Using IRI Workbench with ASN.1-Encoded Data
In part 4 of this five-part series regarding newly added ASN.1 support in the SortCL program central to the IRI Voracity data management platform and its component structured data processing products — IRI CoSort, NextForm, FieldShield, and RowGen — we take a look specifically at their common graphical user interface (GUI) for job design, IRI Workbench.
IRI Workbench is an intuitive Integrated Development Environment (IDE) for Voracity operations, built on EclipseTM. It is used to auto-create and ergonomically manage all structured data acquisition, discovery, and processing jobs that serialize in SortCL job scripts. These scripts that, when run, direct how the SortCL program manipulates and maps data in ASN.1 files and other sources.
Workbench images
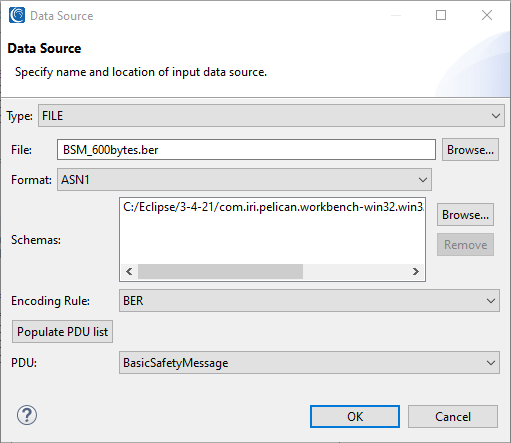 Image displaying options available to choose from in IRI Workbench when selecting an ASN.1 encoded file as a source or target.
Image displaying options available to choose from in IRI Workbench when selecting an ASN.1 encoded file as a source or target.
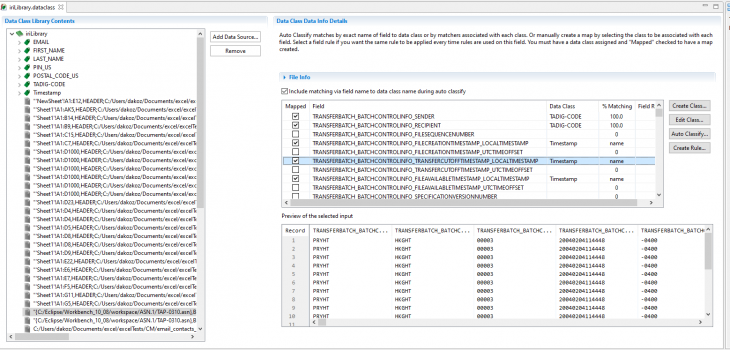
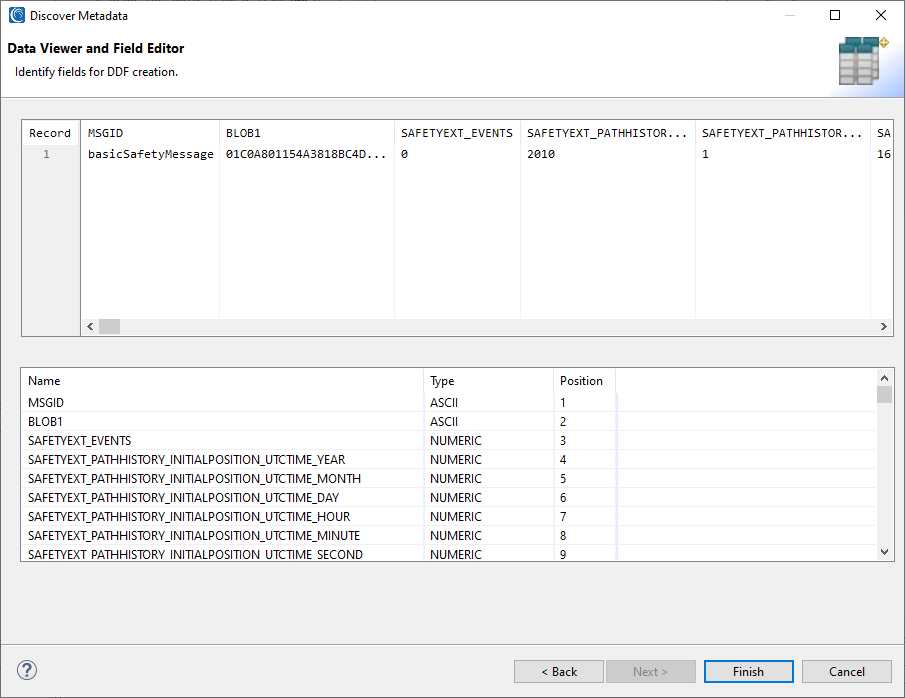 Image displaying preview of a BER encoded message containing a single record in IRI Workbench. Fields have been flattened and mapped to a SortCL script.
Image displaying preview of a BER encoded message containing a single record in IRI Workbench. Fields have been flattened and mapped to a SortCL script.
