Splunk described below, there is now also a Splunkbase-registered IRI Voracity App for Splunk available for Seamless Data Preparation, Indexing, and Visualization…
After our first examples of external unstructured data preparation and PII data masking for Splunk generated interest in these capabilities, IRI wanted to develop a direct integration from the Splunk user interface (UI). This article covers a new IRI Voracity add-on for Splunk that indexes data from different Voracity workflows. It also works for constituent CoSort SortCL job script executions, such as IRI NextForm for providing replicated data, or IRI RowGen for providing test data, directly in Splunk.
Recall that Splunk is a great indexing and visualization platform, but it lacks the power to process many forms of data or to de-identify it with certain methods important to CISOs. By embedding the power of Voracity into Splunk’s intuitive UI, you can directly inject data into Splunk that’s been pre-processed and protected in IRI job scripts or workflows.
Installing the IRI Voracity Add-on for Splunk
-
- Download this archive, which contains python scripts, Splunk files, and sample IRI job scripts.
- Copy the iri_cosort folder from the extracted archived into your splunk etc/apps/ folder.
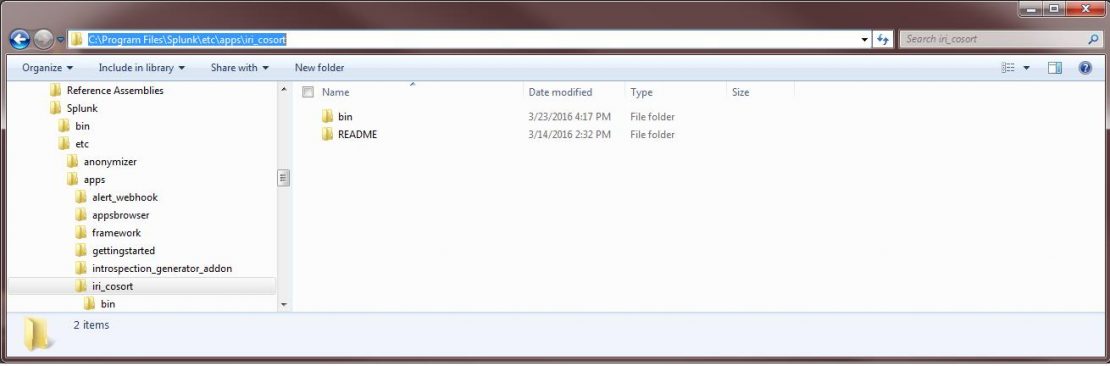
To verify the installation of the add-on in Splunk, click Settings > Data Inputs. Browse to IRI and see that parameter entry screen. That’s it. Your IRI data input module is now ready for use, and you can start indexing data prepared in IRI Voracity (CoSort SortCL job) scripts directly into Splunk.
Working Example
You can use any IRI job script with your new Splunk Input Module, but for this example, we want to demonstrate how easy it is to encrypt a set of data and then index it into Splunk.
For this example, we just used a basic CSV file consisting of 6 fields: Name, Surname, City, State, CCnumber, ID, stored in the file Name-City-State-CCNumber-SSN-Random-short.csv. Note, however, that the data source could have been any one or a number of IRI-supported data sources. Because of the personally identifiable information (PII) in this file, it would be extremely unsafe to expose it on a platform such as Splunk. See this first article on the use of IRI FieldShield in preparing flat-file data for Splunk. Notice how relatively inconvenient that was without this new tie-in.
Here, we sorted the raw data file by state, pseudonymised the last name column, partially redacted the Credit Card Number, and protected the NID value in the last column with an AES-256 format preserving encryption (FPE) algorithm. With the new plug-in, Splunk ingests the output of that IRI job automatically, and indexes it on the fly.
Step-by-Step
We included a sample data set and IRI job script to use in this tutorial. You must have an IRI CoSort or Voracity license that can run SortCL job scripts, and the free Splunk add-on pack from IRI to do the same.
