Using IRI Workbench with ASN.1-Encoded Data
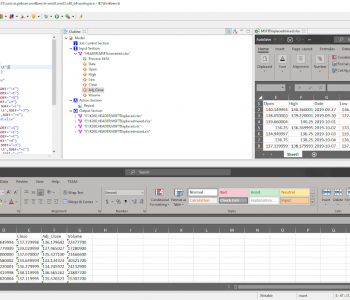
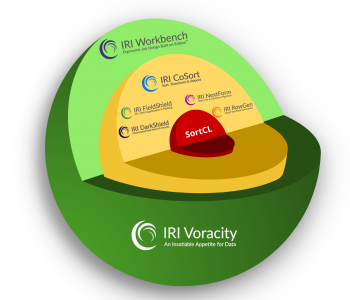
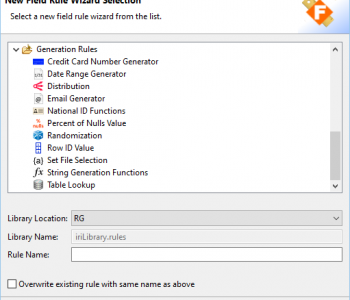
In part 4 of this five-part series regarding newly added ASN.1 support in the SortCL program central to the IRI Voracity data management platform and its component structured data processing products — IRI CoSort, NextForm, FieldShield, and RowGen — we take a look specifically at their common graphical user interface (GUI) for job design, IRI Workbench. Read More