AI
AI
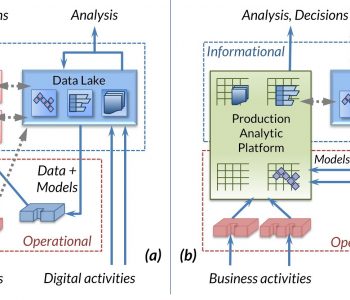
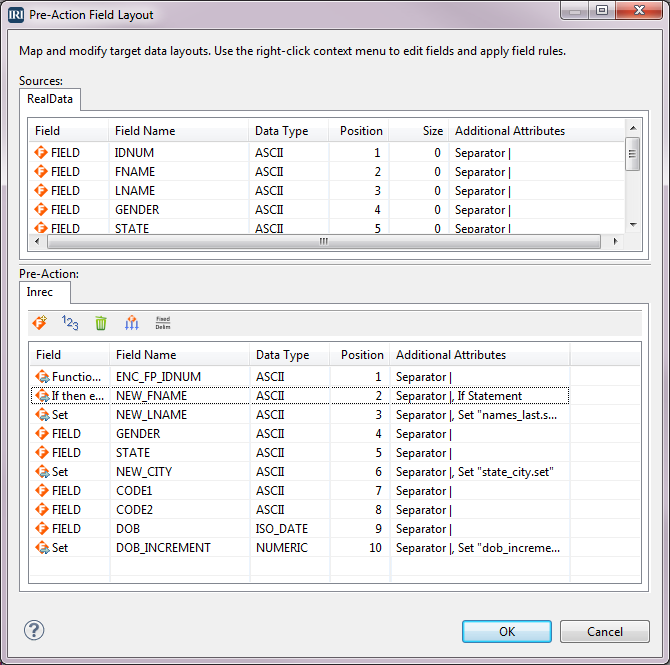
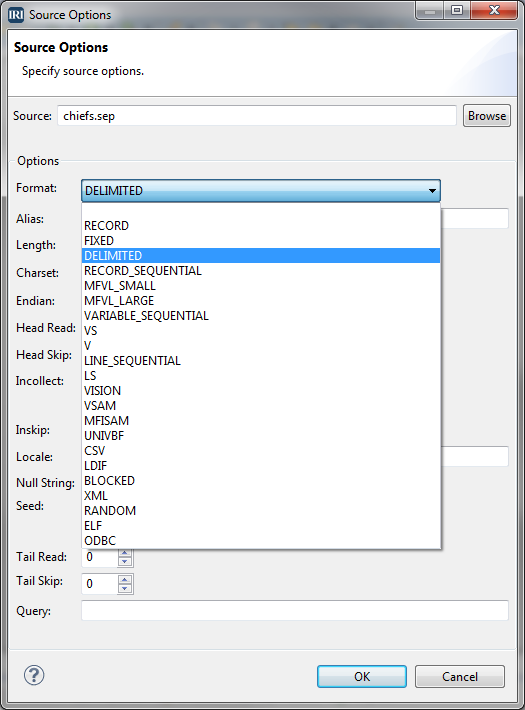
Test Data Generation for AI Pipelines
AI and machine learning are only as good as the data that fuel and teach them. Whether you’re building models for predictive analytics, computer vision, or natural language processing, the importance of high-quality, representative data can’t be overstated. Read More