1. Copy the provided SortCL script (splunk1.scl) and the provided data file, Name-City-State-CCNumber-SSN-Random-short.csv into the same folder
2. Inside splunk1.scl, ensure the /INFILE command points to the absolute location of that CSV file; e.g.,
/INFILE=C:\Name-City-State-CCNumber-SSN-Random-short.csv
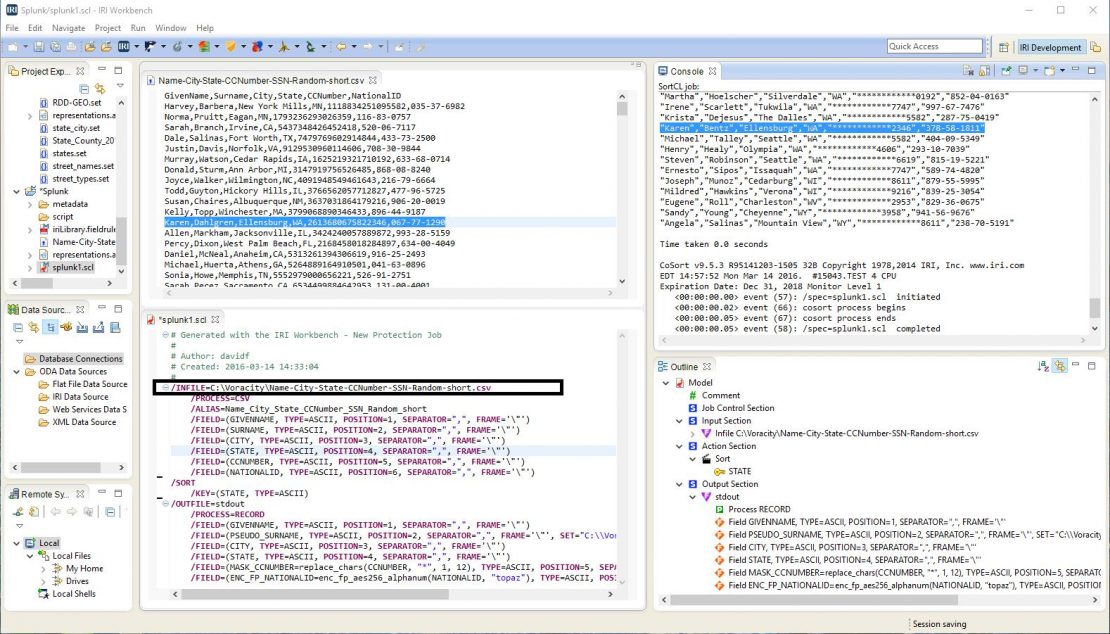
The IRI Workbench GUI for Voracity, showing a simple CoSort SortCL job script that pre-sorts and masks data going into Splunk. The GUI allows you to hand-code the jobs (in the color-coded syntax-aware editor) , or create them automatically in end-to-end wizards, a visual ETL workflow design palette, or an optional plug-in from AnalytiX DS called Mapping Manager.
3. Inside Splunk Settings -> Data Inputs -> IRI Voracity, click “add new”
In the Data Input list, enter the name you want to give the dataset, and the full path to the IRI job script; e.g.,C:\IRI\CoSort95\myjobs\splunk1.scl.
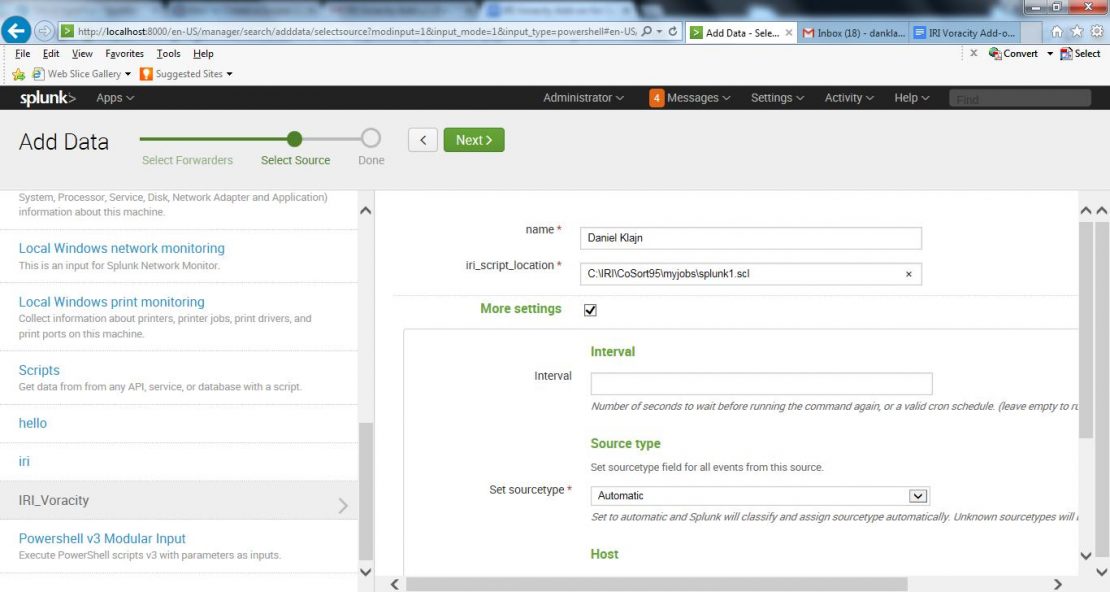
Data input settings in the IRI Voracity Add-on for Splunk
5. Splunk will now add this data input to its watch list and will index it once, and then again anytime data is changed or the system is re-started. With each new IRI_Voracity dashboard data source and job script you define, you can prepare, search, and visualize more data in more ways.
