
Working Towards Data Quality
{kind=link}
Introduction
In this article, I suggest ways to move your company’s data towards a higher state of quality. The highest quality occurs when the data meets the needs of your company. Read More
Introduction
In this article, I suggest ways to move your company’s data towards a higher state of quality. The highest quality occurs when the data meets the needs of your company. Read More

Job schedulers are computer programs controlling other program executions behind the scenes, or as part of batch processes. This workload automation is typically coordinated so that traditional background data processing can be integrated with real-time business activities without depleting resources or interfering with other applications. Read More
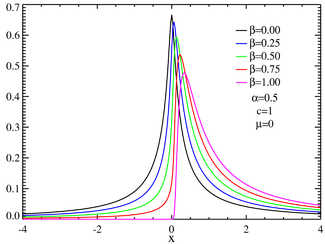
This article is part of a 4-step series introduced here. Navigation between articles is below.
Step 2: Test Data Needs Assessment
Once the questions of who needs test data for what — and who will be dealing with it along its lifecycle are answered (see Step 1) — a deeper dive is needed into the specific technical aspects of the data itself. Read More

Imagine it’s time to write a headline for your blog article. You just spent hours drafting, in your opinion, a masterpiece. You selected a great keyword or two as the basis of your subject and compiled some great content to make that keyword shine. Read More
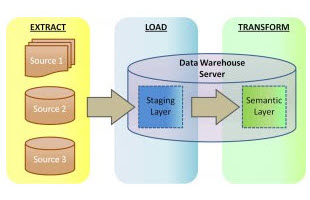
Full disclosure: As this article is authored by an ETL-centric company with its strong suit in manipulating big data outside of databases, what follows will not seem objective to many. Read More

Abstract: This article explains a method of protecting credit card data with tokenization using the IRI FieldShield data masking tool.
Submitting one’s credit card details electronically can be disconcerting (e.g., Read More

Data profiling, or data discovery, refers to the process of obtaining information from, and descriptive statistics about, various sources of data. The purpose of data profiling is to get a better understanding of the content of data, as well as its structure, relationships, and current levels of accuracy and integrity. Read More

Note: This article was originally drafted in 2015, but was updated in 2019 to reflect new integration between IRI Voracity and Knime (for Konstanz Information Miner), now the most powerful open source data mining platform available. Read More
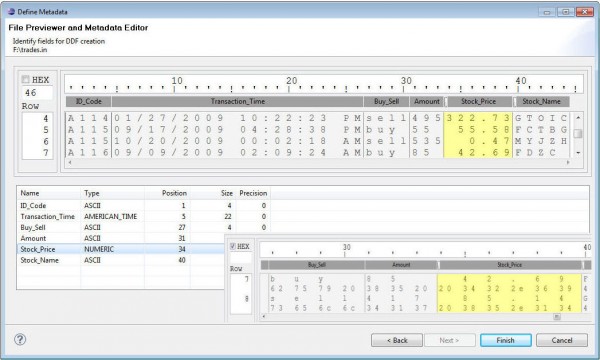
IRI’s data management tools share a familiar and self-documenting metadata language called SortCL. All these tools — including CoSort, FieldShield, NextForm, and RowGen — require data definition file (DDF) layouts with /FIELD specifications for each data source so you can map your data and manage your metadata. Read More

A test data generator is an important part of the setup process for DevOps and data architects prototyping database and data warehouse operations, testing applications, benchmarking different platforms, and outsourcing work formats. Read More
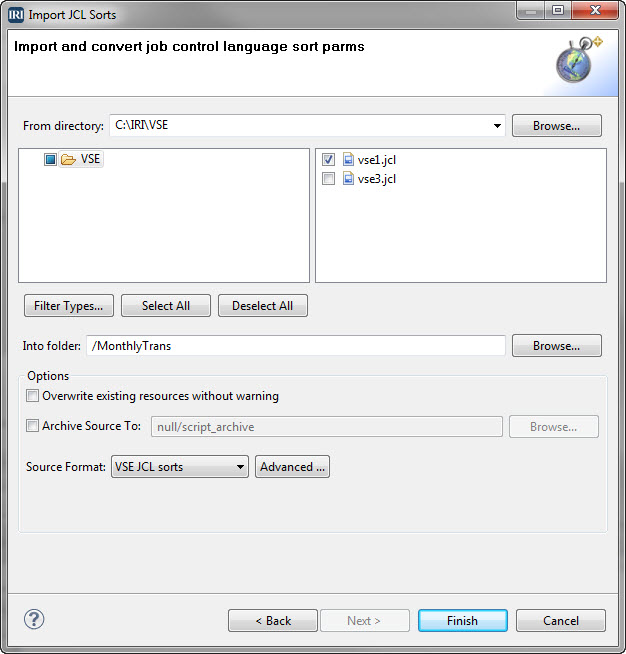
VSE, short for Virtual Storage Extended, is an operating system for IBM mainframe computers. Programs scripted in its job control language (JCL) instruct the system in how to run batch jobs or start subsystems. Read More