ASN.1 Metadata Discovery
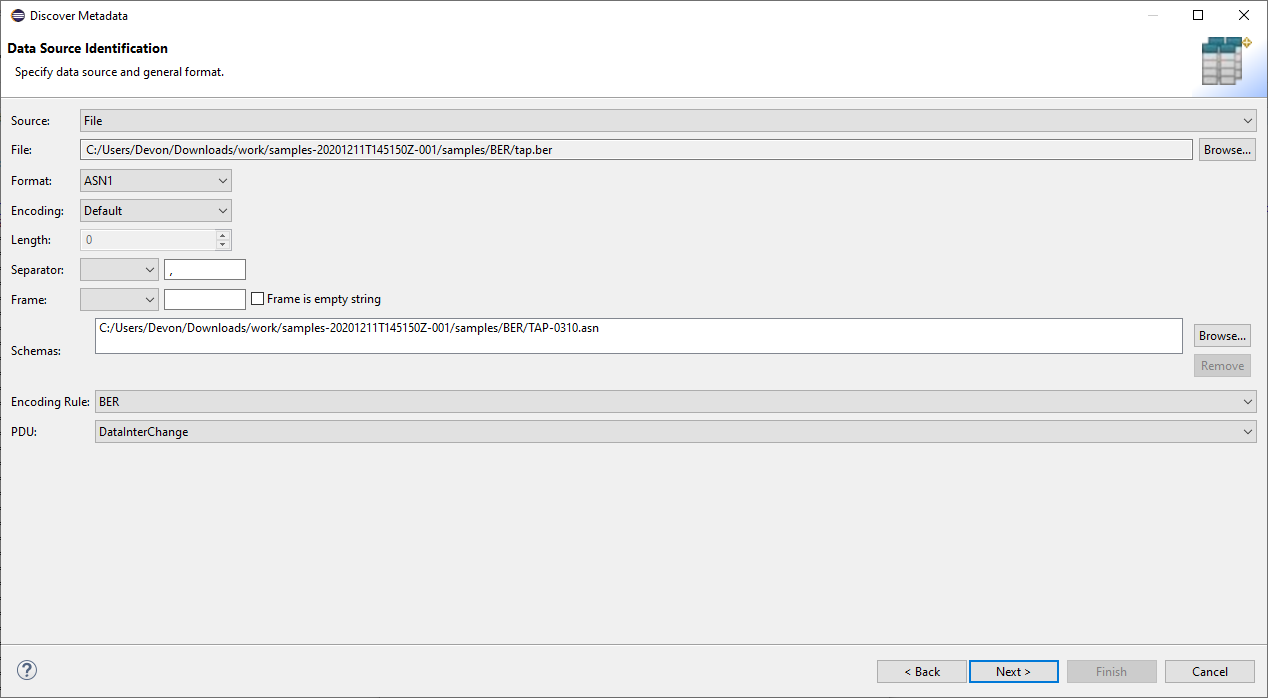
This is an image demonstrating using the discover metadata wizard to generate metadata for an ASN.1 encoded file. Getting metadata is a crucial part of being able to map fields in an ASN.1 schema to fields for a SortCL script. Once the metadata has been created, it is reusable as long as the ASN.1 schema stays the same. Any number of operations can be performed based on this metadata – generating realistic ASN.1 encoded files as test data, masking personal information that may be in the data, reformatting to a more readable format, etc.
To begin with, when selecting an input file that is an ASN.1 encoded file, the process type must be selected to be ASN1. The path to at least one ASN.1 schema file must be selected. If the schema file depends on another schema file, all dependent schema files must be selected. From that, a list of the PDUs contained in that schema will be available to select from. In this example with a TAP3 schema, there is only one PDU that references all other types. Its name is DataInterChange.
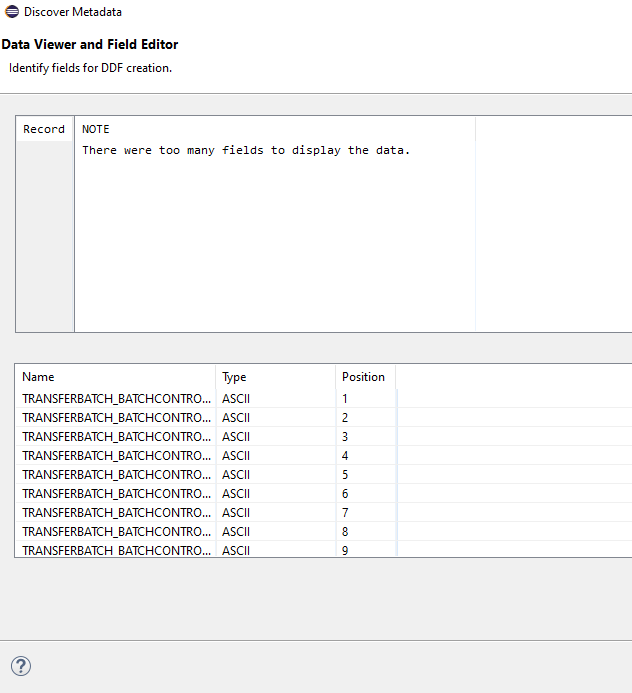
Discover metadata shows all the fields that the PDU flattens out into. This TAP3 schema flattens out into 848 fields, too many for the wizard to display in the data preview.
