
Data Class & Rule Library in IRI Workbench
Abstract: HIPAA, GDPR, FERPA, and other data privacy laws require that personally identifiable information (PII) and related data considered sensitive be protected from disclosure or discovery. Read More
Abstract: HIPAA, GDPR, FERPA, and other data privacy laws require that personally identifiable information (PII) and related data considered sensitive be protected from disclosure or discovery. Read More

As I’m finding myself noting more and more frequently this year, AI, and especially generative AI or “GAI”, is the new darling of the tech world, to the point that it has even captured the attention and interest of the general public (albeit not always positively). Read More

When it comes to protecting your data, there are two processes that could be considered absolutely fundamental: finding out which of your data is sensitive and where it can be located, and then actually protecting that data. Read More
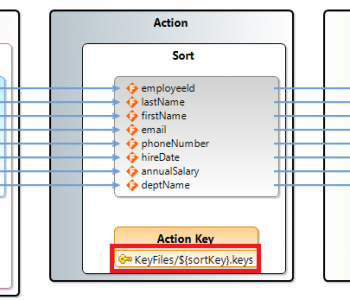
Designing for reuse is a common cost-saving technique used in the software industry that can be applied to IRI SortCL (Sort Control Language)-compatible job design. Designing for reuse can result in a smaller inventory of scripts; and reduce script development, maintenance and execution costs. Read More
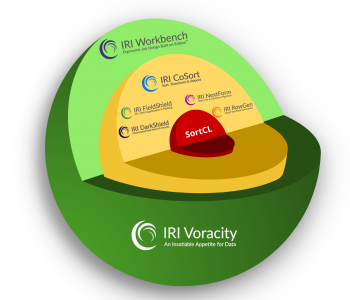
The names of IRI software products and how they run have at times been a source of mystery, or even confusion, to the uninitiated. This article spells out the pieces and clarifies their interplay, providing a quick primer for prospective users, partners, and new industry analysts. Read More

Since the advent of automatic tuning in CoSort V10, it has been easier to work with the many available performance settings in CoSort Resource Control (which we call cosortrc or “RC”) files. Read More
KNIME is a leading open source analytic and visualization tool for data scientists. Wrangling raw data for KNIME projects is usually done via their intermediate file node, database connectors, or other extensions like Spark. Read More

Connecting to and working with data in cloud data warehouse powered by an AWS Snowflake database from the IRI Workbench IDE is no different than with an on-premise SQL-compatible source. Read More

“Have you stopped speeding?” You could probably object to a leading question like this in court, but what happens when an important question with only a yes or no answer is solicited on a mandatory form, and the response becomes part of an actionable database record? Read More
This is part 4 of a 4-part series on Production Analytics. Processing on Par with Information [Part 1] Data Processing Drives Efficiency [Part 2] Processing Real World Data [Part 3]
In this final article of the series covering the Production Analytic Platform paradigm, we look at data virtualization—a key requirement in today’s multi-source, data-overloaded world. Read More

This is part 3 of a 4-part series on Production Analytics. Processing on Par with Information [Part 1] Data Processing Drives Efficiency [Part 2] Unifying the Worlds of Information and Processing [Part 4]
The inclusion of full function data processing in the Production Analytic Platform simplifies the task of gathering data from external sources such as the Internet of Things and clickstream data that requires both intensive exploratory modeling as well as high-speed application and maintenance of those models on real-time and streaming data. Read More