Below is Voracity output that was pumped into Splunk by this process:
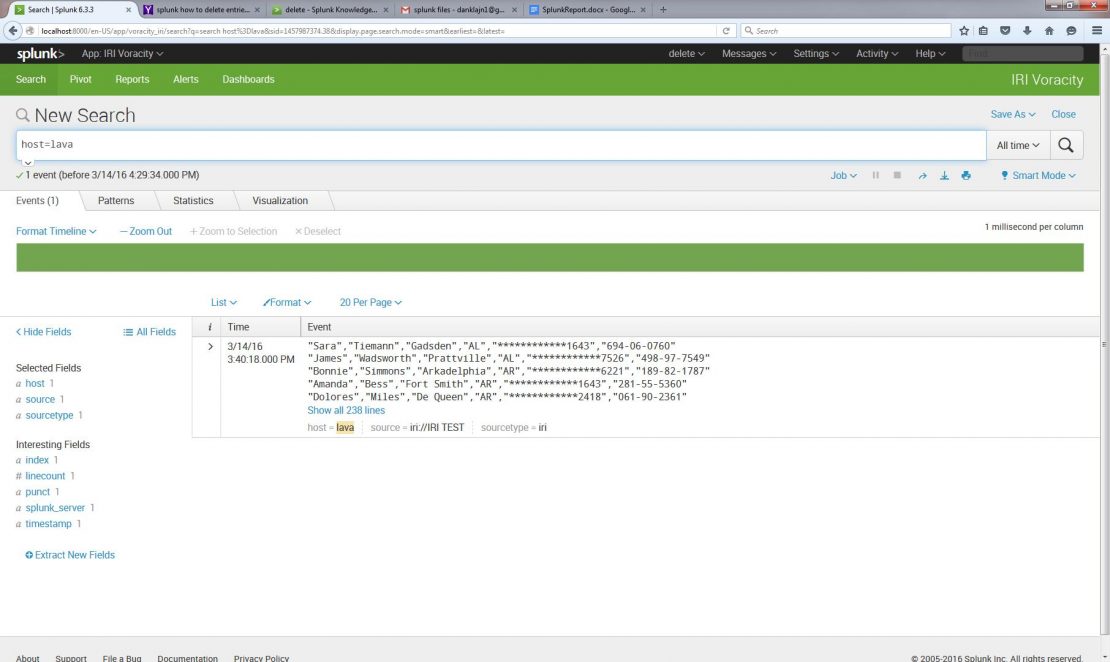
As you can see by the highlighted entry below, which matches what was done in Voracity, the newly prepared data was automatically indexed and is now safe and ready for analysis in Splunk.
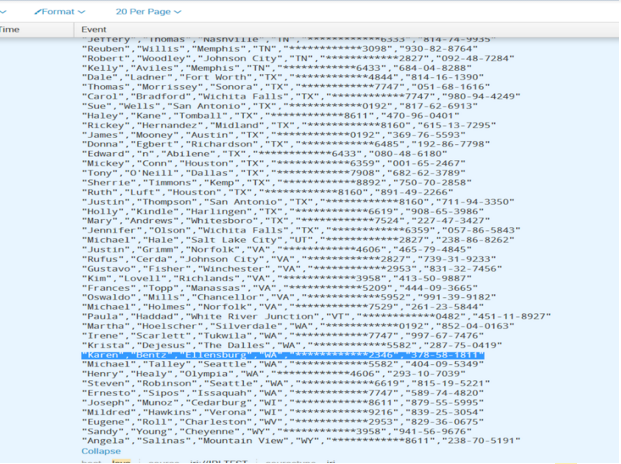
Now, running Voracity from Splunk is much easier. The add-on creates new performance and ergonomic value for users who need safe, reliable analytic data culled from structured, semi-structured, and unstructured sources.
For more information on the interaction between IRI software and Splunk, e-mail voracity@iri.com, or submit your comments below.