The final output has the entire flattened field structure of the ASN.1 schema. The separator will be generated as a comma and should not be modified for any infile specifying /PROCESS=ASN1, due to how it is processed internally.
Data Classification
Data in ASN.1 encoded files can be classified in IRI Workbench, and then rules may be applied based on what the matching data class was. This is useful for masking sensitive data, but not limited in scope to that use case. There are quite a few other types of data manipulations or field functions available that may be performed based on a rule.
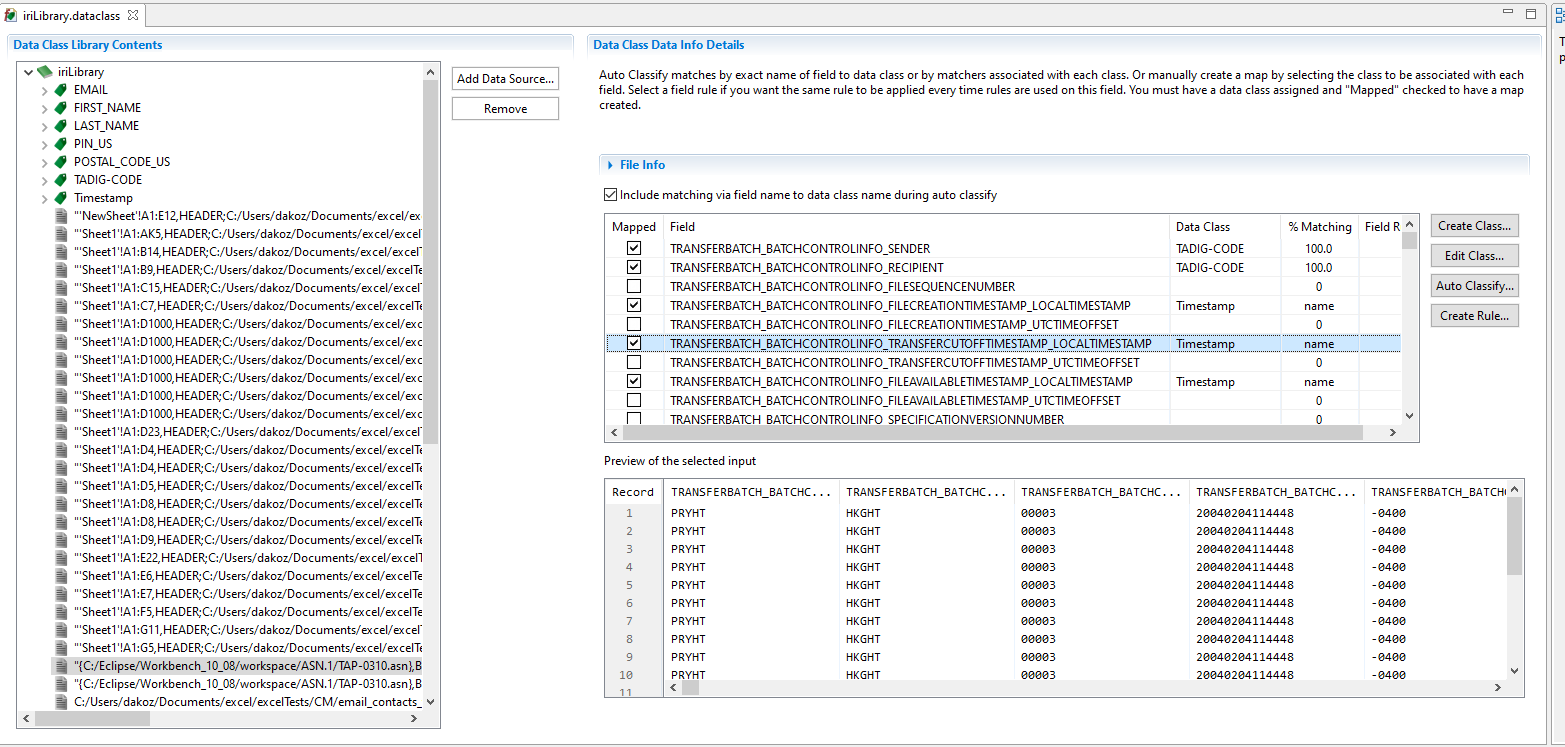
IRI Workbench offers a user-friendly and intuitive interface for discovering data, generating data manipulation job scripts, and ultimately producing the target data using the powerful SortCL data mapping engine. To wrap up this series on ASN.1 support in IRI products, a use case of creating a human-readable report filtered from an input file with many BER-encoded messages based on the TAP3 schema will be shown.
Other articles in this series:
- Introduction to ASN.1
- ASN.1 Integration with SortCL
- SortCL ASN.1 Examples
- Gaining insight from Call Detail Records










