ETL vs ELT: We Posit, You Judge
Full disclosure: As this article is authored by an ETL-centric company with its strong suit in manipulating big data outside of databases, what follows will not seem objective to many. Nevertheless it is still meant to present food for thought, and opens the floor to discussion.
Since their beginnings, data warehouse architects (DWA) have been tasked with creating and populating a data warehouse with disparately sourced and formatted data. Due to dramatic growth in data volumes, these same DWAs are challenged to implement their data integration and staging operations more efficiently. The question of whether data transformation will occur inside or outside the target database has become a critical one because of the performance, convenience, and financial consequences involved.
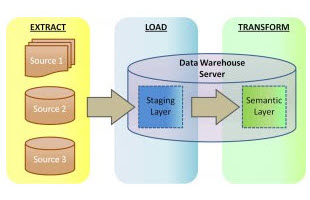
In ETL (extract, transform, load) operations, data are extracted from different sources, transformed separately, and loaded to a DW database and possibly other targets. In ELT, the extracts are fed into the single staging database that also handles the transformations.
ETL remains prevalent because the marketplace flourishes with proven players like Informatica, IBM, Oracle — and IRI with Voracity, which combines FACT (Fast Extract), CoSort or Hadoop transforms, and bulk loading in the same Eclipse GUI — to extract and transform data. This approach prevents burdening databases designed for storage and retrieval (query optimization) with the overhead of large-scale data transformation.

However, with the development of new database technology and hardware appliances like Oracle Exadata that can handle transformations ‘in a box’, ELT may be a practical solution under certain circumstances. And there are specific benefits to isolating the staging (load) and semantic (transform) layers.

A cited advantage of ELT is the isolation of the load process from the transformation process, since it removes an inherent dependency between these stages.
We note that IRI’s ETL approach isolates them anyway because Voracity stages data in the file system (or HDFS). Any data chunk bound for the database can be acquired, cleansed, and transformed externally prior to a (pre-sorted) load. This takes the burden of large scale transforms off the database (as well as BI/analytic tools, etc.).
Data volumes and budgets are often what determines whether a DWA should develop a ETL or ELT solution. In his ITToolbox blog article “So What Is Better, ETL or ELT?”, Vincent McBurney posits his pros and cons to either approach, which I’ve repeated here below, and then followed each with a typical response that IRI ETL-oriented users make on point (per my initial subjectivity caveat):
Pros ETL
- ETL can balance the workload and share the workload with the RDBMS – and in fact remove that workload by transforming data via SortCL program or Hadoop without coding in Voracity
- ETL can perform more complex operations in single data flow diagrams via data maps – like with Voracity mapping and workflow diagrams that also abstract short, open 4GL scripts vs. SQL
- ETL can scale with separate hardware – on commodity boxes you can source and maintain yourself at much lower costs than single-vendor appliances
- ETL can handle partitioning and parallelism independent of the data model, database layout, and source data model architecture – though Voracity’s CoSort SortCL jobs needn’t be partitioned at all …
- ETL can process data in-stream, as it transfers from source to target – or in batch if that makes sense, too
- ETL does not require co-location of data sets in order to do it’s work – allowing you to maintain existing data source platforms without data synchronization worries
- ETL captures huge amounts of metadata lineage today- how well or intuitively can one staging DB do that?
- ETL can run on SMP or MPP hardware – which again you can manage and exploit more cost-effectively, and not worry about performance contention with the DB
- ETL processes information row-by-row and that seems to work well with data integration into third party products – better still though is full block, table, or file(s)-at-a-time, which Voracity runs in volume.
Cons ETL
- Additional hardware investment is needed for ETL engines – unless you run it on the database server(s)
- Extra cost of building ETL system or licensing ETL tools – which are still cheaper relative to ELT appliances, but cheaper still are IRI tools like Voracity which combine Fast Extract (FACT) and CoSort to speed ETL without such complexity
- Possible reduced performance of row-based approach – right, and why Voracity’s ability to profile, acquire, transform, and output data in larger chunks is faster
- Specialized skills and learning curve required for implementing the ETL tool – unless you’re using an ergonomic GUI like Voracity’s which provides multiple job design options in the same Eclipse IDE
- Reduced flexibility due to dependency on ETL tool vendor – I’m not sure how that’s improved by relying on a single ELT/appliance vendor instead; isn’t vendor-independence the key to flexibility and cost savings?
- Data needs to travel across one more layer before it lands into data mart – unless the mart were just another output of the ETL process, typical of multi-target Voracity operations.
Pros ELT
- ELT leverages RDBMS engine hardware for scalability – but also taxes DB resources meant for query optimization. CoSort and Hadoop transformations in Voracity leverage linearly scaling algorithms and task consolidation, not the memory or I/O resources of the DB
- ELT keeps all data in the RDBMS all the time – which is fine as long as source and target data are in the same DB
- ELT is parallelized according to the data set, and disk I/O is usually optimized at the engine level for faster throughput – yes, but that’s even truer of external transforms that don’t contend with DB server resources
- ELT scales as long as the hardware and RDBMS engine can continue to scale – which costs how much relative to the alternative above?
- ELT can achieve 3x to 4x the throughput rates on the appropriately tuned MPP RDBMS platform – which puts the appliance at Voracity performance levels relative to ETL tools, too, but at 20 times the cost.
- ELT transformation is done on the RDBMS server once the database is on the target platform and it no longer places stress on the network – so it puts the stress on the database (users) instead?
- ELT has simple transformation specifications via SQL – which are not as simple, flexible, or as feature-rich as CoSort SortCL syntax or drag-and-drop field mapping in Voracity’s Eclipse GUI.
Cons ELT
- Limited tools available with full support for ELT – and at very high prices for DB appliances touting high-volume performance
- Loss of detailed run-time monitoring statistics and data lineage – especially metadata impact analyses on changes to disparate file, table, or unstructured sources
- Loss of modularity due to set based design for performance – and the loss of functionality/flexibility flowing from it
- Transformations would utilize Database resources, potentially impacting BI-reporting performance – not to mention the performance of query and other DB operations
Hybrid architectures like ETLT, TELT and even TETLT are subsequently emerging in an attempt to shore up weaknesses in either approach. But these seem to add additional levels of complexity to processes already thus fraught. There really isn’t any silver bullet, and many data integration projects fail under the weight of SLAs, cost overruns, and complexity.
It is for these reasons that IRI built Voracity to integrate data via the CoSort SortCL program in existing file systems or Hadoop fabrics without re-coding. Voracity is the only ETL-oriented (though also ELT-supporting) platform that offers both options for external data transformations. In addition to superior price-performance in data movement and manipulation, Voracity includes:
- advanced data transformation, data quality, MDM, and reporting
- slowly changing dimensions, change data capture, data federation
- data profiling, data masking, test data generation, and metadata management
- simple 4GL scripts you or Eclipse wizards, diagrams, and dialogs create and manage
- seamless execution in Hadoop MR2, Spark, Spart Stream Storm and Tez
- support for erwin Smart Connectors (conversion from other ETL tools)
- native MongoDB drivers and connections to other NoSQL, Hadoop, cloud, and legacy sources
- embedded reporting, stats, and predictive functions, KNIME and Splunk tie-ins, and analytic tool data feeds.
See also:










